 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongyu Liu
Intelligent Diagnosis of Alzheimer's Disease Based on Machine Learning
Feb 13, 2024
This study is based on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and aims to explore early detection and disease progression in Alzheimer's disease (AD). We employ innovative data preprocessing strategies, including the use of the random forest algorithm to fill missing data and the handling of outliers and invalid data, thereby fully mining and utilizing these limited data resources. Through Spearman correlation coefficient analysis, we identify some features strongly correlated with AD diagnosis. We build and test three machine learning models using these features: random forest, XGBoost, and support vector machine (SVM). Among them, the XGBoost model performs the best in terms of diagnostic performance, achieving an accuracy of 91%. Overall, this study successfully overcomes the challenge of missing data and provides valuable insights into early detection of Alzheimer's disease, demonstrating its unique research value and practical significance.
A Risk-aware Planning Framework of UGVs in Off-Road Environment
Feb 04, 2024Planning module is an essential component of intelligent vehicle study. In this paper, we address the risk-aware planning problem of UGVs through a global-local planning framework which seamlessly integrates risk assessment methods. In particular, a global planning algorithm named Coarse2fine A* is proposed, which incorporates a potential field approach to enhance the safety of the planning results while ensuring the efficiency of the algorithm. A deterministic sampling method for local planning is leveraged and modified to suit off-road environment. It also integrates a risk assessment model to emphasize the avoidance of local risks. The performance of the algorithm is demonstrated through simulation experiments by comparing it with baseline algorithms, where the results of Coarse2fine A* are shown to be approximately 30% safer than those of the baseline algorithms. The practicality and effectiveness of the proposed planning framework are validated by deploying it on a real-world system consisting of a control center and a practical UGV platform.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
HeadArtist: Text-conditioned 3D Head Generation with Self Score Distillation
Dec 12, 2023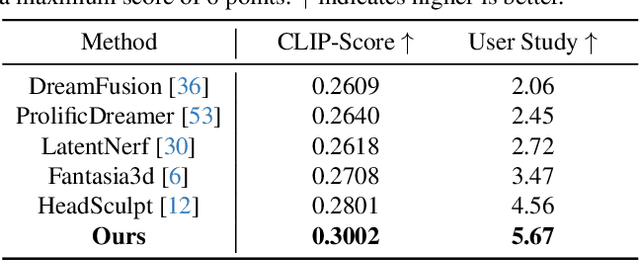
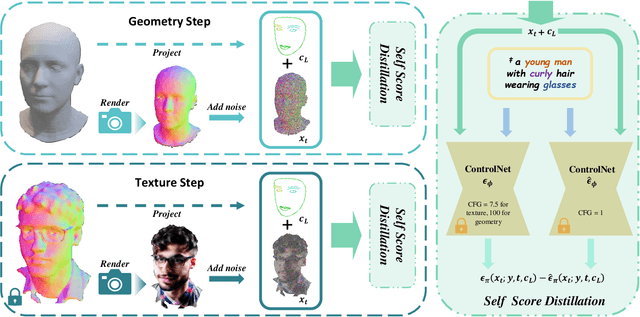


This work presents HeadArtist for 3D head generation from text descriptions. With a landmark-guided ControlNet serving as the generative prior, we come up with an efficient pipeline that optimizes a parameterized 3D head model under the supervision of the prior distillation itself. We call such a process self score distillation (SSD). In detail, given a sampled camera pose, we first render an image and its corresponding landmarks from the head model, and add some particular level of noise onto the image. The noisy image, landmarks, and text condition are then fed into the frozen ControlNet twice for noise prediction. Two different classifier-free guidance (CFG) weights are applied during these two predictions, and the prediction difference offers a direction on how the rendered image can better match the text of interest. Experimental results suggest that our approach delivers high-quality 3D head sculptures with adequate geometry and photorealistic appearance, significantly outperforming state-ofthe-art methods. We also show that the same pipeline well supports editing the generated heads, including both geometry deformation and appearance change.
