 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Peng
Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Apr 05, 2024
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
A general approach to enhance the survivability of backdoor attacks by decision path coupling
Mar 05, 2024



Backdoor attacks have been one of the emerging security threats to deep neural networks (DNNs), leading to serious consequences. One of the mainstream backdoor defenses is model reconstruction-based. Such defenses adopt model unlearning or pruning to eliminate backdoors. However, little attention has been paid to survive from such defenses. To bridge the gap, we propose Venom, the first generic backdoor attack enhancer to improve the survivability of existing backdoor attacks against model reconstruction-based defenses. We formalize Venom as a binary-task optimization problem. The first is the original backdoor attack task to preserve the original attack capability, while the second is the attack enhancement task to improve the attack survivability. To realize the second task, we propose attention imitation loss to force the decision path of poisoned samples in backdoored models to couple with the crucial decision path of benign samples, which makes backdoors difficult to eliminate. Our extensive evaluation on two DNNs and three datasets has demonstrated that Venom significantly improves the survivability of eight state-of-the-art attacks against eight state-of-the-art defenses without impacting the capability of the original attacks.
Tight Fusion of Events and Inertial Measurements for Direct Velocity Estimation
Jan 17, 2024Traditional visual-inertial state estimation targets absolute camera poses and spatial landmark locations while first-order kinematics are typically resolved as an implicitly estimated sub-state. However, this poses a risk in velocity-based control scenarios, as the quality of the estimation of kinematics depends on the stability of absolute camera and landmark coordinates estimation. To address this issue, we propose a novel solution to tight visual-inertial fusion directly at the level of first-order kinematics by employing a dynamic vision sensor instead of a normal camera. More specifically, we leverage trifocal tensor geometry to establish an incidence relation that directly depends on events and camera velocity, and demonstrate how velocity estimates in highly dynamic situations can be obtained over short time intervals. Noise and outliers are dealt with using a nested two-layer RANSAC scheme. Additionally, smooth velocity signals are obtained from a tight fusion with pre-integrated inertial signals using a sliding window optimizer. Experiments on both simulated and real data demonstrate that the proposed tight event-inertial fusion leads to continuous and reliable velocity estimation in highly dynamic scenarios independently of absolute coordinates. Furthermore, in extreme cases, it achieves more stable and more accurate estimation of kinematics than traditional, point-position-based visual-inertial odometry.
Event-Based Visual Odometry on Non-Holonomic Ground Vehicles
Jan 17, 2024Despite the promise of superior performance under challenging conditions, event-based motion estimation remains a hard problem owing to the difficulty of extracting and tracking stable features from event streams. In order to robustify the estimation, it is generally believed that fusion with other sensors is a requirement. In this work, we demonstrate reliable, purely event-based visual odometry on planar ground vehicles by employing the constrained non-holonomic motion model of Ackermann steering platforms. We extend single feature n-linearities for regular frame-based cameras to the case of quasi time-continuous event-tracks, and achieve a polynomial form via variable degree Taylor expansions. Robust averaging over multiple event tracks is simply achieved via histogram voting. As demonstrated on both simulated and real data, our algorithm achieves accurate and robust estimates of the vehicle's instantaneous rotational velocity, and thus results that are comparable to the delta rotations obtained by frame-based sensors under normal conditions. We furthermore significantly outperform the more traditional alternatives in challenging illumination scenarios. The code is available at \url{https://github.com/gowanting/NHEVO}.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Resolving Crash Bugs via Large Language Models: An Empirical Study
Dec 16, 2023Crash bugs cause unexpected program behaviors or even termination, requiring high-priority resolution. However, manually resolving crash bugs is challenging and labor-intensive, and researchers have proposed various techniques for their automated localization and repair. ChatGPT, a recent large language model (LLM), has garnered significant attention due to its exceptional performance across various domains. This work performs the first investigation into ChatGPT's capability in resolve real-world crash bugs, focusing on its effectiveness in both localizing and repairing code-related and environment-related crash bugs. Specifically, we initially assess ChatGPT's fundamental ability to resolve crash bugs with basic prompts in a single iteration. We observe that ChatGPT performs better at resolving code-related crash bugs compared to environment-related ones, and its primary challenge in resolution lies in inaccurate localization. Additionally, we explore ChatGPT's potential with various advanced prompts. Furthermore, by stimulating ChatGPT's self-planning, it methodically investigates each potential crash-causing environmental factor through proactive inquiry, ultimately identifying the root cause of the crash. Based on our findings, we propose IntDiagSolver, an interaction methodology designed to facilitate precise crash bug resolution through continuous interaction with LLMs. Evaluating IntDiagSolver on multiple LLMs reveals consistent enhancement in the accuracy of crash bug resolution, including ChatGPT, Claude, and CodeLlama.
