 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhao Kang
CDC: A Simple Framework for Complex Data Clustering
Mar 06, 2024
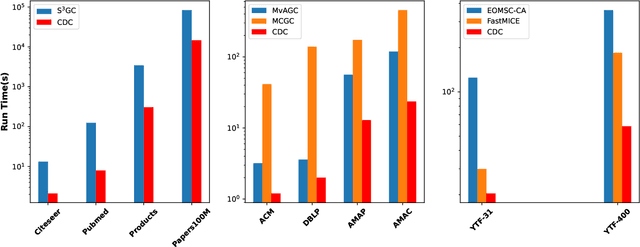
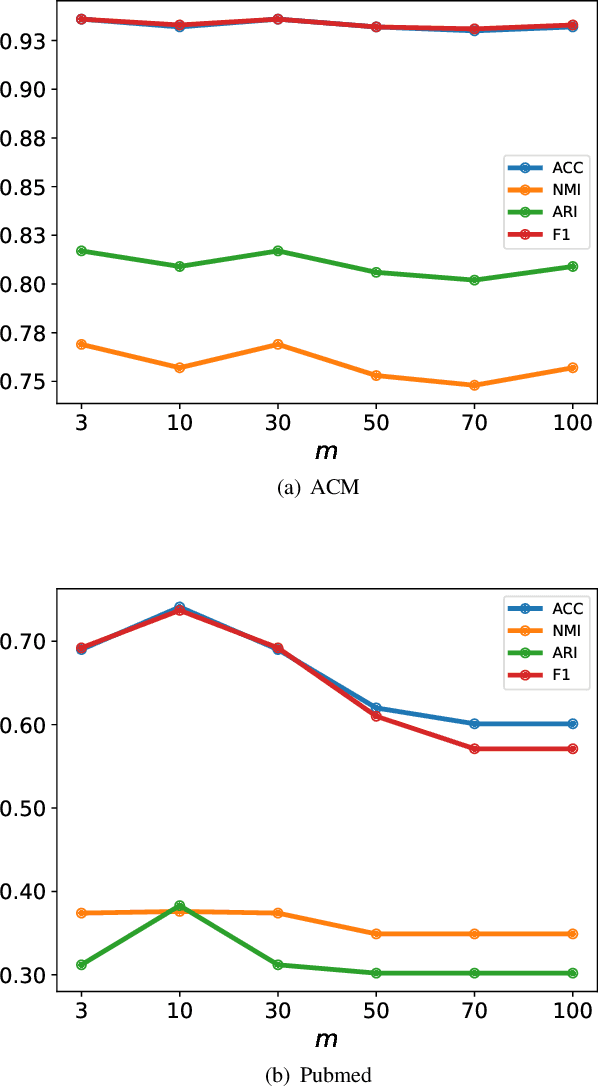
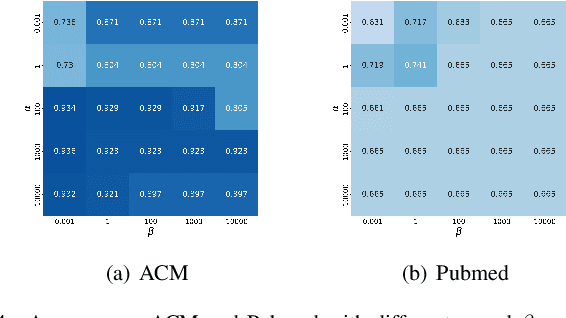
In today's data-driven digital era, the amount as well as complexity, such as multi-view, non-Euclidean, and multi-relational, of the collected data are growing exponentially or even faster. Clustering, which unsupervisely extracts valid knowledge from data, is extremely useful in practice. However, existing methods are independently developed to handle one particular challenge at the expense of the others. In this work, we propose a simple but effective framework for complex data clustering (CDC) that can efficiently process different types of data with linear complexity. We first utilize graph filtering to fuse geometry structure and attribute information. We then reduce the complexity with high-quality anchors that are adaptively learned via a novel similarity-preserving regularizer. We illustrate the cluster-ability of our proposed method theoretically and experimentally. In particular, we deploy CDC to graph data of size 111M.