CAD: Photorealistic 3D Generation via Adversarial Distillation
Dec 11, 2023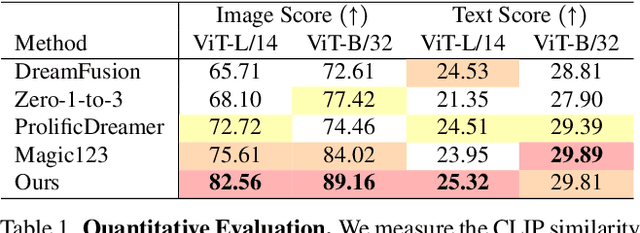
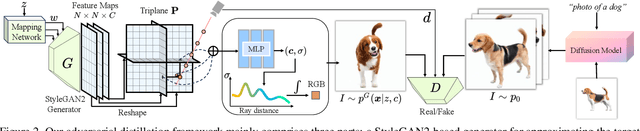
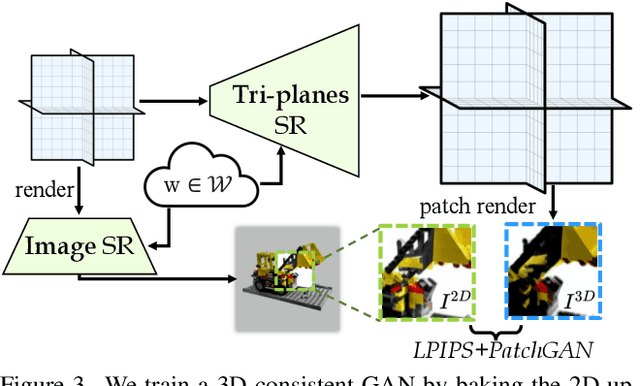

The increased demand for 3D data in AR/VR, robotics and gaming applications, gave rise to powerful generative pipelines capable of synthesizing high-quality 3D objects. Most of these models rely on the Score Distillation Sampling (SDS) algorithm to optimize a 3D representation such that the rendered image maintains a high likelihood as evaluated by a pre-trained diffusion model. However, finding a correct mode in the high-dimensional distribution produced by the diffusion model is challenging and often leads to issues such as over-saturation, over-smoothing, and Janus-like artifacts. In this paper, we propose a novel learning paradigm for 3D synthesis that utilizes pre-trained diffusion models. Instead of focusing on mode-seeking, our method directly models the distribution discrepancy between multi-view renderings and diffusion priors in an adversarial manner, which unlocks the generation of high-fidelity and photorealistic 3D content, conditioned on a single image and prompt. Moreover, by harnessing the latent space of GANs and expressive diffusion model priors, our method facilitates a wide variety of 3D applications including single-view reconstruction, high diversity generation and continuous 3D interpolation in the open domain. The experiments demonstrate the superiority of our pipeline compared to previous works in terms of generation quality and diversity.
Point-aware Interaction and CNN-induced Refinement Network for RGB-D Salient Object Detection
Aug 17, 2023
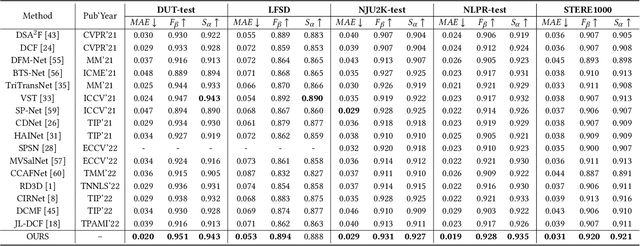

By integrating complementary information from RGB image and depth map, the ability of salient object detection (SOD) for complex and challenging scenes can be improved. In recent years, the important role of Convolutional Neural Networks (CNNs) in feature extraction and cross-modality interaction has been fully explored, but it is still insufficient in modeling global long-range dependencies of self-modality and cross-modality. To this end, we introduce CNNs-assisted Transformer architecture and propose a novel RGB-D SOD network with Point-aware Interaction and CNN-induced Refinement (PICR-Net). On the one hand, considering the prior correlation between RGB modality and depth modality, an attention-triggered cross-modality point-aware interaction (CmPI) module is designed to explore the feature interaction of different modalities with positional constraints. On the other hand, in order to alleviate the block effect and detail destruction problems brought by the Transformer naturally, we design a CNN-induced refinement (CNNR) unit for content refinement and supplementation. Extensive experiments on five RGB-D SOD datasets show that the proposed network achieves competitive results in both quantitative and qualitative comparisons.
