 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhangsihao Yang
OmniMotionGPT: Animal Motion Generation with Limited Data
Nov 30, 2023
Our paper aims to generate diverse and realistic animal motion sequences from textual descriptions, without a large-scale animal text-motion dataset. While the task of text-driven human motion synthesis is already extensively studied and benchmarked, it remains challenging to transfer this success to other skeleton structures with limited data. In this work, we design a model architecture that imitates Generative Pretraining Transformer (GPT), utilizing prior knowledge learned from human data to the animal domain. We jointly train motion autoencoders for both animal and human motions and at the same time optimize through the similarity scores among human motion encoding, animal motion encoding, and text CLIP embedding. Presenting the first solution to this problem, we are able to generate animal motions with high diversity and fidelity, quantitatively and qualitatively outperforming the results of training human motion generation baselines on animal data. Additionally, we introduce AnimalML3D, the first text-animal motion dataset with 1240 animation sequences spanning 36 different animal identities. We hope this dataset would mediate the data scarcity problem in text-driven animal motion generation, providing a new playground for the research community.
Keypoint-Augmented Self-Supervised Learning for Medical Image Segmentation with Limited Annotation
Oct 18, 2023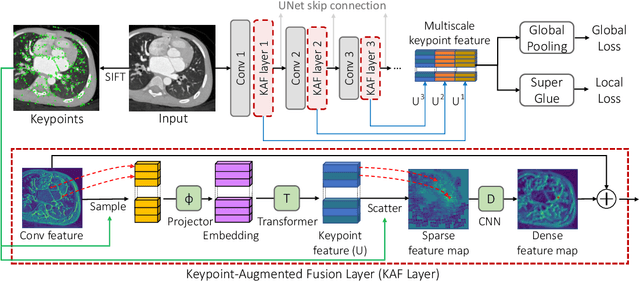
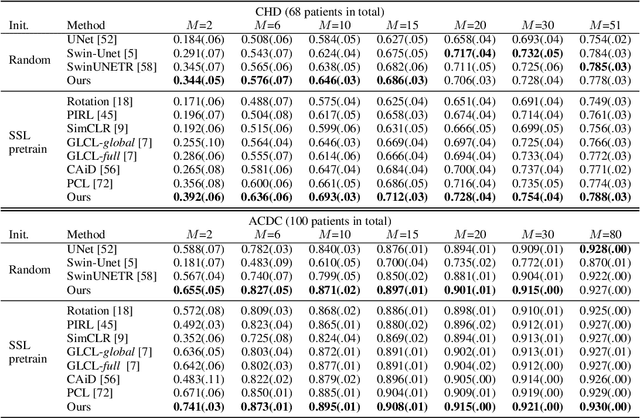
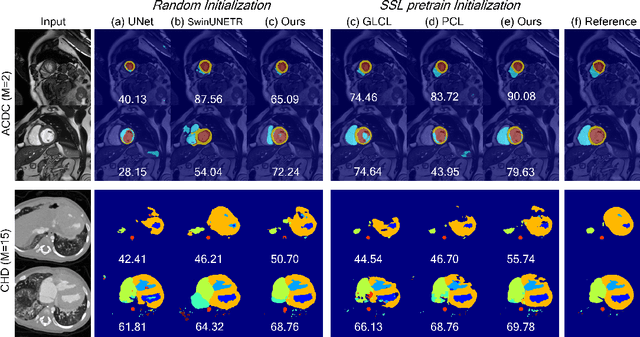
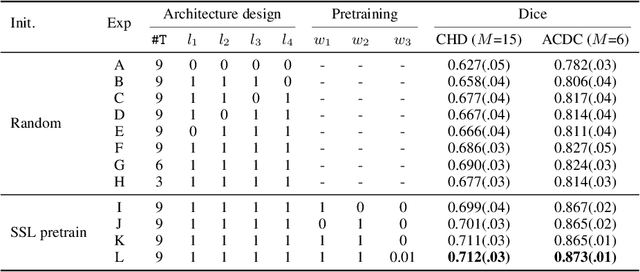
Pretraining CNN models (i.e., UNet) through self-supervision has become a powerful approach to facilitate medical image segmentation under low annotation regimes. Recent contrastive learning methods encourage similar global representations when the same image undergoes different transformations, or enforce invariance across different image/patch features that are intrinsically correlated. However, CNN-extracted global and local features are limited in capturing long-range spatial dependencies that are essential in biological anatomy. To this end, we present a keypoint-augmented fusion layer that extracts representations preserving both short- and long-range self-attention. In particular, we augment the CNN feature map at multiple scales by incorporating an additional input that learns long-range spatial self-attention among localized keypoint features. Further, we introduce both global and local self-supervised pretraining for the framework. At the global scale, we obtain global representations from both the bottleneck of the UNet, and by aggregating multiscale keypoint features. These global features are subsequently regularized through image-level contrastive objectives. At the local scale, we define a distance-based criterion to first establish correspondences among keypoints and encourage similarity between their features. Through extensive experiments on both MRI and CT segmentation tasks, we demonstrate the architectural advantages of our proposed method in comparison to both CNN and Transformer-based UNets, when all architectures are trained with randomly initialized weights. With our proposed pretraining strategy, our method further outperforms existing SSL methods by producing more robust self-attention and achieving state-of-the-art segmentation results. The code is available at https://github.com/zshyang/kaf.git.
Envisioning a Next Generation Extended Reality Conferencing System with Efficient Photorealistic Human Rendering
Jun 28, 2023