Enhancing Robot Program Synthesis Through Environmental Context
Dec 13, 2023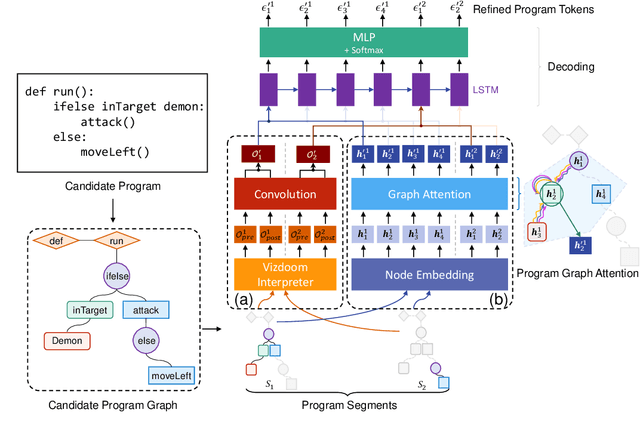
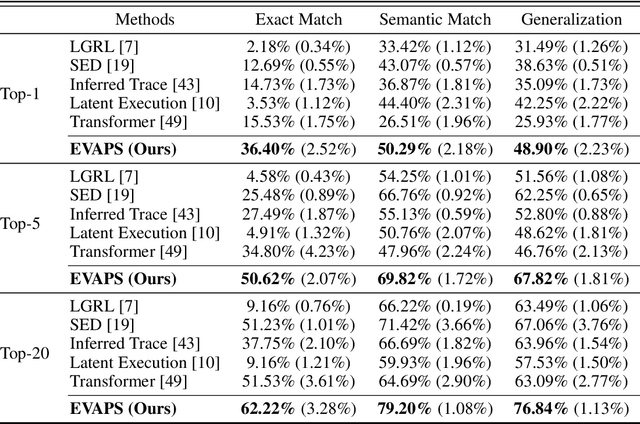
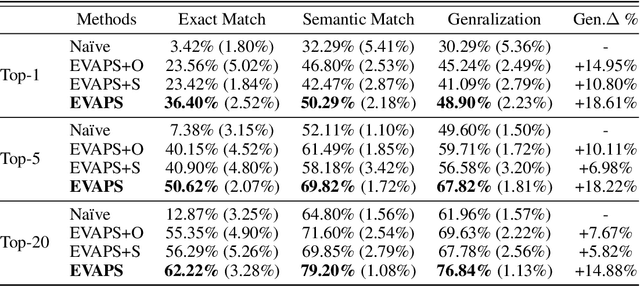
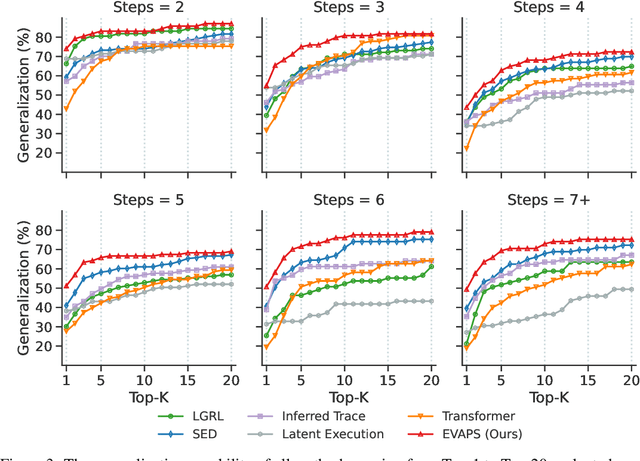
Program synthesis aims to automatically generate an executable program that conforms to the given specification. Recent advancements have demonstrated that deep neural methodologies and large-scale pretrained language models are highly proficient in capturing program semantics. For robot programming, prior works have facilitated program synthesis by incorporating global environments. However, the assumption of acquiring a comprehensive understanding of the entire environment is often excessively challenging to achieve. In this work, we present a framework that learns to synthesize a program by rectifying potentially erroneous code segments, with the aid of partially observed environments. To tackle the issue of inadequate attention to partial observations, we propose to first learn an environment embedding space that can implicitly evaluate the impacts of each program token based on the precondition. Furthermore, by employing a graph structure, the model can aggregate both environmental and syntactic information flow and furnish smooth program rectification guidance. Extensive experimental evaluations and ablation studies on the partially observed VizDoom domain authenticate that our method offers superior generalization capability across various tasks and greater robustness when encountering noises.
