 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinlin Shen
Multi-scale Dynamic and Hierarchical Relationship Modeling for Facial Action Units Recognition
Apr 09, 2024
Human facial action units (AUs) are mutually related in a hierarchical manner, as not only they are associated with each other in both spatial and temporal domains but also AUs located in the same/close facial regions show stronger relationships than those of different facial regions. While none of existing approach thoroughly model such hierarchical inter-dependencies among AUs, this paper proposes to comprehensively model multi-scale AU-related dynamic and hierarchical spatio-temporal relationship among AUs for their occurrences recognition. Specifically, we first propose a novel multi-scale temporal differencing network with an adaptive weighting block to explicitly capture facial dynamics across frames at different spatial scales, which specifically considers the heterogeneity of range and magnitude in different AUs' activation. Then, a two-stage strategy is introduced to hierarchically model the relationship among AUs based on their spatial distribution (i.e., local and cross-region AU relationship modelling). Experimental results achieved on BP4D and DISFA show that our approach is the new state-of-the-art in the field of AU occurrence recognition. Our code is publicly available at https://github.com/CVI-SZU/MDHR.
CodeEnhance: A Codebook-Driven Approach for Low-Light Image Enhancement
Apr 08, 2024Low-light image enhancement (LLIE) aims to improve low-illumination images. However, existing methods face two challenges: (1) uncertainty in restoration from diverse brightness degradations; (2) loss of texture and color information caused by noise suppression and light enhancement. In this paper, we propose a novel enhancement approach, CodeEnhance, by leveraging quantized priors and image refinement to address these challenges. In particular, we reframe LLIE as learning an image-to-code mapping from low-light images to discrete codebook, which has been learned from high-quality images. To enhance this process, a Semantic Embedding Module (SEM) is introduced to integrate semantic information with low-level features, and a Codebook Shift (CS) mechanism, designed to adapt the pre-learned codebook to better suit the distinct characteristics of our low-light dataset. Additionally, we present an Interactive Feature Transformation (IFT) module to refine texture and color information during image reconstruction, allowing for interactive enhancement based on user preferences. Extensive experiments on both real-world and synthetic benchmarks demonstrate that the incorporation of prior knowledge and controllable information transfer significantly enhances LLIE performance in terms of quality and fidelity. The proposed CodeEnhance exhibits superior robustness to various degradations, including uneven illumination, noise, and color distortion.
Rediscovering BCE Loss for Uniform Classification
Mar 12, 2024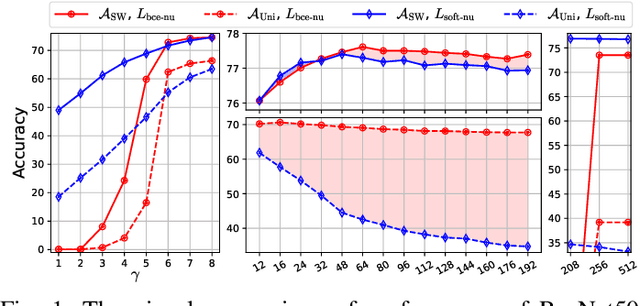
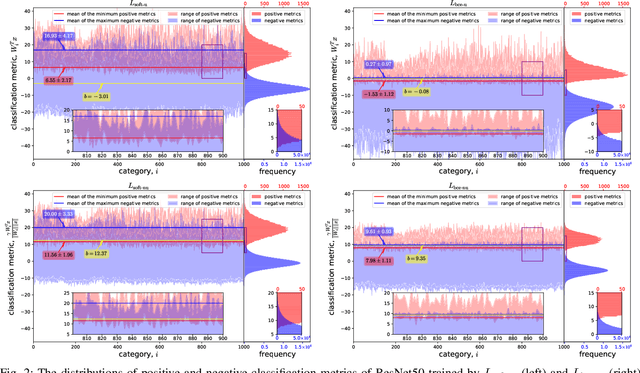

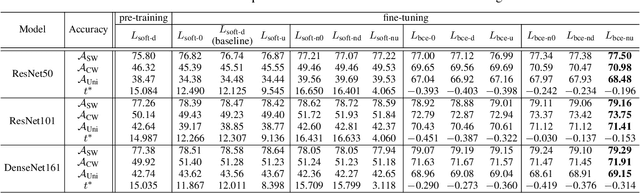
This paper introduces the concept of uniform classification, which employs a unified threshold to classify all samples rather than adaptive threshold classifying each individual sample. We also propose the uniform classification accuracy as a metric to measure the model's performance in uniform classification. Furthermore, begin with a naive loss, we mathematically derive a loss function suitable for the uniform classification, which is the BCE function integrated with a unified bias. We demonstrate the unified threshold could be learned via the bias. The extensive experiments on six classification datasets and three feature extraction models show that, compared to the SoftMax loss, the models trained with the BCE loss not only exhibit higher uniform classification accuracy but also higher sample-wise classification accuracy. In addition, the learned bias from BCE loss is very close to the unified threshold used in the uniform classification. The features extracted by the models trained with BCE loss not only possess uniformity but also demonstrate better intra-class compactness and inter-class distinctiveness, yielding superior performance on open-set tasks such as face recognition.