Robust Graph Structure Learning under Heterophily
Mar 06, 2024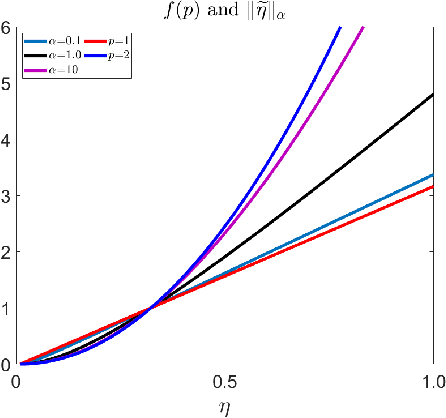
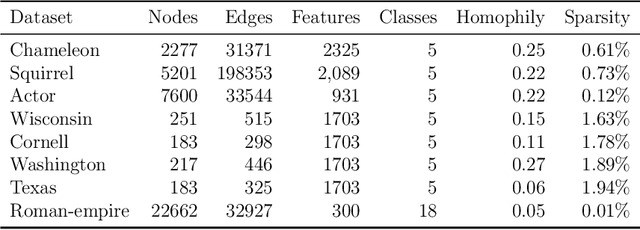

Graph is a fundamental mathematical structure in characterizing relations between different objects and has been widely used on various learning tasks. Most methods implicitly assume a given graph to be accurate and complete. However, real data is inevitably noisy and sparse, which will lead to inferior results. Despite the remarkable success of recent graph representation learning methods, they inherently presume that the graph is homophilic, and largely overlook heterophily, where most connected nodes are from different classes. In this regard, we propose a novel robust graph structure learning method to achieve a high-quality graph from heterophilic data for downstream tasks. We first apply a high-pass filter to make each node more distinctive from its neighbors by encoding structure information into the node features. Then, we learn a robust graph with an adaptive norm characterizing different levels of noise. Afterwards, we propose a novel regularizer to further refine the graph structure. Clustering and semi-supervised classification experiments on heterophilic graphs verify the effectiveness of our method.
Provable Filter for Real-world Graph Clustering
Mar 06, 2024
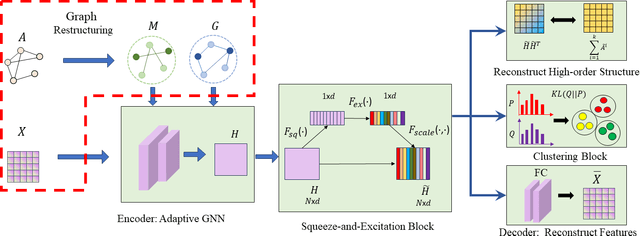
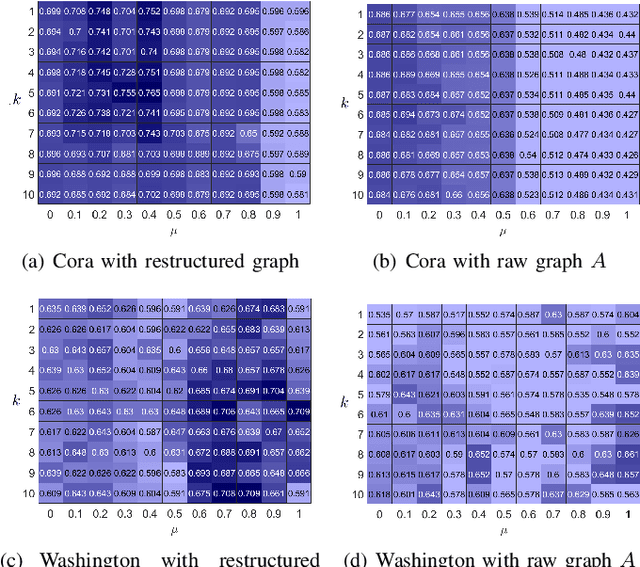
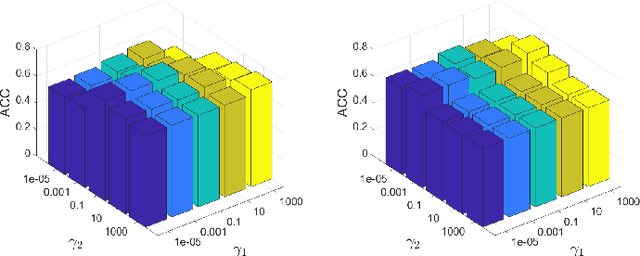
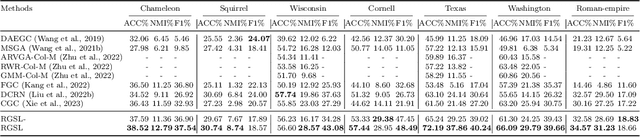
Graph clustering, an important unsupervised problem, has been shown to be more resistant to advances in Graph Neural Networks (GNNs). In addition, almost all clustering methods focus on homophilic graphs and ignore heterophily. This significantly limits their applicability in practice, since real-world graphs exhibit a structural disparity and cannot simply be classified as homophily and heterophily. Thus, a