OpenGCD: Assisting Open World Recognition with Generalized Category Discovery
Aug 14, 2023



A desirable open world recognition (OWR) system requires performing three tasks: (1) Open set recognition (OSR), i.e., classifying the known (classes seen during training) and rejecting the unknown (unseen$/$novel classes) online; (2) Grouping and labeling these unknown as novel known classes; (3) Incremental learning (IL), i.e., continual learning these novel classes and retaining the memory of old classes. Ideally, all of these steps should be automated. However, existing methods mostly assume that the second task is completely done manually. To bridge this gap, we propose OpenGCD that combines three key ideas to solve the above problems sequentially: (a) We score the origin of instances (unknown or specifically known) based on the uncertainty of the classifier's prediction; (b) For the first time, we introduce generalized category discovery (GCD) techniques in OWR to assist humans in grouping unlabeled data; (c) For the smooth execution of IL and GCD, we retain an equal number of informative exemplars for each class with diversity as the goal. Moreover, we present a new performance evaluation metric for GCD called harmonic clustering accuracy. Experiments on two standard classification benchmarks and a challenging dataset demonstrate that OpenGCD not only offers excellent compatibility but also substantially outperforms other baselines. Code: https://github.com/Fulin-Gao/OpenGCD.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023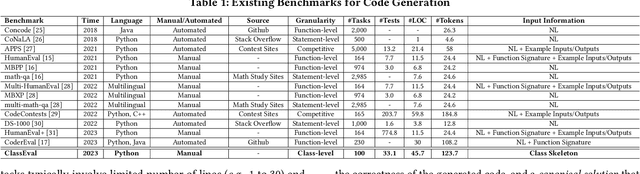


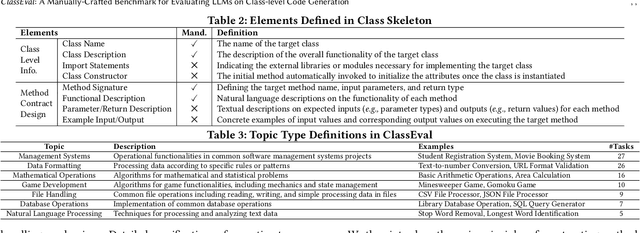
In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
Evaluating Instruction-Tuned Large Language Models on Code Comprehension and Generation
Aug 02, 2023In this work, we evaluate 10 open-source instructed LLMs on four representative code comprehension and generation tasks. We have the following main findings. First, for the zero-shot setting, instructed LLMs are very competitive on code comprehension and generation tasks and sometimes even better than small SOTA models specifically fine-tuned on each downstream task. We also find that larger instructed LLMs are not always better on code-related tasks. Second, for the few-shot setting, we find that adding demonstration examples substantially helps instructed LLMs perform better on most code comprehension and generation tasks; however, the examples would sometimes induce unstable or even worse performance. Furthermore, we find widely-used BM25-based shot selection strategy significantly outperforms the basic random selection or fixed selection only on generation problems. Third, for the fine-tuning setting, we find that fine-tuning could further improve the model performance on downstream code comprehension and generation tasks compared to the zero-shot/one-shot performance. In addition, after being fine-tuned on the same downstream task dataset, instructed LLMs outperform both the small SOTA models and similar-scaled LLMs without instruction tuning. Based on our findings, we further present practical implications on model and usage recommendation, performance and cost trade-offs, and future direction.