 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoyi Liu
$\mathbf{(N,K)}$-Puzzle: A Cost-Efficient Testbed for Benchmarking Reinforcement Learning Algorithms in Generative Language Model
Mar 11, 2024
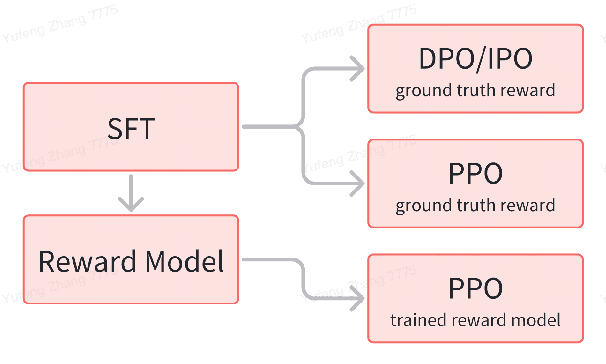
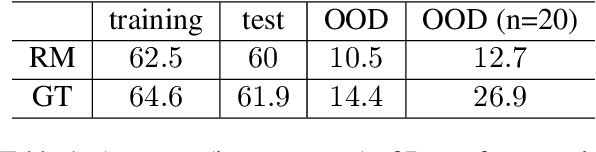
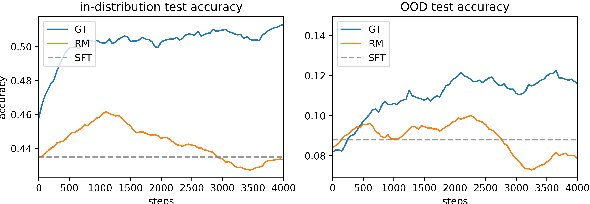
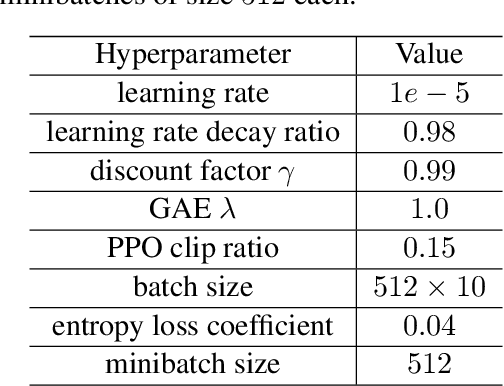
Recent advances in reinforcement learning (RL) algorithms aim to enhance the performance of language models at scale. Yet, there is a noticeable absence of a cost-effective and standardized testbed tailored to evaluating and comparing these algorithms. To bridge this gap, we present a generalized version of the 24-Puzzle: the $(N,K)$-Puzzle, which challenges language models to reach a target value $K$ with $N$ integers. We evaluate the effectiveness of established RL algorithms such as Proximal Policy Optimization (PPO), alongside novel approaches like Identity Policy Optimization (IPO) and Direct Policy Optimization (DPO).
Double Duality: Variational Primal-Dual Policy Optimization for Constrained Reinforcement Learning
Feb 16, 2024We study the Constrained Convex Markov Decision Process (MDP), where the goal is to minimize a convex functional of the visitation measure, subject to a convex constraint. Designing algorithms for a constrained convex MDP faces several challenges, including (1) handling the large state space, (2) managing the exploration/exploitation tradeoff, and (3) solving the constrained optimization where the objective and the constraint are both nonlinear functions of the visitation measure. In this work, we present a model-based algorithm, Variational Primal-Dual Policy Optimization (VPDPO), in which Lagrangian and Fenchel duality are implemented to reformulate the original constrained problem into an unconstrained primal-dual optimization. Moreover, the primal variables are updated by model-based value iteration following the principle of Optimism in the Face of Uncertainty (OFU), while the dual variables are updated by gradient ascent. Moreover, by embedding the visitation measure into a finite-dimensional space, we can handle large state spaces by incorporating function approximation. Two notable examples are (1) Kernelized Nonlinear Regulators and (2) Low-rank MDPs. We prove that with an optimistic planning oracle, our algorithm achieves sublinear regret and constraint violation in both cases and can attain the globally optimal policy of the original constrained problem.
