 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuan Wang
myAURA: Personalized health library for epilepsy management via knowledge graph sparsification and visualization
May 08, 2024
Objective: We report the development of the patient-centered myAURA application and suite of methods designed to aid epilepsy patients, caregivers, and researchers in making decisions about care and self-management. Materials and Methods: myAURA rests on the federation of an unprecedented collection of heterogeneous data resources relevant to epilepsy, such as biomedical databases, social media, and electronic health records. A generalizable, open-source methodology was developed to compute a multi-layer knowledge graph linking all this heterogeneous data via the terms of a human-centered biomedical dictionary. Results: The power of the approach is first exemplified in the study of the drug-drug interaction phenomenon. Furthermore, we employ a novel network sparsification methodology using the metric backbone of weighted graphs, which reveals the most important edges for inference, recommendation, and visualization, such as pharmacology factors patients discuss on social media. The network sparsification approach also allows us to extract focused digital cohorts from social media whose discourse is more relevant to epilepsy or other biomedical problems. Finally, we present our patient-centered design and pilot-testing of myAURA, including its user interface, based on focus groups and other stakeholder input. Discussion: The ability to search and explore myAURA's heterogeneous data sources via a sparsified multi-layer knowledge graph, as well as the combination of those layers in a single map, are useful features for integrating relevant information for epilepsy. Conclusion: Our stakeholder-driven, scalable approach to integrate traditional and non-traditional data sources, enables biomedical discovery and data-powered patient self-management in epilepsy, and is generalizable to other chronic conditions.
Distributed Invariant Kalman Filter for Cooperative Localization using Matrix Lie Groups
May 07, 2024This paper studies the problem of Cooperative Localization (CL) for multi-robot systems, where a group of mobile robots jointly localize themselves by using measurements from onboard sensors and shared information from other robots. We propose a novel distributed invariant Kalman Filter (DInEKF) based on the Lie group theory, to solve the CL problem in a 3-D environment. Unlike the standard EKF which computes the Jacobians based on the linearization at the state estimate, DInEKF defines the robots' motion model on matrix Lie groups and offers the advantage of state estimate-independent Jacobians. This significantly improves the consistency of the estimator. Moreover, the proposed algorithm is fully distributed, relying solely on each robot's ego-motion measurements and information received from its one-hop communication neighbors. The effectiveness of the proposed algorithm is validated in both Monte-Carlo simulations and real-world experiments. The results show that the proposed DInEKF outperforms the standard distributed EKF in terms of both accuracy and consistency.
EEG2TEXT: Open Vocabulary EEG-to-Text Decoding with EEG Pre-Training and Multi-View Transformer
May 03, 2024Deciphering the intricacies of the human brain has captivated curiosity for centuries. Recent strides in Brain-Computer Interface (BCI) technology, particularly using motor imagery, have restored motor functions such as reaching, grasping, and walking in paralyzed individuals. However, unraveling natural language from brain signals remains a formidable challenge. Electroencephalography (EEG) is a non-invasive technique used to record electrical activity in the brain by placing electrodes on the scalp. Previous studies of EEG-to-text decoding have achieved high accuracy on small closed vocabularies, but still fall short of high accuracy when dealing with large open vocabularies. We propose a novel method, EEG2TEXT, to improve the accuracy of open vocabulary EEG-to-text decoding. Specifically, EEG2TEXT leverages EEG pre-training to enhance the learning of semantics from EEG signals and proposes a multi-view transformer to model the EEG signal processing by different spatial regions of the brain. Experiments show that EEG2TEXT has superior performance, outperforming the state-of-the-art baseline methods by a large margin of up to 5% in absolute BLEU and ROUGE scores. EEG2TEXT shows great potential for a high-performance open-vocabulary brain-to-text system to facilitate communication.
