 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGareth Tyson
Decentralised Moderation for Interoperable Social Networks: A Conversation-based Approach for Pleroma and the Fediverse
Apr 03, 2024
The recent development of decentralised and interoperable social networks (such as the "fediverse") creates new challenges for content moderators. This is because millions of posts generated on one server can easily "spread" to another, even if the recipient server has very different moderation policies. An obvious solution would be to leverage moderation tools to automatically tag (and filter) posts that contravene moderation policies, e.g. related to toxic speech. Recent work has exploited the conversational context of a post to improve this automatic tagging, e.g. using the replies to a post to help classify if it contains toxic speech. This has shown particular potential in environments with large training sets that contain complete conversations. This, however, creates challenges in a decentralised context, as a single conversation may be fragmented across multiple servers. Thus, each server only has a partial view of an entire conversation because conversations are often federated across servers in a non-synchronized fashion. To address this, we propose a decentralised conversation-aware content moderation approach suitable for the fediverse. Our approach employs a graph deep learning model (GraphNLI) trained locally on each server. The model exploits local data to train a model that combines post and conversational information captured through random walks to detect toxicity. We evaluate our approach with data from Pleroma, a major decentralised and interoperable micro-blogging network containing 2 million conversations. Our model effectively detects toxicity on larger instances, exclusively trained using their local post information (0.8837 macro-F1). Our approach has considerable scope to improve moderation in decentralised and interoperable social networks such as Pleroma or Mastodon.
APT-Pipe: An Automatic Prompt-Tuning Tool for Social Computing Data Annotation
Feb 08, 2024Recent research has highlighted the potential of LLM applications, like ChatGPT, for performing label annotation on social computing text. However, it is already well known that performance hinges on the quality of the input prompts. To address this, there has been a flurry of research into prompt tuning -- techniques and guidelines that attempt to improve the quality of prompts. Yet these largely rely on manual effort and prior knowledge of the dataset being annotated. To address this limitation, we propose APT-Pipe, an automated prompt-tuning pipeline. APT-Pipe aims to automatically tune prompts to enhance ChatGPT's text classification performance on any given dataset. We implement APT-Pipe and test it across twelve distinct text classification datasets. We find that prompts tuned by APT-Pipe help ChatGPT achieve higher weighted F1-score on nine out of twelve experimented datasets, with an improvement of 7.01% on average. We further highlight APT-Pipe's flexibility as a framework by showing how it can be extended to support additional tuning mechanisms.
Lady and the Tramp Nextdoor: Online Manifestations of Economic Inequalities in the Nextdoor Social Network
Apr 26, 2023



From health to education, income impacts a huge range of life choices. Earlier research has leveraged data from online social networks to study precisely this impact. In this paper, we ask the opposite question: do different levels of income result in different online behaviors? We demonstrate it does. We present the first large-scale study of Nextdoor, a popular location-based social network. We collect 2.6 Million posts from 64,283 neighborhoods in the United States and 3,325 neighborhoods in the United Kingdom, to examine whether online discourse reflects the income and income inequality of a neighborhood. We show that posts from neighborhoods with different incomes indeed differ, e.g. richer neighborhoods have a more positive sentiment and discuss crimes more, even though their actual crime rates are much lower. We then show that user-generated content can predict both income and inequality. We train multiple machine learning models and predict both income (R-squared=0.841) and inequality (R-squared=0.77).
Can ChatGPT Reproduce Human-Generated Labels? A Study of Social Computing Tasks
Apr 22, 2023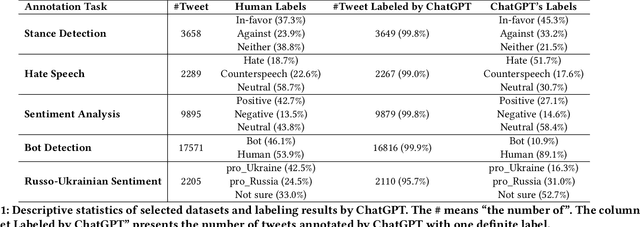
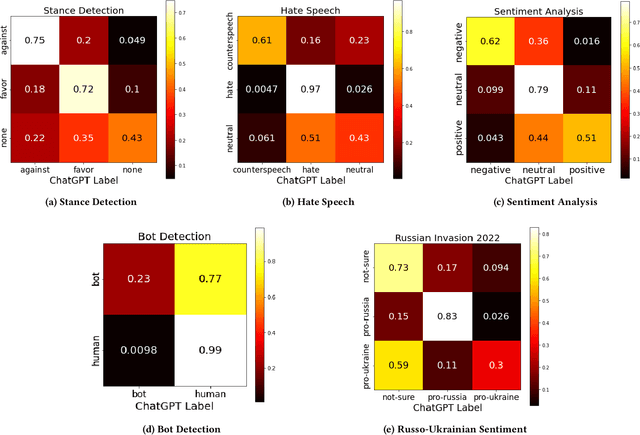