Improving Efficiency of DNN-based Relocalization Module for Autonomous Driving with Server-side Computing
Dec 01, 2023In this work, we present a novel framework for camera relocation in autonomous vehicles, leveraging deep neural networks (DNN). While existing literature offers various DNN-based camera relocation methods, their deployment is hindered by their high computational demands during inference. In contrast, our approach addresses this challenge through edge cloud collaboration. Specifically, we strategically offload certain modules of the neural network to the server and evaluate the inference time of data frames under different network segmentation schemes to guide our offloading decisions. Our findings highlight the vital role of server-side offloading in DNN-based camera relocation for autonomous vehicles, and we also discuss the results of data fusion. Finally, we validate the effectiveness of our proposed framework through experimental evaluation.
Model-Based Reparameterization Policy Gradient Methods: Theory and Practical Algorithms
Oct 30, 2023ReParameterization (RP) Policy Gradient Methods (PGMs) have been widely adopted for continuous control tasks in robotics and computer graphics. However, recent studies have revealed that, when applied to long-term reinforcement learning problems, model-based RP PGMs may experience chaotic and non-smooth optimization landscapes with exploding gradient variance, which leads to slow convergence. This is in contrast to the conventional belief that reparameterization methods have low gradient estimation variance in problems such as training deep generative models. To comprehend this phenomenon, we conduct a theoretical examination of model-based RP PGMs and search for solutions to the optimization difficulties. Specifically, we analyze the convergence of the model-based RP PGMs and pinpoint the smoothness of function approximators as a major factor that affects the quality of gradient estimation. Based on our analysis, we propose a spectral normalization method to mitigate the exploding variance issue caused by long model unrolls. Our experimental results demonstrate that proper normalization significantly reduces the gradient variance of model-based RP PGMs. As a result, the performance of the proposed method is comparable or superior to other gradient estimators, such as the Likelihood Ratio (LR) gradient estimator. Our code is available at https://github.com/agentification/RP_PGM.
Reason for Future, Act for Now: A Principled Framework for Autonomous LLM Agents with Provable Sample Efficiency
Oct 11, 2023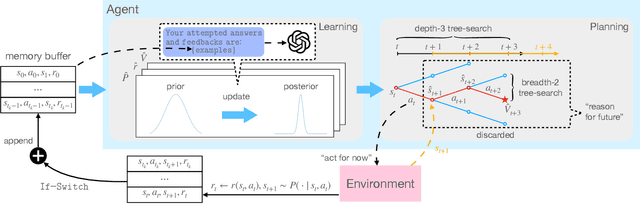

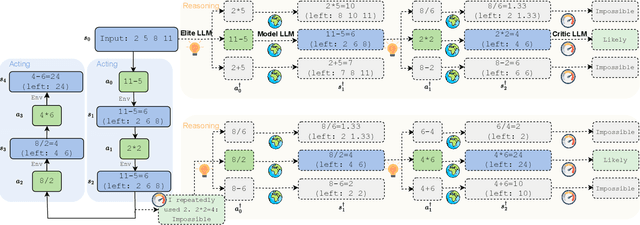
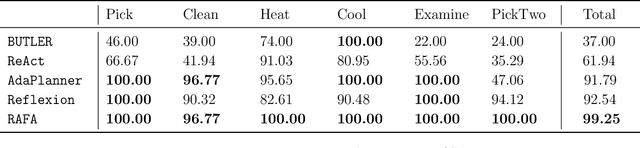
Large language models (LLMs) demonstrate impressive reasoning abilities, but translating reasoning into actions in the real world remains challenging. In particular, it remains unclear how to complete a given task provably within a minimum number of interactions with the external environment, e.g., through an internal mechanism of reasoning. To this end, we propose a principled framework with provable regret guarantees to orchestrate reasoning and acting, which we call "reason for future, act for now" (\texttt{RAFA}). Specifically, we design a prompt template for reasoning that learns from the memory buffer and plans a future trajectory over a long horizon ("reason for future"). At each step, the LLM agent takes the initial action of the planned trajectory ("act for now"), stores the collected feedback in the memory buffer, and reinvokes the reasoning routine to replan the future trajectory from the new state. The key idea is to cast reasoning in LLMs as learning and planning in Bayesian adaptive Markov decision processes (MDPs). Correspondingly, we prompt LLMs to form an updated posterior of the unknown environment from the memory buffer (learning) and generate an optimal trajectory for multiple future steps that maximizes a value function (planning). The learning and planning subroutines are performed in an "in-context" manner to emulate the actor-critic update for MDPs. Our theoretical analysis proves that the novel combination of long-term reasoning and short-term acting achieves a $\sqrt{T}$ regret. In particular, the regret bound highlights an intriguing interplay between the prior knowledge obtained through pretraining and the uncertainty reduction achieved by reasoning and acting. Our empirical validation shows that it outperforms various existing frameworks and achieves nearly perfect scores on a few benchmarks.
