 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiming Zhu
APT-Pipe: An Automatic Prompt-Tuning Tool for Social Computing Data Annotation
Feb 08, 2024
Recent research has highlighted the potential of LLM applications, like ChatGPT, for performing label annotation on social computing text. However, it is already well known that performance hinges on the quality of the input prompts. To address this, there has been a flurry of research into prompt tuning -- techniques and guidelines that attempt to improve the quality of prompts. Yet these largely rely on manual effort and prior knowledge of the dataset being annotated. To address this limitation, we propose APT-Pipe, an automated prompt-tuning pipeline. APT-Pipe aims to automatically tune prompts to enhance ChatGPT's text classification performance on any given dataset. We implement APT-Pipe and test it across twelve distinct text classification datasets. We find that prompts tuned by APT-Pipe help ChatGPT achieve higher weighted F1-score on nine out of twelve experimented datasets, with an improvement of 7.01% on average. We further highlight APT-Pipe's flexibility as a framework by showing how it can be extended to support additional tuning mechanisms.
Ammonia-Net: A Multi-task Joint Learning Model for Multi-class Segmentation and Classification in Tooth-marked Tongue Diagnosis
Oct 05, 2023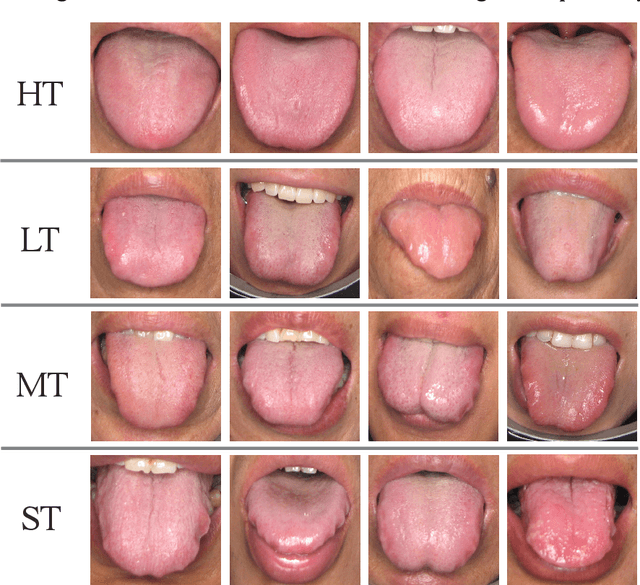

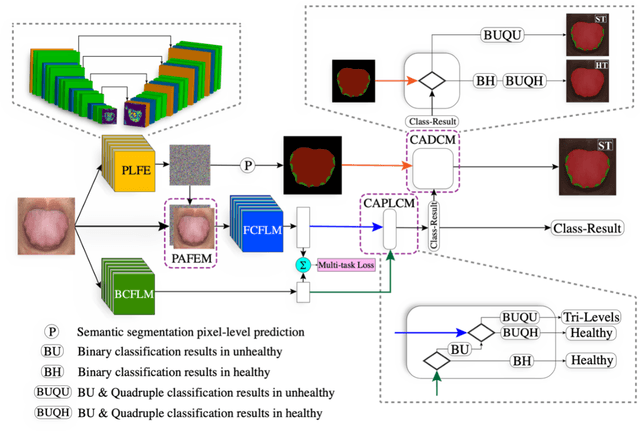
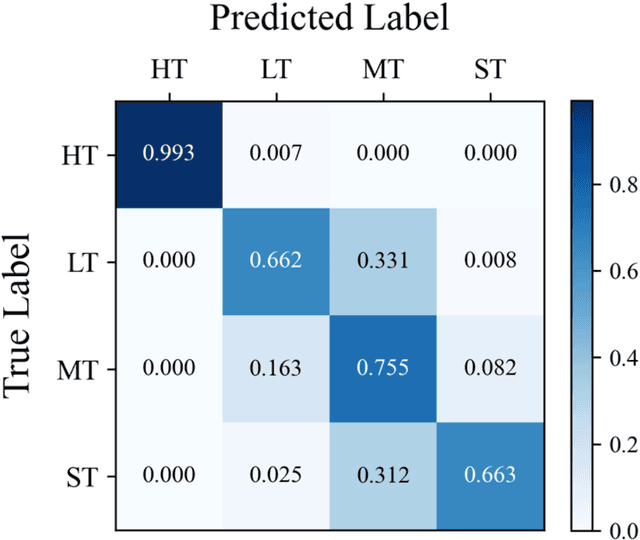
In Traditional Chinese Medicine, the tooth marks on the tongue, stemming from prolonged dental pressure, serve as a crucial indicator for assessing qi (yang) deficiency, which is intrinsically linked to visceral health. Manual diagnosis of tooth-marked tongue solely relies on experience. Nonetheless, the diversity in shape, color, and type of tooth marks poses a challenge to diagnostic accuracy and consistency. To address these problems, herein we propose a multi-task joint learning model named Ammonia-Net. This model employs a convolutional neural network-based architecture, specifically designed for multi-class segmentation and classification of tongue images. Ammonia-Net performs semantic segmentation of tongue images to identify tongue and tooth marks. With the assistance of segmentation output, it classifies the images into the desired number of classes: healthy tongue, light tongue, moderate tongue, and severe tongue. As far as we know, this is the first attempt to apply the semantic segmentation results of tooth marks for tooth-marked tongue classification. To train Ammonia-Net, we collect 856 tongue images from 856 subjects. After a number of extensive experiments, the experimental results show that the proposed model achieves 99.06% accuracy in the two-class classification task of tooth-marked tongue identification and 80.02%. As for the segmentation task, mIoU for tongue and tooth marks amounts to 71.65%.