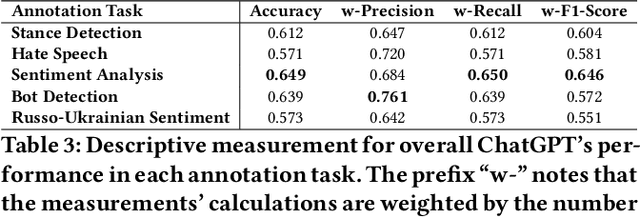
The release of ChatGPT has uncovered a range of possibilities whereby large language models (LLMs) can substitute human intelligence. In this paper, we seek to understand whether ChatGPT has the potential to reproduce human-generated label annotations in social computing tasks. Such an achievement could significantly reduce the cost and complexity of social computing research. As such, we use ChatGPT to relabel five seminal datasets covering stance detection (2x), sentiment analysis, hate speech, and bot detection. Our results highlight that ChatGPT does have the potential to handle these data annotation tasks, although a number of challenges remain. ChatGPT obtains an average accuracy 0.609. Performance is highest for the sentiment analysis dataset, with ChatGPT correctly annotating 64.9% of tweets. Yet, we show that performance varies substantially across individual labels. We believe this work can open up new lines of analysis and act as a basis for future research into the exploitation of ChatGPT for human annotation tasks.
Twitter Dataset for 2022 Russo-Ukrainian Crisis
Mar 06, 2022



Online Social Networks (OSNs) play a significant role in information sharing during a crisis. The data collected during such a crisis can reflect the large scale public opinions and sentiment. In addition, OSN data can also be used to study different campaigns that are employed by various entities to engineer public opinions. Such information sharing campaigns can range from spreading factual information to propaganda and misinformation. We provide a Twitter dataset of the 2022 Russo-Ukrainian conflict. In the first release, we share over 1.6 million tweets shared during the 1st week of the crisis.
Exposing Weaknesses of Malware Detectors with Explainability-Guided Evasion Attacks
Nov 19, 2021