Let Models Speak Ciphers: Multiagent Debate through Embeddings
Oct 10, 2023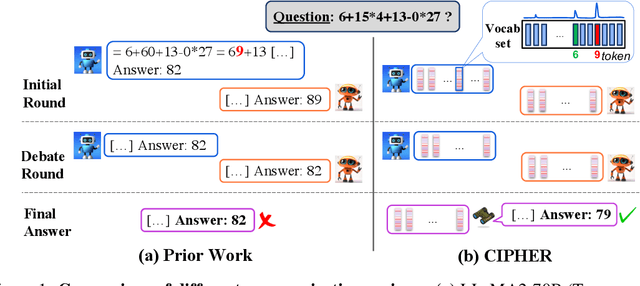
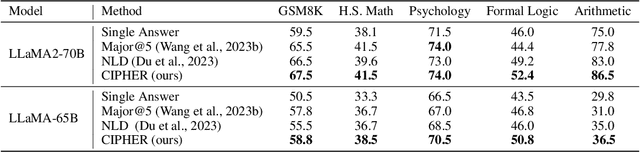

Discussion and debate among Large Language Models (LLMs) have gained considerable attention due to their potential to enhance the reasoning ability of LLMs. Although natural language is an obvious choice for communication due to LLM's language understanding capability, the token sampling step needed when generating natural language poses a potential risk of information loss, as it uses only one token to represent the model's belief across the entire vocabulary. In this paper, we introduce a communication regime named CIPHER (Communicative Inter-Model Protocol Through Embedding Representation) to address this issue. Specifically, we remove the token sampling step from LLMs and let them communicate their beliefs across the vocabulary through the expectation of the raw transformer output embeddings. Remarkably, by deviating from natural language, CIPHER offers an advantage of encoding a broader spectrum of information without any modification to the model weights. While the state-of-the-art LLM debate methods using natural language outperforms traditional inference by a margin of 1.5-8%, our experiment results show that CIPHER debate further extends this lead by 1-3.5% across five reasoning tasks and multiple open-source LLMs of varying sizes. This showcases the superiority and robustness of embeddings as an alternative "language" for communication among LLMs.
Differentiable Arbitrating in Zero-sum Markov Games
Feb 20, 2023


We initiate the study of how to perturb the reward in a zero-sum Markov game with two players to induce a desirable Nash equilibrium, namely arbitrating. Such a problem admits a bi-level optimization formulation. The lower level requires solving the Nash equilibrium under a given reward function, which makes the overall problem challenging to optimize in an end-to-end way. We propose a backpropagation scheme that differentiates through the Nash equilibrium, which provides the gradient feedback for the upper level. In particular, our method only requires a black-box solver for the (regularized) Nash equilibrium (NE). We develop the convergence analysis for the proposed framework with proper black-box NE solvers and demonstrate the empirical successes in two multi-agent reinforcement learning (MARL) environments.