Can ChatGPT Reproduce Human-Generated Labels? A Study of Social Computing Tasks
Apr 22, 2023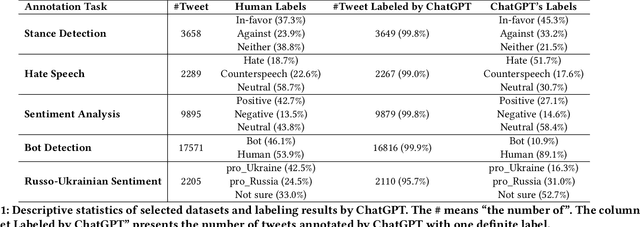
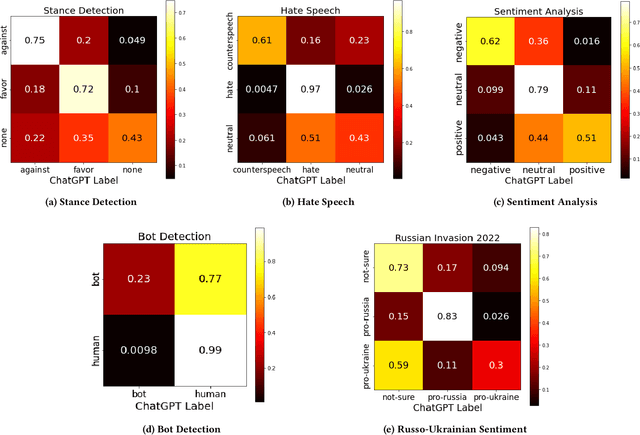

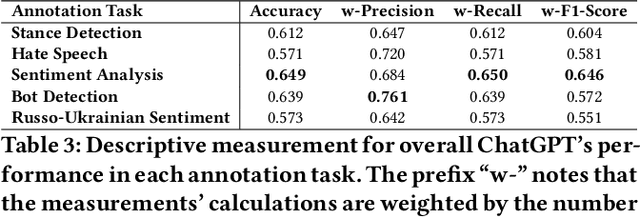
The release of ChatGPT has uncovered a range of possibilities whereby large language models (LLMs) can substitute human intelligence. In this paper, we seek to understand whether ChatGPT has the potential to reproduce human-generated label annotations in social computing tasks. Such an achievement could significantly reduce the cost and complexity of social computing research. As such, we use ChatGPT to relabel five seminal datasets covering stance detection (2x), sentiment analysis, hate speech, and bot detection. Our results highlight that ChatGPT does have the potential to handle these data annotation tasks, although a number of challenges remain. ChatGPT obtains an average accuracy 0.609. Performance is highest for the sentiment analysis dataset, with ChatGPT correctly annotating 64.9% of tweets. Yet, we show that performance varies substantially across individual labels. We believe this work can open up new lines of analysis and act as a basis for future research into the exploitation of ChatGPT for human annotation tasks.
Make Encoder Great Again in 3D GAN Inversion through Geometry and Occlusion-Aware Encoding
Mar 22, 2023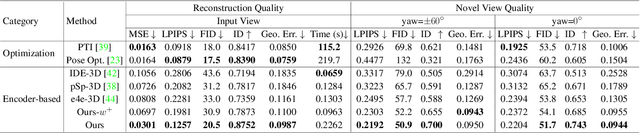
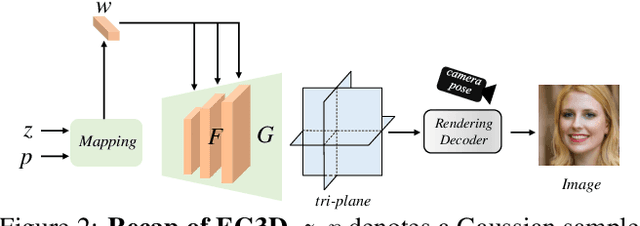


3D GAN inversion aims to achieve high reconstruction fidelity and reasonable 3D geometry simultaneously from a single image input. However, existing 3D GAN inversion methods rely on time-consuming optimization for each individual case. In this work, we introduce a novel encoder-based inversion framework based on EG3D, one of the most widely-used 3D GAN models. We leverage the inherent properties of EG3D's latent space to design a discriminator and a background depth regularization. This enables us to train a geometry-aware encoder capable of converting the input image into corresponding latent code. Additionally, we explore the feature space of EG3D and develop an adaptive refinement stage that improves the representation ability of features in EG3D to enhance the recovery of fine-grained textural details. Finally, we propose an occlusion-aware fusion operation to prevent distortion in unobserved regions. Our method achieves impressive results comparable to optimization-based methods while operating up to 500 times faster. Our framework is well-suited for applications such as semantic editing.