XFormer: Fast and Accurate Monocular 3D Body Capture
May 18, 2023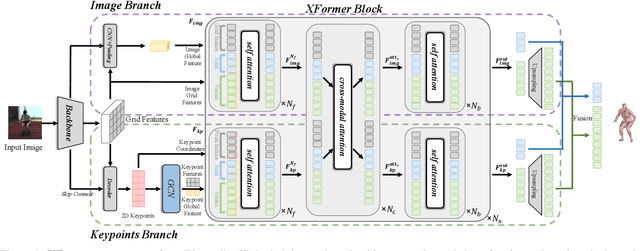
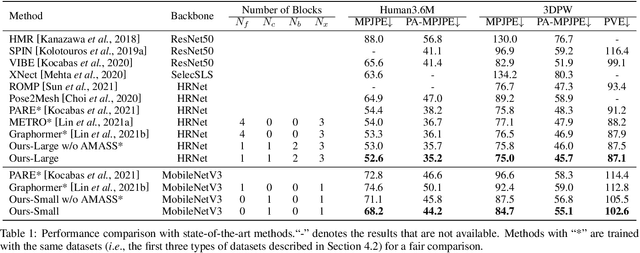
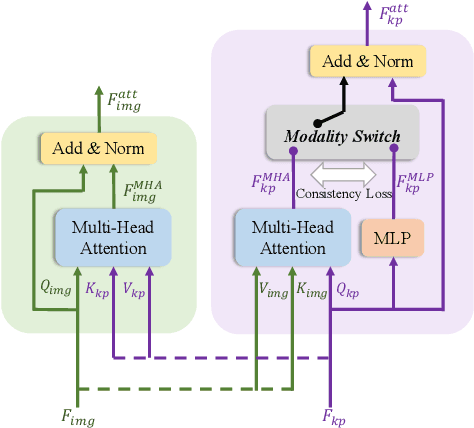
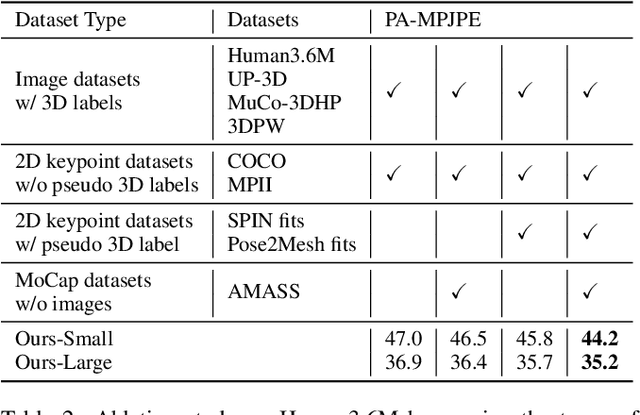
We present XFormer, a novel human mesh and motion capture method that achieves real-time performance on consumer CPUs given only monocular images as input. The proposed network architecture contains two branches: a keypoint branch that estimates 3D human mesh vertices given 2D keypoints, and an image branch that makes predictions directly from the RGB image features. At the core of our method is a cross-modal transformer block that allows information to flow across these two branches by modeling the attention between 2D keypoint coordinates and image spatial features. Our architecture is smartly designed, which enables us to train on various types of datasets including images with 2D/3D annotations, images with 3D pseudo labels, and motion capture datasets that do not have associated images. This effectively improves the accuracy and generalization ability of our system. Built on a lightweight backbone (MobileNetV3), our method runs blazing fast (over 30fps on a single CPU core) and still yields competitive accuracy. Furthermore, with an HRNet backbone, XFormer delivers state-of-the-art performance on Huamn3.6 and 3DPW datasets.