An Efficient Approach to the Online Multi-Agent Path Finding Problem by Using Sustainable Information
Jan 11, 2023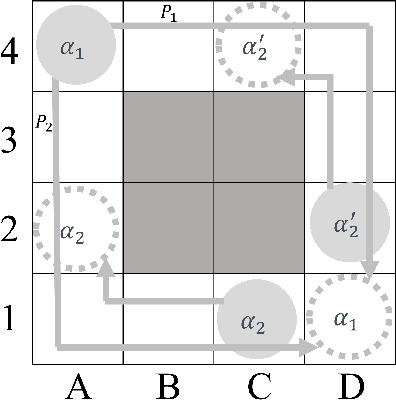
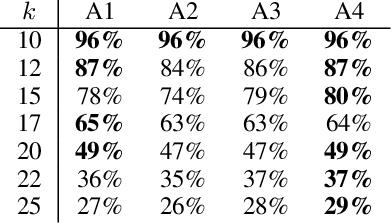
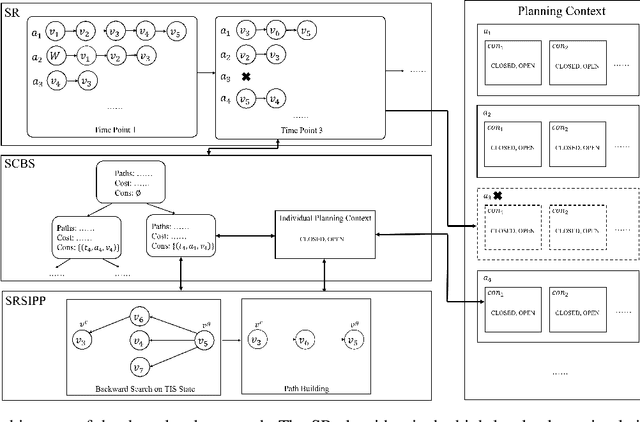

Multi-agent path finding (MAPF) is the problem of moving agents to the goal vertex without collision. In the online MAPF problem, new agents may be added to the environment at any time, and the current agents have no information about future agents. The inability of existing online methods to reuse previous planning contexts results in redundant computation and reduces algorithm efficiency. Hence, we propose a three-level approach to solve online MAPF utilizing sustainable information, which can decrease its redundant calculations. The high-level solver, the Sustainable Replan algorithm (SR), manages the planning context and simulates the environment. The middle-level solver, the Sustainable Conflict-Based Search algorithm (SCBS), builds a conflict tree and maintains the planning context. The low-level solver, the Sustainable Reverse Safe Interval Path Planning algorithm (SRSIPP), is an efficient single-agent solver that uses previous planning context to reduce duplicate calculations. Experiments show that our proposed method has significant improvement in terms of computational efficiency. In one of the test scenarios, our algorithm can be 1.48 times faster than SOTA on average under different agent number settings.
An Analysis of Attention via the Lens of Exchangeability and Latent Variable Models
Dec 30, 2022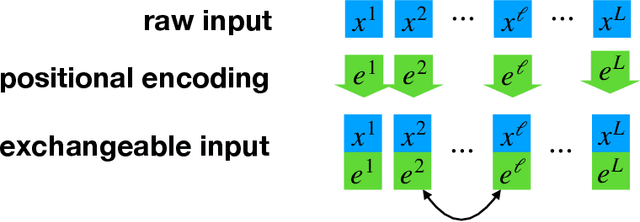
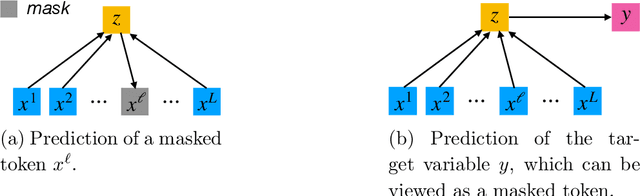
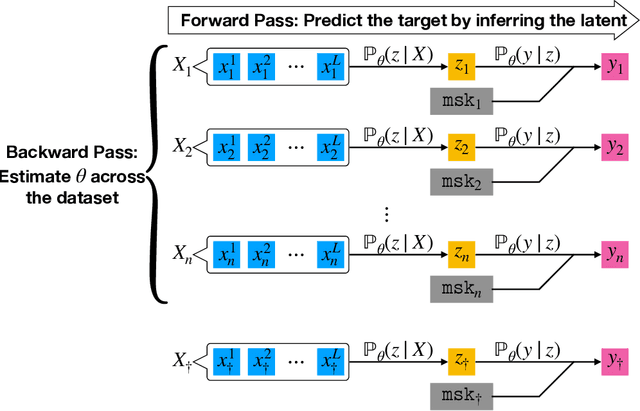
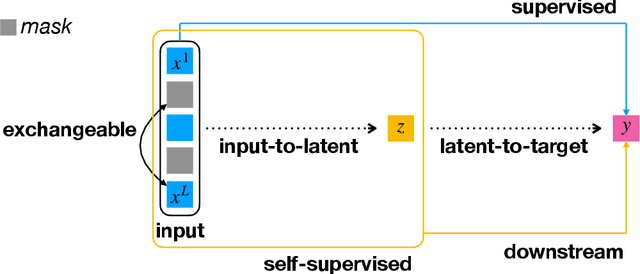
With the attention mechanism, transformers achieve significant empirical successes. Despite the intuitive understanding that transformers perform relational inference over long sequences to produce desirable representations, we lack a rigorous theory on how the attention mechanism achieves it. In particular, several intriguing questions remain open: (a) What makes a desirable representation? (b) How does the attention mechanism infer the desirable representation within the forward pass? (c) How does a pretraining procedure learn to infer the desirable representation through the backward pass? We observe that, as is the case in BERT and ViT, input tokens are often exchangeable since they already include