One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations
Oct 17, 2022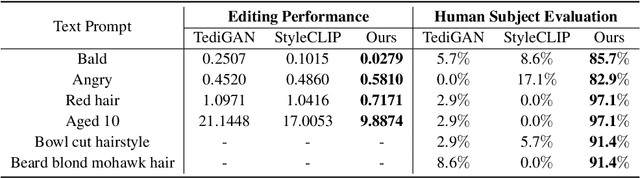
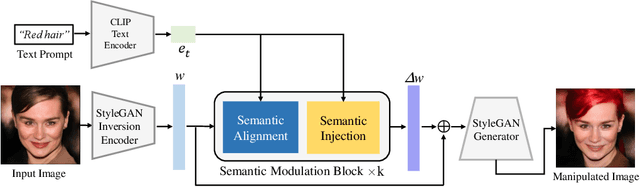
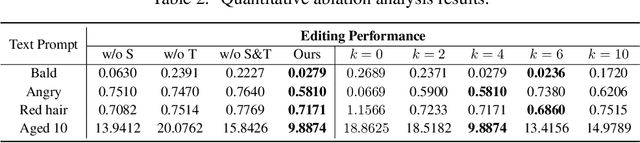
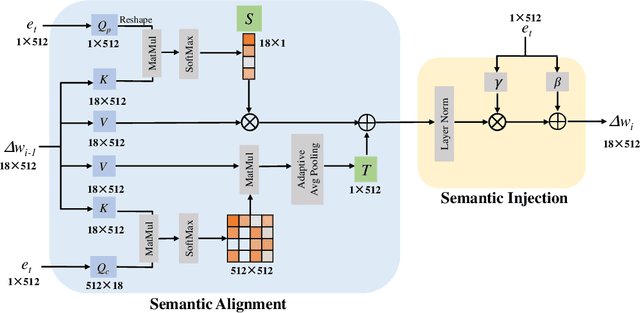
Free-form text prompts allow users to describe their intentions during image manipulation conveniently. Based on the visual latent space of StyleGAN[21] and text embedding space of CLIP[34], studies focus on how to map these two latent spaces for text-driven attribute manipulations. Currently, the latent mapping between these two spaces is empirically designed and confines that each manipulation model can only handle one fixed text prompt. In this paper, we propose a method named Free-Form CLIP (FFCLIP), aiming to establish an automatic latent mapping so that one manipulation model handles free-form text prompts. Our FFCLIP has a cross-modality semantic modulation module containing semantic alignment and injection. The semantic alignment performs the automatic latent mapping via linear transformations with a cross attention mechanism. After alignment, we inject semantics from text prompt embeddings to the StyleGAN latent space. For one type of image (e.g., `human portrait'), one FFCLIP model can be learned to handle free-form text prompts. Meanwhile, we observe that although each training text prompt only contains a single semantic meaning, FFCLIP can leverage text prompts with multiple semantic meanings for image manipulation. In the experiments, we evaluate FFCLIP on three types of images (i.e., `human portraits', `cars', and `churches'). Both visual and numerical results show that FFCLIP effectively produces semantically accurate and visually realistic images. Project page: https://github.com/KumapowerLIU/FFCLIP.