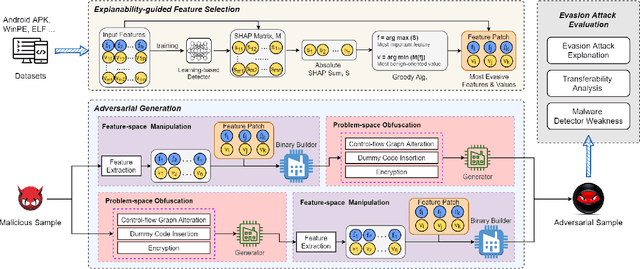

Numerous open-source and commercial malware detectors are available. However, the efficacy of these tools has been threatened by new adversarial attacks, whereby malware attempts to evade detection using, for example, machine learning techniques. In this work, we design an adversarial evasion attack that relies on both feature-space and problem-space manipulation. It uses explainability-guided feature selection to maximize evasion by identifying the most critical features that impact detection. We then use this attack as a benchmark to evaluate several state-of-the-art malware detectors. We find that (i) state-of-the-art malware detectors are vulnerable to even simple evasion strategies, and they can easily be tricked using off-the-shelf techniques; (ii) feature-space manipulation and problem-space obfuscation can be combined to enable evasion without needing white-box understanding of the detector; (iii) we can use explainability approaches (e.g., SHAP) to guide the feature manipulation and explain how attacks can transfer across multiple detectors. Our findings shed light on the weaknesses of current malware detectors, as well as how they can be improved.
Analyzing Temporal Relationships between Trending Terms on Twitter and Urban Dictionary Activity
May 18, 2020


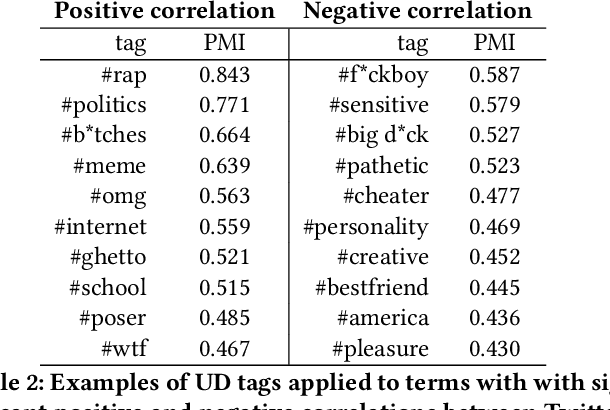
As an online, crowd-sourced, open English-language slang dictionary, the Urban Dictionary platform contains a wealth of opinions, jokes, and definitions of terms, phrases, acronyms, and more. However, it is unclear exactly how activity on this platform relates to larger conversations happening elsewhere on the web, such as discussions on larger, more popular social media platforms. In this research, we study the temporal activity trends on Urban Dictionary and provide the first analysis of how this activity relates to content being discussed on a major social network: Twitter. By collecting the whole of Urban Dictionary, as well as a large sample of tweets over seven years, we explore the connections between the words and phrases that are defined and searched for on Urban Dictionary and the content that is talked about on Twitter. Through a series of cross-correlation calculations, we identify cases in which Urban Dictionary activity closely reflects the larger conversation happening on Twitter. Then, we analyze the types of terms that have a stronger connection to discussions on Twitter, finding that Urban Dictionary activity that is positively correlated with Twitter is centered around terms related to memes, popular public figures, and offline events. Finally, We explore the relationship between periods of time when terms are trending on Twitter and the corresponding activity on Urban Dictionary, revealing that new definitions are more likely to be added to Urban Dictionary for terms that are currently trending on Twitter.
Characterising User Content on a Multi-lingual Social Network
Apr 23, 2020



Social media has been on the vanguard of political information diffusion in the 21st century. Most studies that look into disinformation, political influence and fake-news focus on mainstream social media platforms. This has inevitably made English an important factor in our current understanding of political activity on social media. As a result, there has only been a limited number of studies into a large portion of the world, including the largest, multilingual and multi-cultural democracy: India. In this paper we present our characterisation of a multilingual social network in India called ShareChat. We collect an exhaustive dataset across 72 weeks before and during the Indian general elections of 2019, across 14 languages. We investigate the cross lingual dynamics by clustering visually similar images together, and exploring how they move across language barriers. We find that Telugu, Malayalam, Tamil and Kannada languages tend to be dominant in soliciting political images (often referred to as memes), and posts from Hindi have the largest cross-lingual diffusion across ShareChat (as well as images containing text in English). In the case of images containing text that cross language barriers, we see that language translation is used to widen the accessibility. That said, we find cases where the same image is associated with very different text (and therefore meanings). This initial characterisation paves the way for more advanced pipelines to understand the dynamics of fake and political content in a multi-lingual and non-textual setting.