principled way to handle practical graphs is urgently needed. To fill this gap, we provide a novel solution with theoretical support. Interestingly, we find that most homophilic and heterophilic edges can be correctly identified on the basis of neighbor information. Motivated by this finding, we construct two graphs that are highly homophilic and heterophilic, respectively. They are used to build low-pass and high-pass filters to capture holistic information. Important features are further enhanced by the squeeze-and-excitation block. We validate our approach through extensive experiments on both homophilic and heterophilic graphs. Empirical results demonstrate the superiority of our method compared to state-of-the-art clustering methods.
Simplified PCNet with Robustness
Mar 06, 2024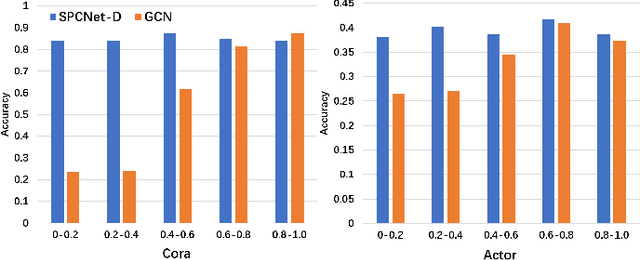
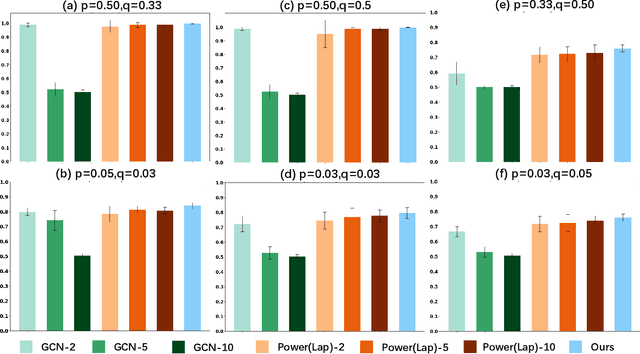
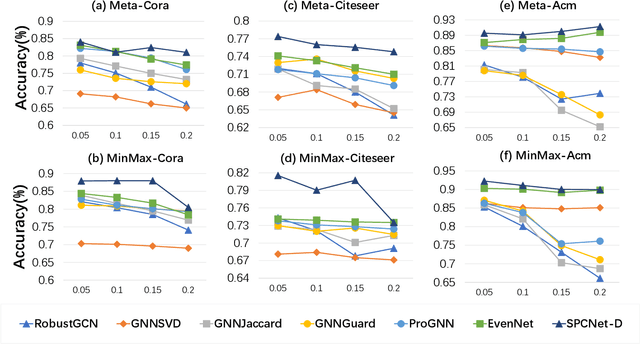

Graph Neural Networks (GNNs) have garnered significant attention for their success in learning the representation of homophilic or heterophilic graphs. However, they cannot generalize well to real-world graphs with different levels of homophily. In response, the Possion-Charlier Network (PCNet) \cite{li2024pc}, the previous work, allows graph representation to be learned from heterophily to homophily. Although PCNet alleviates the heterophily issue, there remain some challenges in further improving the efficacy and efficiency. In this paper, we simplify PCNet and enhance its robustness. We first extend the filter order to continuous values and reduce its parameters. Two variants with adaptive neighborhood sizes are implemented. Theoretical analysis shows our model's robustness to graph structure perturbations or adversarial attacks. We validate our approach through semi-supervised learning tasks on various datasets representing both homophilic and heterophilic graphs.
