 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaixin Wang
Improving Token-Based World Models with Parallel Observation Prediction
Feb 13, 2024
Motivated by the success of Transformers when applied to sequences of discrete symbols, token-based world models (TBWMs) were recently proposed as sample-efficient methods. In TBWMs, the world model consumes agent experience as a language-like sequence of tokens, where each observation constitutes a sub-sequence. However, during imagination, the sequential token-by-token generation of next observations results in a severe bottleneck, leading to long training times, poor GPU utilization, and limited representations. To resolve this bottleneck, we devise a novel Parallel Observation Prediction (POP) mechanism. POP augments a Retentive Network (RetNet) with a novel forward mode tailored to our reinforcement learning setting. We incorporate POP in a novel TBWM agent named REM (Retentive Environment Model), showcasing a 15.4x faster imagination compared to prior TBWMs. REM attains superhuman performance on 12 out of 26 games of the Atari 100K benchmark, while training in less than 12 hours. Our code is available at \url{https://github.com/leor-c/REM}.
C-Procgen: Empowering Procgen with Controllable Contexts
Nov 13, 2023We present C-Procgen, an enhanced suite of environments on top of the Procgen benchmark. C-Procgen provides access to over 200 unique game contexts across 16 games. It allows for detailed configuration of environments, ranging from game mechanics to agent attributes. This makes the procedural generation process, previously a black-box in Procgen, more transparent and adaptable for various research needs.The upgrade enhances dynamic context management and individualized assignments, while maintaining computational efficiency. C-Procgen's controllable contexts make it applicable in diverse reinforcement learning research areas, such as learning dynamics analysis, curriculum learning, and transfer learning. We believe that C-Procgen will fill a gap in the current literature and offer a valuable toolkit for future works.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023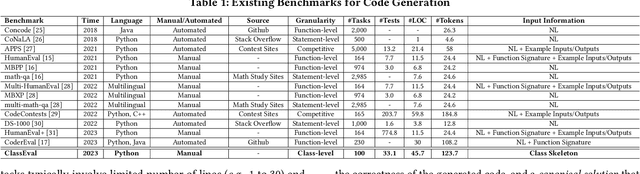


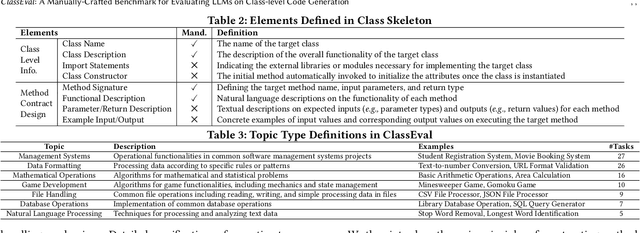
In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
Robust Reinforcement Learning via Adversarial Kernel Approximation
Jun 09, 2023



Robust Markov Decision Processes (RMDPs) provide a framework for sequential decision-making that is robust to perturbations on the transition kernel. However, robust reinforcement learning (RL) approaches in RMDPs do not scale well to realistic online settings with high-dimensional domains. By characterizing the adversarial kernel in RMDPs, we propose a novel approach for online robust RL that approximates the adversarial kernel and uses a standard (non-robust) RL algorithm to learn a robust policy. Notably, our approach can be applied on top of any underlying RL algorithm, enabling easy scaling to high-dimensional domains. Experiments in classic control tasks, MinAtar and DeepMind Control Suite demonstrate the effectiveness and the applicability of our method.
An Efficient Solution to s-Rectangular Robust Markov Decision Processes
Jan 31, 2023