Fingerprint Presentation Attack Detector Using Global-Local Model
Feb 20, 2024The vulnerability of automated fingerprint recognition systems (AFRSs) to presentation attacks (PAs) promotes the vigorous development of PA detection (PAD) technology. However, PAD methods have been limited by information loss and poor generalization ability, resulting in new PA materials and fingerprint sensors. This paper thus proposes a global-local model-based PAD (RTK-PAD) method to overcome those limitations to some extent. The proposed method consists of three modules, called: 1) the global module; 2) the local module; and 3) the rethinking module. By adopting the cut-out-based global module, a global spoofness score predicted from nonlocal features of the entire fingerprint images can be achieved. While by using the texture in-painting-based local module, a local spoofness score predicted from fingerprint patches is obtained. The two modules are not independent but connected through our proposed rethinking module by localizing two discriminative patches for the local module based on the global spoofness score. Finally, the fusion spoofness score by averaging the global and local spoofness scores is used for PAD. Our experimental results evaluated on LivDet 2017 show that the proposed RTK-PAD can achieve an average classification error (ACE) of 2.28% and a true detection rate (TDR) of 91.19% when the false detection rate (FDR) equals 1.0%, which significantly outperformed the state-of-the-art methods by $\sim$10% in terms of TDR (91.19% versus 80.74%).
* This paper was accepted by IEEE Transactions on Cybernetics. Current version is updated with minor revisions on introduction and related works
Asclepius: A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models
Feb 17, 2024The significant breakthroughs of Medical Multi-Modal Large Language Models (Med-MLLMs) renovate modern healthcare with robust information synthesis and medical decision support. However, these models are often evaluated on benchmarks that are unsuitable for the Med-MLLMs due to the intricate nature of the real-world diagnostic frameworks, which encompass diverse medical specialties and involve complex clinical decisions. Moreover, these benchmarks are susceptible to data leakage, since Med-MLLMs are trained on large assemblies of publicly available data. Thus, an isolated and clinically representative benchmark is highly desirable for credible Med-MLLMs evaluation. To this end, we introduce Asclepius, a novel Med-MLLM benchmark that rigorously and comprehensively assesses model capability in terms of: distinct medical specialties (cardiovascular, gastroenterology, etc.) and different diagnostic capacities (perception, disease analysis, etc.). Grounded in 3 proposed core principles, Asclepius ensures a comprehensive evaluation by encompassing 15 medical specialties, stratifying into 3 main categories and 8 sub-categories of clinical tasks, and exempting from train-validate contamination. We further provide an in-depth analysis of 6 Med-MLLMs and compare them with 5 human specialists, providing insights into their competencies and limitations in various medical contexts. Our work not only advances the understanding of Med-MLLMs' capabilities but also sets a precedent for future evaluations and the safe deployment of these models in clinical environments. We launch and maintain a leaderboard for community assessment of Med-MLLM capabilities (https://asclepius-med.github.io/).