FCDS: Fusing Constituency and Dependency Syntax into Document-Level Relation Extraction
Mar 04, 2024
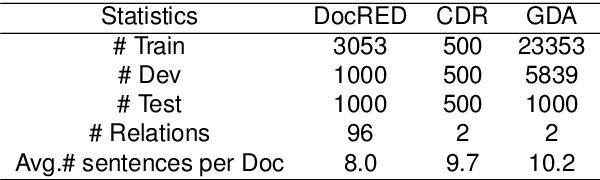
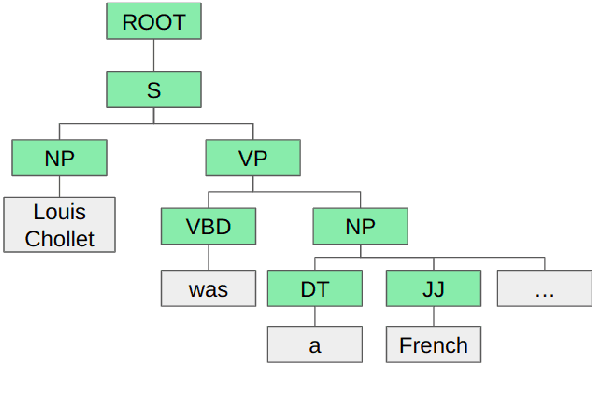
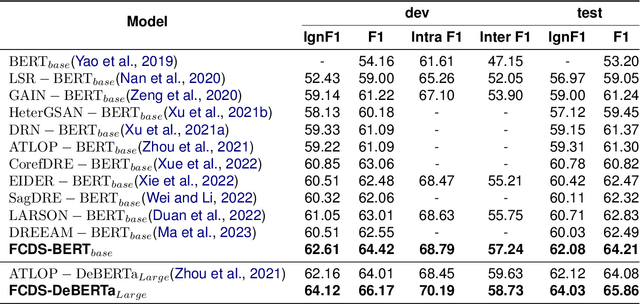
Document-level Relation Extraction (DocRE) aims to identify relation labels between entities within a single document. It requires handling several sentences and reasoning over them. State-of-the-art DocRE methods use a graph structure to connect entities across the document to capture dependency syntax information. However, this is insufficient to fully exploit the rich syntax information in the document. In this work, we propose to fuse constituency and dependency syntax into DocRE. It uses constituency syntax to aggregate the whole sentence information and select the instructive sentences for the pairs of targets. It exploits the dependency syntax in a graph structure with constituency syntax enhancement and chooses the path between entity pairs based on the dependency graph. The experimental results on datasets from various domains demonstrate the effectiveness of the proposed method. The code is publicly available at this url.