Meeting online is becoming the new normal. Creating an immersive experience for online meetings is a necessity towards more diverse and seamless environments. Efficient photorealistic rendering of human 3D dynamics is the core of immersive meetings. Current popular applications achieve real-time conferencing but fall short in delivering photorealistic human dynamics, either due to limited 2D space or the use of avatars that lack realistic interactions between participants. Recent advances in neural rendering, such as the Neural Radiance Field (NeRF), offer the potential for greater realism in metaverse meetings. However, the slow rendering speed of NeRF poses challenges for real-time conferencing. We envision a pipeline for a future extended reality metaverse conferencing system that leverages monocular video acquisition and free-viewpoint synthesis to enhance data and hardware efficiency. Towards an immersive conferencing experience, we explore an accelerated NeRF-based free-viewpoint synthesis algorithm for rendering photorealistic human dynamics more efficiently. We show that our algorithm achieves comparable rendering quality while performing training and inference 44.5% and 213% faster than state-of-the-art methods, respectively. Our exploration provides a design basis for constructing metaverse conferencing systems that can handle complex application scenarios, including dynamic scene relighting with customized themes and multi-user conferencing that harmonizes real-world people into an extended world.
TetCNN: Convolutional Neural Networks on Tetrahedral Meshes
Feb 14, 2023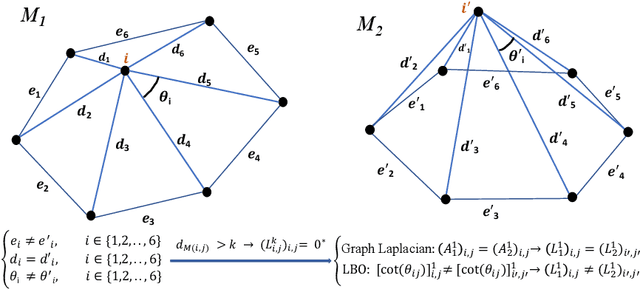
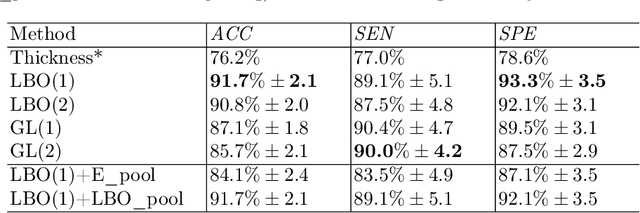
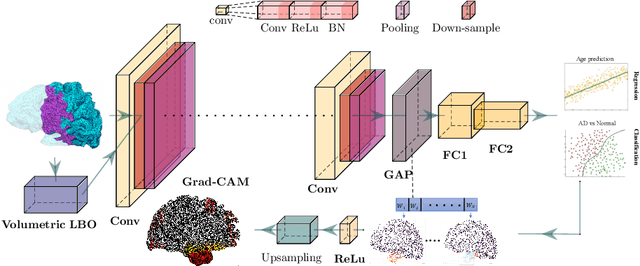
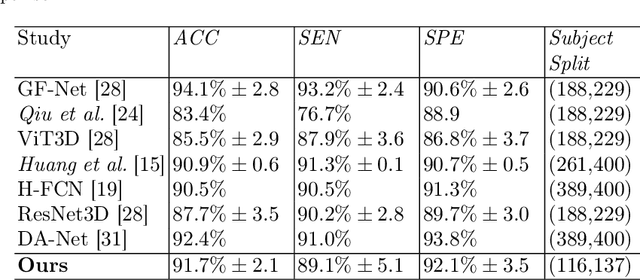
Convolutional neural networks (CNN) have been broadly studied on images, videos, graphs, and triangular meshes. However, it has seldom been studied on tetrahedral meshes. Given the merits of using volumetric meshes in applications like brain image analysis, we introduce a novel interpretable graph CNN framework for the tetrahedral mesh structure. Inspired by ChebyNet, our model exploits the volumetric Laplace-Beltrami Operator (LBO) to define filters over commonly used graph Laplacian which lacks the Riemannian metric information of 3D manifolds. For pooling adaptation, we introduce new objective functions for localized minimum cuts in the Graclus algorithm based on the LBO. We employ a piece-wise constant approximation scheme that uses the clustering assignment matrix to estimate the LBO on sampled meshes after each pooling. Finally, adapting the Gradient-weighted Class Activation Mapping algorithm for tetrahedral meshes, we use the obtained heatmaps to visualize discovered regions-of-interest as biomarkers. We demonstrate the effectiveness of our model on cortical tetrahedral meshes from patients with Alzheimer's disease, as there is scientific evidence showing the correlation of cortical thickness to neurodegenerative disease progression. Our results show the superiority of our LBO-based convolution layer and adapted pooling over the conventionally used unitary cortical thickness, graph Laplacian, and point cloud representation.
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 09, 2023



Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the Optimal Transport (OT) theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as regularization by enhancing (RE). We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
Anisotropic Multi-Scale Graph Convolutional Network for Dense Shape Correspondence
Oct 17, 2022



This paper studies 3D dense shape correspondence, a key shape analysis application in computer vision and graphics. We introduce a novel hybrid geometric deep learning-based model that learns geometrically meaningful and discretization-independent features with a U-Net model as the primary node feature extraction module, followed by a successive spectral-based graph convolutional network. To create a diverse set of filters, we use anisotropic wavelet basis filters, being sensitive to both different directions and band-passes. This filter set overcomes the over-smoothing behavior of conventional graph neural networks. To further improve the model's performance, we add a function that perturbs the feature maps in the last layer ahead of fully connected layers, forcing the network to learn more discriminative features overall. The resulting correspondence maps show state-of-the-art performance on the benchmark datasets based on average geodesic errors and superior robustness to discretization in 3D meshes. Our approach provides new insights and practical solutions to the dense shape correspondence research.
Continuous Geodesic Convolutions for Learning on 3D Shapes
Feb 06, 2020



The majority of descriptor-based methods for geometric processing of non-rigid shape rely on hand-crafted descriptors. Recently, learning-based techniques have been shown effective, achieving state-of-the-art results in a variety of tasks. Yet, even though these methods can in principle work directly on raw data, most methods still rely on hand-crafted descriptors at the input layer. In this work, we wish to challenge this practice and use a neural network to learn descriptors directly from the raw mesh. To this end, we introduce two modules into our neural architecture. The first is a local reference frame (LRF) used to explicitly make the features invariant to rigid transformations. The second is continuous convolution kernels that provide robustness to sampling. We show the efficacy of our proposed network in learning on raw meshes using two cornerstone tasks: shape matching, and human body parts segmentation. Our results show superior results over baseline methods that use hand-crafted descriptors.
3D Shape Synthesis for Conceptual Design and Optimization Using Variational Autoencoders
Apr 16, 2019



We propose a data-driven 3D shape design method that can learn a generative model from a corpus of existing designs, and use this model to produce a wide range of new designs. The approach learns an encoding of the samples in the training corpus using an unsupervised variational autoencoder-decoder architecture, without the need for an explicit parametric representation of the original designs. To facilitate the generation of smooth final surfaces, we develop a 3D shape representation based on a distance transformation of the original 3D data, rather than using the commonly utilized binary voxel representation. Once established, the generator maps the latent space representations to the high-dimensional distance transformation fields, which are then automatically surfaced to produce 3D representations amenable to physics simulations or other objective function evaluation modules. We demonstrate our approach for the computational design of gliders that are optimized to attain prescribed performance scores. Our results show that when combined with genetic optimization, the proposed approach can generate a rich set of candidate concept designs that achieve prescribed functional goals, even when the original dataset has only a few or no solutions that achieve these goals.
3D Conceptual Design Using Deep Learning
Aug 05, 2018



This article proposes a data-driven methodology to achieve a fast design support, in order to generate or develop novel designs covering multiple object categories. This methodology implements two state-of-the-art Variational Autoencoder dealing with 3D model data. Our methodology constructs a self-defined loss function. The loss function, containing the outputs of certain layers in the autoencoder, obtains combination of different latent features from different 3D model categories. Additionally, this article provide detail explanation to utilize the Princeton ModelNet40 database, a comprehensive clean collection of 3D CAD models for objects. After convert the original 3D mesh file to voxel and point cloud data type, we enable to feed our autoencoder with data of the same size of dimension. The novelty of this work is to leverage the power of deep learning methods as an efficient latent feature extractor to explore unknown designing areas. Through this project, we expect the output can show a clear and smooth interpretation of model from different categories to develop a fast design support to generate novel shapes. This final report will explore 1) the theoretical ideas, 2) the progresses to implement Variantional Autoencoder to attain implicit features from input shapes, 3) the results of output shapes during training in selected domains of both 3D voxel data and 3D point cloud data, and 4) our conclusion and future work to achieve the more outstanding goal.
Data-driven Upsampling of Point Clouds
Jul 08, 2018



High quality upsampling of sparse 3D point clouds is critically useful for a wide range of geometric operations such as reconstruction, rendering, meshing, and analysis. In this paper, we propose a data-driven algorithm that enables an upsampling of 3D point clouds without the need for hard-coded rules. Our approach uses a deep network with Chamfer distance as the loss function, capable of learning the latent features in point clouds belonging to different object categories. We evaluate our algorithm across different amplification factors, with upsampling learned and performed on objects belonging to the same category as well as different categories. We also explore the desirable characteristics of input point clouds as a function of the distribution of the point samples. Finally, we demonstrate the performance of our algorithm in single-category training versus multi-category training scenarios. The final proposed model is compared against a baseline, optimization-based upsampling method. Results indicate that our algorithm is capable of generating more uniform and accurate upsamplings.