Boosting Adversarial Transferability across Model Genus by Deformation-Constrained Warping
Feb 06, 2024Adversarial examples generated by a surrogate model typically exhibit limited transferability to unknown target systems. To address this problem, many transferability enhancement approaches (e.g., input transformation and model augmentation) have been proposed. However, they show poor performances in attacking systems having different model genera from the surrogate model. In this paper, we propose a novel and generic attacking strategy, called Deformation-Constrained Warping Attack (DeCoWA), that can be effectively applied to cross model genus attack. Specifically, DeCoWA firstly augments input examples via an elastic deformation, namely Deformation-Constrained Warping (DeCoW), to obtain rich local details of the augmented input. To avoid severe distortion of global semantics led by random deformation, DeCoW further constrains the strength and direction of the warping transformation by a novel adaptive control strategy. Extensive experiments demonstrate that the transferable examples crafted by our DeCoWA on CNN surrogates can significantly hinder the performance of Transformers (and vice versa) on various tasks, including image classification, video action recognition, and audio recognition. Code is made available at https://github.com/LinQinLiang/DeCoWA.
GenFace: A Large-Scale Fine-Grained Face Forgery Benchmark and Cross Appearance-Edge Learning
Feb 03, 2024The rapid advancement of photorealistic generators has reached a critical juncture where the discrepancy between authentic and manipulated images is increasingly indistinguishable. Thus, benchmarking and advancing techniques detecting digital manipulation become an urgent issue. Although there have been a number of publicly available face forgery datasets, the forgery faces are mostly generated using GAN-based synthesis technology, which does not involve the most recent technologies like diffusion. The diversity and quality of images generated by diffusion models have been significantly improved and thus a much more challenging face forgery dataset shall be used to evaluate SOTA forgery detection literature. In this paper, we propose a large-scale, diverse, and fine-grained high-fidelity dataset, namely GenFace, to facilitate the advancement of deepfake detection, which contains a large number of forgery faces generated by advanced generators such as the diffusion-based model and more detailed labels about the manipulation approaches and adopted generators. In addition to evaluating SOTA approaches on our benchmark, we design an innovative cross appearance-edge learning (CAEL) detector to capture multi-grained appearance and edge global representations, and detect discriminative and general forgery traces. Moreover, we devise an appearance-edge cross-attention (AECA) module to explore the various integrations across two domains. Extensive experiment results and visualizations show that our detection model outperforms the state of the arts on different settings like cross-generator, cross-forgery, and cross-dataset evaluations. Code and datasets will be available at \url{https://github.com/Jenine-321/GenFace
Question-Answer Cross Language Image Matching for Weakly Supervised Semantic Segmentation