PC-Conv: Unifying Homophily and Heterophily with Two-fold Filtering
Dec 22, 2023Recently, many carefully crafted graph representation learning methods have achieved impressive performance on either strong heterophilic or homophilic graphs, but not both. Therefore, they are incapable of generalizing well across real-world graphs with different levels of homophily. This is attributed to their neglect of homophily in heterophilic graphs, and vice versa. In this paper, we propose a two-fold filtering mechanism to extract homophily in heterophilic graphs and vice versa. In particular, we extend the graph heat equation to perform heterophilic aggregation of global information from a long distance. The resultant filter can be exactly approximated by the Possion-Charlier (PC) polynomials. To further exploit information at multiple orders, we introduce a powerful graph convolution PC-Conv and its instantiation PCNet for the node classification task. Compared with state-of-the-art GNNs, PCNet shows competitive performance on well-known homophilic and heterophilic graphs. Our implementation is available at https://github.com/uestclbh/PC-Conv.
Upper Bounding Barlow Twins: A Novel Filter for Multi-Relational Clustering
Dec 21, 2023Multi-relational clustering is a challenging task due to the fact that diverse semantic information conveyed in multi-layer graphs is difficult to extract and fuse. Recent methods integrate topology structure and node attribute information through graph filtering. However, they often use a low-pass filter without fully considering the correlation among multiple graphs. To overcome this drawback, we propose to learn a graph filter motivated by the theoretical analysis of Barlow Twins. We find that input with a negative semi-definite inner product provides a lower bound for Barlow Twins loss, which prevents it from reaching a better solution. We thus learn a filter that yields an upper bound for Barlow Twins. Afterward, we design a simple clustering architecture and demonstrate its state-of-the-art performance on four benchmark datasets.
Non-Autoregressive Diffusion-based Temporal Point Processes for Continuous-Time Long-Term Event Prediction
Nov 02, 2023Continuous-time long-term event prediction plays an important role in many application scenarios. Most existing works rely on autoregressive frameworks to predict event sequences, which suffer from error accumulation, thus compromising prediction quality. Inspired by the success of denoising diffusion probabilistic models, we propose a diffusion-based non-autoregressive temporal point process model for long-term event prediction in continuous time. Instead of generating events one at a time in an autoregressive way, our model predicts the future event sequence entirely as a whole. In order to perform diffusion processes on event sequences, we develop a bidirectional map between target event sequences and the Euclidean vector space. Furthermore, we design a novel denoising network to capture both sequential and contextual features for better sample quality. Extensive experiments are conducted to prove the superiority of our proposed model over state-of-the-art methods on long-term event prediction in continuous time. To the best of our knowledge, this is the first work to apply diffusion methods to long-term event prediction problems.