Make Encoder Great Again in 3D GAN Inversion through Geometry and Occlusion-Aware Encoding
Mar 22, 2023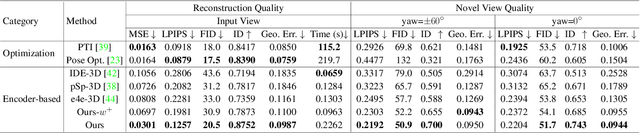
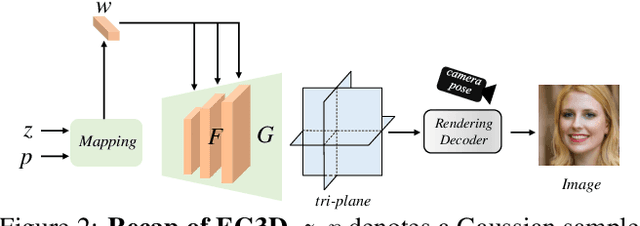


3D GAN inversion aims to achieve high reconstruction fidelity and reasonable 3D geometry simultaneously from a single image input. However, existing 3D GAN inversion methods rely on time-consuming optimization for each individual case. In this work, we introduce a novel encoder-based inversion framework based on EG3D, one of the most widely-used 3D GAN models. We leverage the inherent properties of EG3D's latent space to design a discriminator and a background depth regularization. This enables us to train a geometry-aware encoder capable of converting the input image into corresponding latent code. Additionally, we explore the feature space of EG3D and develop an adaptive refinement stage that improves the representation ability of features in EG3D to enhance the recovery of fine-grained textural details. Finally, we propose an occlusion-aware fusion operation to prevent distortion in unobserved regions. Our method achieves impressive results comparable to optimization-based methods while operating up to 500 times faster. Our framework is well-suited for applications such as semantic editing.
Human MotionFormer: Transferring Human Motions with Vision Transformers
Feb 25, 2023
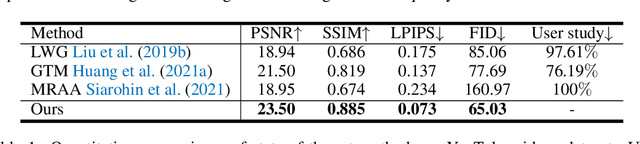
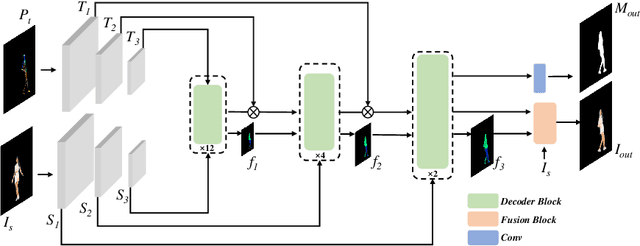
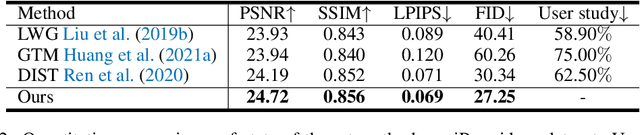
Human motion transfer aims to transfer motions from a target dynamic person to a source static one for motion synthesis. An accurate matching between the source person and the target motion in both large and subtle motion changes is vital for improving the transferred motion quality. In this paper, we propose Human MotionFormer, a hierarchical ViT framework that leverages global and local perceptions to capture large and subtle motion matching, respectively. It consists of two ViT encoders to extract input features (i.e., a target motion image and a source human image) and a ViT decoder with several cascaded blocks for feature matching and motion transfer. In each block, we set the target motion feature as Query and the source person as Key and Value, calculating the cross-attention maps to conduct a global feature matching. Further, we introduce a convolutional layer to improve