We present an efficient robust value iteration for \texttt{s}-rectangular robust Markov Decision Processes (MDPs) with a time complexity comparable to standard (non-robust) MDPs which is significantly faster than any existing method. We do so by deriving the optimal robust Bellman operator in concrete forms using our $L_p$ water filling lemma. We unveil the exact form of the optimal policies, which turn out to be novel threshold policies with the probability of playing an action proportional to its advantage.
Reinforcement Learning Enhanced Weighted Sampling for Accurate Subgraph Counting on Fully Dynamic Graph Streams
Nov 13, 2022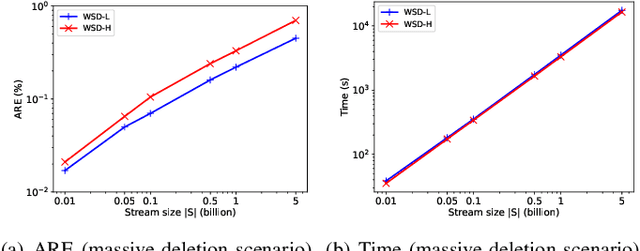

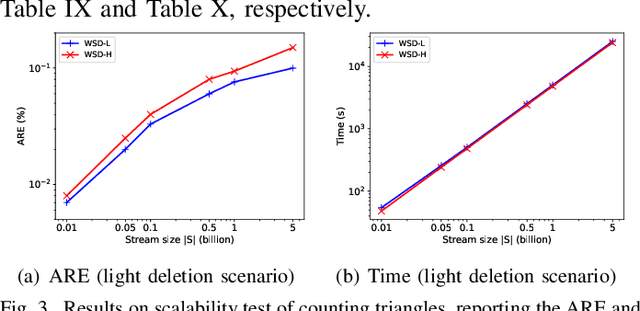

As the popularity of graph data increases, there is a growing need to count the occurrences of subgraph patterns of interest, for a variety of applications. Many graphs are massive in scale and also fully dynamic (with insertions and deletions of edges), rendering exact computation of these counts to be infeasible. Common practice is, instead, to use a small set of edges as a sample to estimate the counts. Existing sampling algorithms for fully dynamic graphs sample the edges with uniform probability. In this paper, we show that we can do much better if we sample edges based on their individual properties. Specifically, we propose a weighted sampling algorithm called WSD for estimating the subgraph count in a fully dynamic graph stream, which samples the edges based on their weights that indicate their importance and reflect their properties. We determine the weights of edges in a data-driven fashion, using a novel method based on reinforcement learning. We conduct extensive experiments to verify that our technique can produce estimates with smaller errors while often running faster compared with existing algorithms.
Reachability-Aware Laplacian Representation in Reinforcement Learning
Oct 24, 2022