A Prototype-Based Neural Network for Image Anomaly Detection and Localization
Oct 04, 2023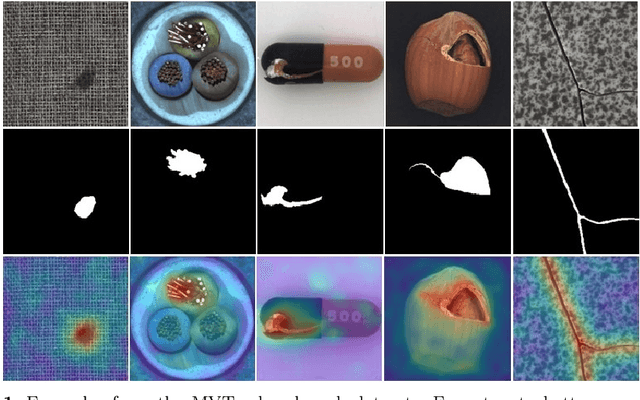
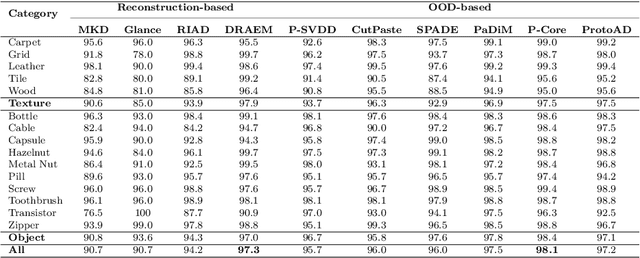
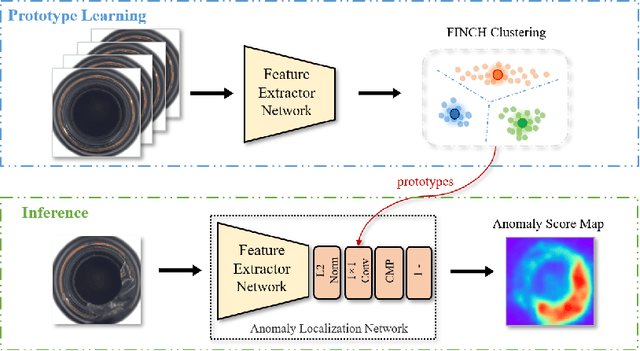
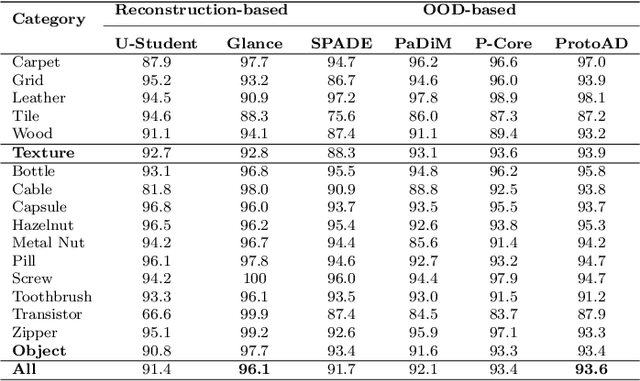
Image anomaly detection and localization perform not only image-level anomaly classification but also locate pixel-level anomaly regions. Recently, it has received much research attention due to its wide application in various fields. This paper proposes ProtoAD, a prototype-based neural network for image anomaly detection and localization. First, the patch features of normal images are extracted by a deep network pre-trained on nature images. Then, the prototypes of the normal patch features are learned by non-parametric clustering. Finally, we construct an image anomaly localization network (ProtoAD) by appending the feature extraction network with $L2$ feature normalization, a $1\times1$ convolutional layer, a channel max-pooling, and a subtraction operation. We use the prototypes as the kernels of the $1\times1$ convolutional layer; therefore, our neural network does not need a training phase and can conduct anomaly detection and localization in an end-to-end manner. Extensive experiments on two challenging industrial anomaly detection datasets, MVTec AD and BTAD, demonstrate that ProtoAD achieves competitive performance compared to the state-of-the-art methods with a higher inference speed. The source code is available at: https://github.com/98chao/ProtoAD.
Intensity-free Convolutional Temporal Point Process: Incorporating Local and Global Event Contexts
Jun 24, 2023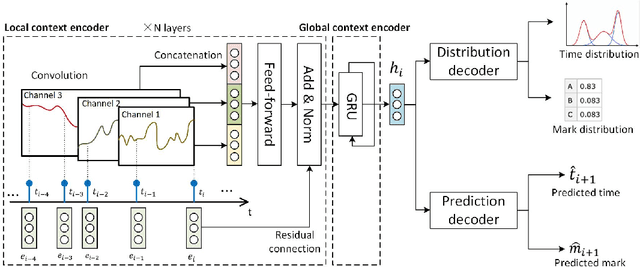
Event prediction in the continuous-time domain is a crucial but rather difficult task. Temporal point process (TPP) learning models have shown great advantages in this area. Existing models mainly focus on encoding global contexts of events using techniques like recurrent neural networks (RNNs) or self-attention mechanisms. However, local event contexts also play an important role in the occurrences of events, which has been largely ignored. Popular convolutional neural networks, which are designated for local context capturing, have never been applied to TPP modelling due to their incapability of modelling in continuous time. In this work, we propose a novel TPP modelling approach that combines local and global contexts by integrating a continuous-time convolutional event encoder with an RNN. The presented framework is flexible and scalable to handle large datasets with long sequences and complex latent patterns. The experimental result shows that the proposed model improves the performance of probabilistic sequential modelling and the accuracy of event prediction. To our best knowledge, this is the first work that applies convolutional neural networks to TPP modelling.