the local perception after the global cross-attention computations. This matching process is implemented in both warping and generation branches to guide the motion transfer. During training, we propose a mutual learning loss to enable the co-supervision between warping and generation branches for better motion representations. Experiments show that our Human MotionFormer sets the new state-of-the-art performance both qualitatively and quantitatively. Project page: \url{https://github.com/KumapowerLIU/Human-MotionFormer}
Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint
Nov 21, 2022
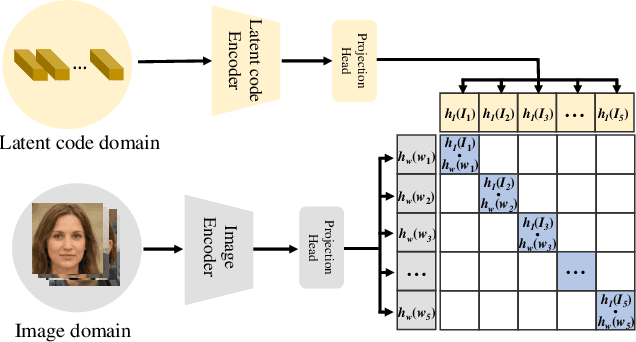
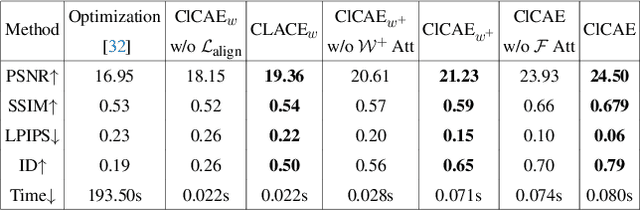
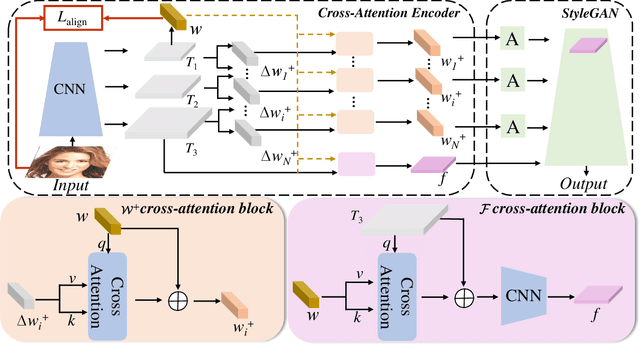
GAN inversion and editing via StyleGAN maps an input image into the embedding spaces ($\mathcal{W}$, $\mathcal{W^+}$, and $\mathcal{F}$) to simultaneously maintain image fidelity and meaningful manipulation. From latent space $\mathcal{W}$ to extended latent space $\mathcal{W^+}$ to feature space $\mathcal{F}$ in StyleGAN, the editability of GAN inversion decreases while its reconstruction quality increases. Recent GAN inversion methods typically explore $\mathcal{W^+}$ and $\mathcal{F}$ rather than $\mathcal{W}$ to improve reconstruction fidelity while maintaining editability. As $\mathcal{W^+}$ and $\mathcal{F}$ are derived from $\mathcal{W}$ that is essentially the foundation latent space of StyleGAN, these GAN inversion methods focusing on $\mathcal{W^+}$ and $\mathcal{F}$ spaces could be improved by stepping back to $\mathcal{W}$. In this work, we propose to first obtain the precise latent code in foundation latent space $\mathcal{W}$. We introduce contrastive learning to align $\mathcal{W}$ and the image space for precise latent code discovery. %The obtaining process is by using contrastive learning to align $\mathcal{W}$ and the image space. Then, we leverage a cross-attention encoder to transform the obtained latent code in $\mathcal{W}$ into $\mathcal{W^+}$ and $\mathcal{F}$, accordingly. Our experiments show that our exploration of the foundation latent space $\mathcal{W}$ improves the representation ability of latent codes in $\mathcal{W^+}$ and features in $\mathcal{F}$, which yields state-of-the-art reconstruction fidelity and editability results on the standard benchmarks. Project page: \url{https://github.com/KumapowerLIU/CLCAE}.