Jan 18, 2024Class Activation Map (CAM) has emerged as a popular tool for weakly supervised semantic segmentation (WSSS), allowing the localization of object regions in an image using only image-level labels. However, existing CAM methods suffer from under-activation of target object regions and false-activation of background regions due to the fact that a lack of detailed supervision can hinder the model's ability to understand the image as a whole. In this paper, we propose a novel Question-Answer Cross-Language-Image Matching framework for WSSS (QA-CLIMS), leveraging the vision-language foundation model to maximize the text-based understanding of images and guide the generation of activation maps. First, a series of carefully designed questions are posed to the VQA (Visual Question Answering) model with Question-Answer Prompt Engineering (QAPE) to generate a corpus of both foreground target objects and backgrounds that are adaptive to query images. We then employ contrastive learning in a Region Image Text Contrastive (RITC) network to compare the obtained foreground and background regions with the generated corpus. Our approach exploits the rich textual information from the open vocabulary as additional supervision, enabling the model to generate high-quality CAMs with a more complete object region and reduce false-activation of background regions. We conduct extensive analysis to validate the proposed method and show that our approach performs state-of-the-art on both PASCAL VOC 2012 and MS COCO datasets. Code is available at: https://github.com/CVI-SZU/QA-CLIMS
Fine-Grained Image-Text Alignment in Medical Imaging Enables Cyclic Image-Report Generation
Dec 27, 2023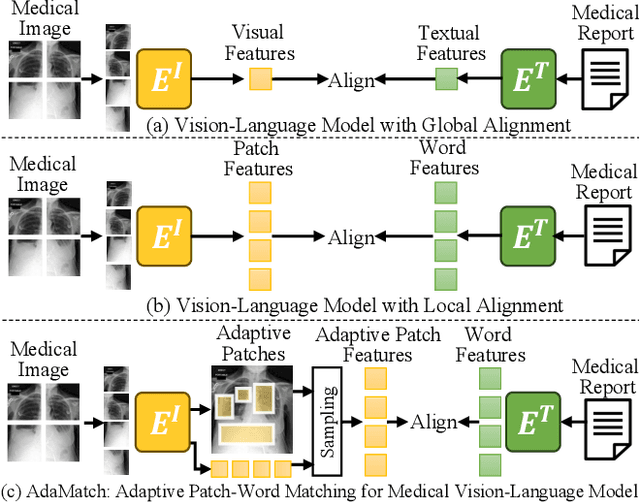
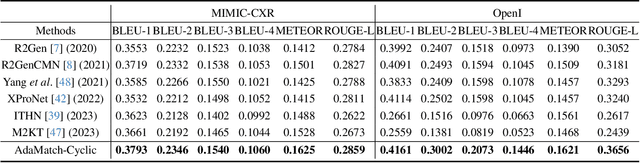
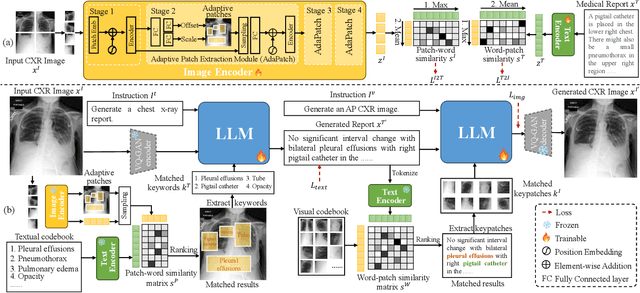
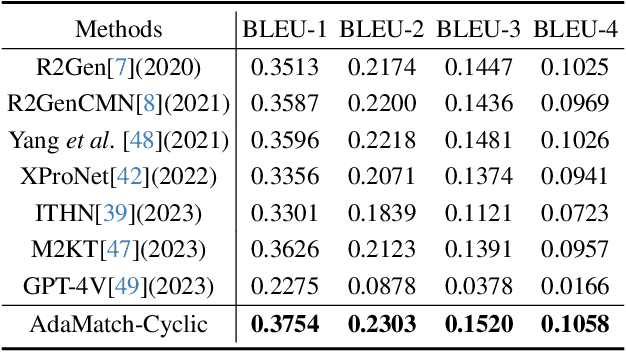
To address these issues, we propose a novel Adaptive patch-word Matching (AdaMatch) model to correlate chest X-ray (CXR) image regions with words in medical reports and apply it to CXR-report generation to provide explainability for the generation process. AdaMatch exploits the fine-grained relation between adaptive patches and words to provide explanations of specific image regions with corresponding words. To capture the abnormal regions of varying sizes and positions, we introduce the Adaptive Patch extraction (AdaPatch) module to acquire the adaptive patches for these regions adaptively. In order to provide explicit explainability for CXR-report generation task, we propose an AdaMatch-based bidirectional large language model for Cyclic CXR-report generation (AdaMatch-Cyclic). It employs the AdaMatch to obtain the keywords for CXR images and `keypatches' for medical reports as hints to guide CXR-report generation. Extensive experiments on two publicly available CXR datasets prove the effectiveness of our method and its superior performance to existing methods.
SCPMan: Shape Context and Prior Constrained Multi-scale Attention Network for Pancreatic Segmentation
Dec 26, 2023Due to the poor prognosis of Pancreatic cancer, accurate early detection and segmentation are critical for improving treatment outcomes. However, pancreatic segmentation is challenged by blurred boundaries, high shape variability, and class imbalance. To tackle these problems, we propose a multiscale attention network with shape context and prior constraint for robust pancreas segmentation. Specifically, we proposed a Multi-scale Feature Extraction Module (MFE) and a Mixed-scale Attention Integration Module (MAI) to address unclear pancreas boundaries. Furthermore, a Shape Context Memory (SCM) module is introduced to jointly model semantics across scales and pancreatic shape. Active Shape Model (ASM) is further used to model the shape priors. Experiments on NIH and MSD datasets demonstrate the efficacy of our model, which improves the state-of-the-art Dice Score for 1.01% and 1.03% respectively. Our architecture provides robust segmentation performance, against the blurry boundaries, and variations in scale and shape of pancreas.