In Reinforcement Learning (RL), Laplacian Representation (LapRep) is a task-agnostic state representation that encodes the geometry of the environment. A desirable property of LapRep stated in prior works is that the Euclidean distance in the LapRep space roughly reflects the reachability between states, which motivates the usage of this distance for reward shaping. However, we find that LapRep does not necessarily have this property in general: two states having small distance under LapRep can actually be far away in the environment. Such mismatch would impede the learning process in reward shaping. To fix this issue, we introduce a Reachability-Aware Laplacian Representation (RA-LapRep), by properly scaling each dimension of LapRep. Despite the simplicity, we demonstrate that RA-LapRep can better capture the inter-state reachability as compared to LapRep, through both theoretical explanations and experimental results. Additionally, we show that this improvement yields a significant boost in reward shaping performance and also benefits bottleneck state discovery.
Policy Gradient for Reinforcement Learning with General Utilities
Oct 03, 2022In Reinforcement Learning (RL), the goal of agents is to discover an optimal policy that maximizes the expected cumulative rewards. This objective may also be viewed as finding a policy that optimizes a linear function of its state-action occupancy measure, hereafter referred as Linear RL. However, many supervised and unsupervised RL problems are not covered in the Linear RL framework, such as apprenticeship learning, pure exploration and variational intrinsic control, where the objectives are non-linear functions of the occupancy measures. RL with non-linear utilities looks unwieldy, as methods like Bellman equation, value iteration, policy gradient, dynamic programming that had tremendous success in Linear RL, fail to trivially generalize. In this paper, we derive the policy gradient theorem for RL with general utilities. The policy gradient theorem proves to be a cornerstone in Linear RL due to its elegance and ease of implementability. Our policy gradient theorem for RL with general utilities shares the same elegance and ease of implementability. Based on the policy gradient theorem derived, we also present a simple sample-based algorithm. We believe our results will be of interest to the community and offer inspiration to future works in this generalized setting.
Relational Reasoning via Set Transformers: Provable Efficiency and Applications to MARL
Sep 26, 2022
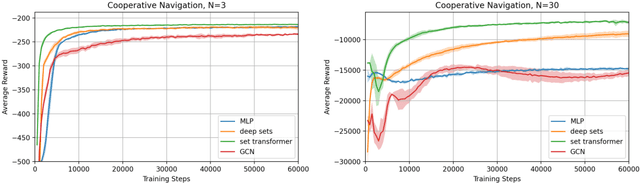
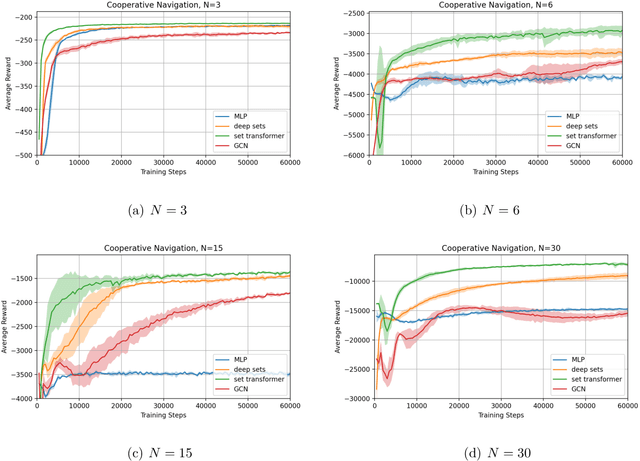
The cooperative Multi-A gent R einforcement Learning (MARL) with permutation invariant agents framework has achieved tremendous empirical successes in real-world applications. Unfortunately, the theoretical understanding of this MARL problem is lacking due to the curse of many agents and the limited exploration of the relational reasoning in existing works. In this paper, we verify that the transformer implements complex relational reasoning, and we propose and analyze model-free and model-based offline MARL algorithms with the transformer approximators. We prove that the suboptimality gaps of the model-free and model-based algorithms are independent of and logarithmic in the number of agents respectively, which mitigates the curse of many agents. These results are consequences of a novel generalization error bound of the transformer and a novel analysis of the Maximum Likelihood Estimate (MLE) of the system dynamics with the transformer. Our model-based algorithm is the first provably efficient MARL algorithm that explicitly exploits the permutation invariance of the agents.
Efficient Policy Iteration for Robust Markov Decision Processes via Regularization
May 28, 2022

Robust Markov decision processes (MDPs) provide a general framework to model decision problems where the system dynamics are changing or only partially known. Recent work established the equivalence between \texttt{s} rectangular $L_p$ robust MDPs and regularized MDPs, and derived a regularized policy iteration scheme that enjoys the same level of efficiency as standard MDPs. However, there lacks a clear understanding of the policy improvement step. For example, we know the greedy policy can be stochastic but have little clue how each action affects this greedy policy. In this work, we focus on the policy improvement step and derive concrete forms for the greedy policy and the optimal robust Bellman operators. We find that the greedy policy is closely related to some combination of the top $k$ actions, which provides a novel characterization of its stochasticity. The exact nature of the combination depends on the shape of the uncertainty set. Furthermore, our results allow us to efficiently compute the policy improvement step by a simple binary search, without turning to an external optimization subroutine. Moreover, for $L_1, L_2$, and $L_\infty$ robust MDPs, we can even get rid of the binary search and evaluate the optimal robust Bellman operators exactly. Our work greatly extends existing results on solving \texttt{s}-rectangular $L_p$ robust MDPs via regularized policy iteration and can be readily adapted to sample-based model-free algorithms.