positional encodings. The notion of exchangeability induces a latent variable model that is invariant to input sizes, which enables our theoretical analysis. - To answer (a) on representation, we establish the existence of a sufficient and minimal representation of input tokens. In particular, such a representation instantiates the posterior distribution of the latent variable given input tokens, which plays a central role in predicting output labels and solving downstream tasks. - To answer (b) on inference, we prove that attention with the desired parameter infers the latent posterior up to an approximation error, which is decreasing in input sizes. In detail, we quantify how attention approximates the conditional mean of the value given the key, which characterizes how it performs relational inference over long sequences. - To answer (c) on learning, we prove that both supervised and self-supervised objectives allow empirical risk minimization to learn the desired parameter up to a generalization error, which is independent of input sizes. Particularly, in the self-supervised setting, we identify a condition number that is pivotal to solving downstream tasks.
Relational Reasoning via Set Transformers: Provable Efficiency and Applications to MARL
Sep 26, 2022
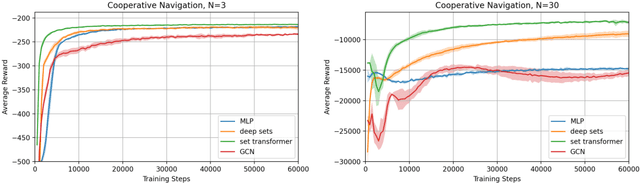
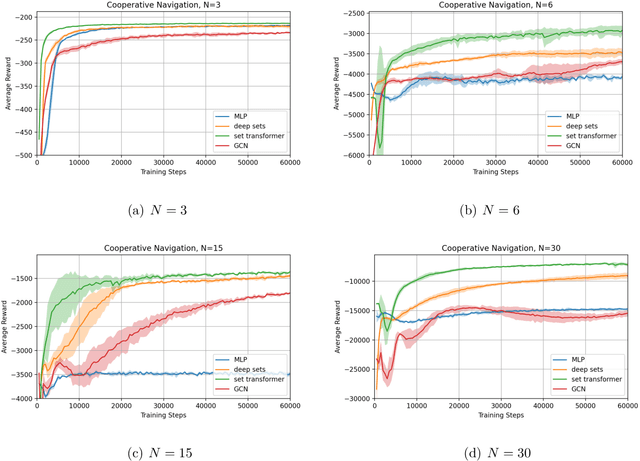
The cooperative Multi-A gent R einforcement Learning (MARL) with permutation invariant agents framework has achieved tremendous empirical successes in real-world applications. Unfortunately, the theoretical understanding of this MARL problem is lacking due to the curse of many agents and the limited exploration of the relational reasoning in existing works. In this paper, we verify that the transformer implements complex relational reasoning, and we propose and analyze model-free and model-based offline MARL algorithms with the transformer approximators. We prove that the suboptimality gaps of the model-free and model-based algorithms are independent of and logarithmic in the number of agents respectively, which mitigates the curse of many agents. These results are consequences of a novel generalization error bound of the transformer and a novel analysis of the Maximum Likelihood Estimate (MLE) of the system dynamics with the transformer. Our model-based algorithm is the first provably efficient MARL algorithm that explicitly exploits the permutation invariance of the agents.