DynaMixer: A Vision MLP Architecture with Dynamic Mixing
Feb 16, 2022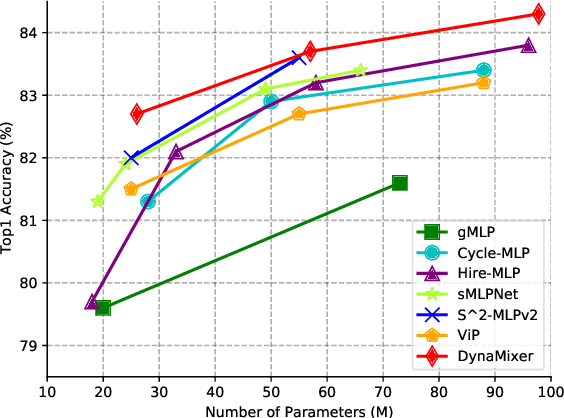
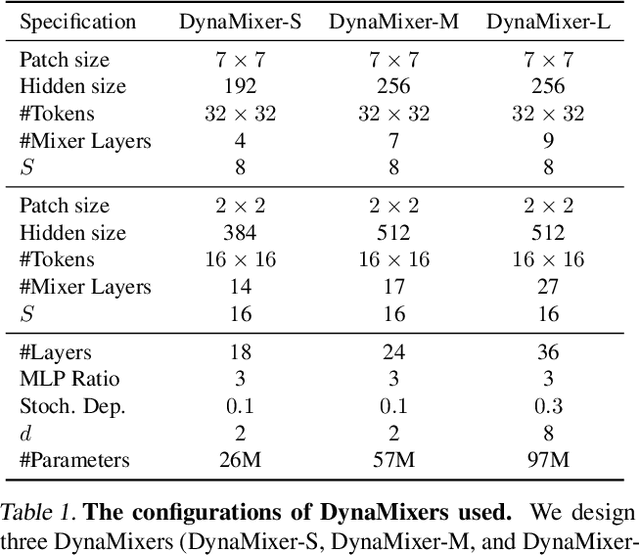
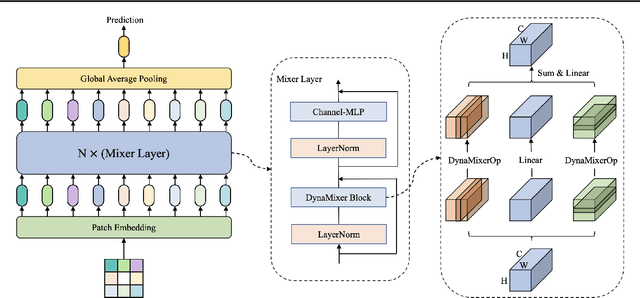
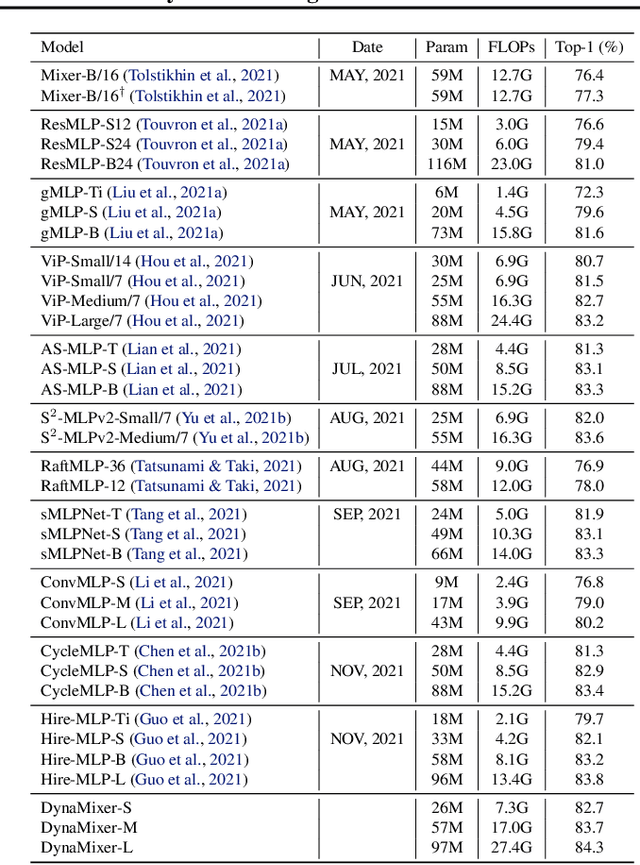
Recently, MLP-like vision models have achieved promising performances on mainstream visual recognition tasks. In contrast with vision transformers and CNNs, the success of MLP-like models shows that simple information fusion operations among tokens and channels can yield a good representation power for deep recognition models. However, existing MLP-like models fuse tokens through static fusion operations, lacking adaptability to the contents of the tokens to be mixed. Thus, customary information fusion procedures are not effective enough. To this end, this paper presents an efficient MLP-like network architecture, dubbed DynaMixer, resorting to dynamic information fusion. Critically, we propose a procedure, on which the DynaMixer model relies, to dynamically generate mixing matrices by leveraging the contents of all the tokens to be mixed. To reduce the time complexity and improve the robustness, a dimensionality reduction technique and a multi-segment fusion mechanism are adopted. Our proposed DynaMixer model (97M parameters) achieves 84.3\% top-1 accuracy on the ImageNet-1K dataset without extra training data, performing favorably against the state-of-the-art vision MLP models. When the number of parameters is reduced to 26M, it still achieves 82.7\% top-1 accuracy, surpassing the existing MLP-like models with a similar capacity. The implementation of DynaMixer will be made available to the public.