Bi-CL: A Reinforcement Learning Framework for Robots Coordination Through Bi-level Optimization
Apr 23, 2024In multi-robot systems, achieving coordinated missions remains a significant challenge due to the coupled nature of coordination behaviors and the lack of global information for individual robots. To mitigate these challenges, this paper introduces a novel approach, Bi-level Coordination Learning (Bi-CL), that leverages a bi-level optimization structure within a centralized training and decentralized execution paradigm. Our bi-level reformulation decomposes the original problem into a reinforcement learning level with reduced action space, and an imitation learning level that gains demonstrations from a global optimizer. Both levels contribute to improved learning efficiency and scalability. We note that robots' incomplete information leads to mismatches between the two levels of learning models. To address this, Bi-CL further integrates an alignment penalty mechanism, aiming to minimize the discrepancy between the two levels without degrading their training efficiency. We introduce a running example to conceptualize the problem formulation and apply Bi-CL to two variations of this example: route-based and graph-based scenarios. Simulation results demonstrate that Bi-CL can learn more efficiently and achieve comparable performance with traditional multi-agent reinforcement learning baselines for multi-robot coordination.
Motion-adaptive Separable Collaborative Filters for Blind Motion Deblurring
Apr 19, 2024Eliminating image blur produced by various kinds of motion has been a challenging problem. Dominant approaches rely heavily on model capacity to remove blurring by reconstructing residual from blurry observation in feature space. These practices not only prevent the capture of spatially variable motion in the real world but also ignore the tailored handling of various motions in image space. In this paper, we propose a novel real-world deblurring filtering model called the Motion-adaptive Separable Collaborative (MISC) Filter. In particular, we use a motion estimation network to capture motion information from neighborhoods, thereby adaptively estimating spatially-variant motion flow, mask, kernels, weights, and offsets to obtain the MISC Filter. The MISC Filter first aligns the motion-induced blurring patterns to the motion middle along the predicted flow direction, and then collaboratively filters the aligned image through the predicted kernels, weights, and offsets to generate the output. This design can handle more generalized and complex motion in a spatially differentiated manner. Furthermore, we analyze the relationships between the motion estimation network and the residual reconstruction network. Extensive experiments on four widely used benchmarks demonstrate that our method provides an effective solution for real-world motion blur removal and achieves state-of-the-art performance. Code is available at https://github.com/ChengxuLiu/MISCFilter
Do We Really Need a Complex Agent System? Distill Embodied Agent into a Single Model
Apr 06, 2024With the power of large language models (LLMs), open-ended embodied agents can flexibly understand human instructions, generate interpretable guidance strategies, and output executable actions. Nowadays, Multi-modal Language Models~(MLMs) integrate multi-modal signals into LLMs, further bringing richer perception to entity agents and allowing embodied agents to perceive world-understanding tasks more delicately. However, existing works: 1) operate independently by agents, each containing multiple LLMs, from perception to action, resulting in gaps between complex tasks and execution; 2) train MLMs on static data, struggling with dynamics in open-ended scenarios; 3) input prior knowledge directly as prompts, suppressing application flexibility. We propose STEVE-2, a hierarchical knowledge distillation framework for open-ended embodied tasks, characterized by 1) a hierarchical system for multi-granular task division, 2) a mirrored distillation method for parallel simulation data, and 3) an extra expert model for bringing additional knowledge into parallel simulation. After distillation, embodied agents can complete complex, open-ended tasks without additional expert guidance, utilizing the performance and knowledge of a versatile MLM. Extensive evaluations on navigation and creation tasks highlight the superior performance of STEVE-2 in open-ended tasks, with $1.4 \times$ - $7.3 \times$ in performance.
Human-Robot Co-Transportation with Human Uncertainty-Aware MPC and Pose Optimization
Mar 31, 2024This paper proposes a new control algorithm for human-robot co-transportation based on a robot manipulator equipped with a mobile base and a robotic arm. The primary focus is to adapt to human uncertainties through the robot's whole-body dynamics and pose optimization. We introduce an augmented Model Predictive Control (MPC) formulation that explicitly models human uncertainties and contains extra variables than regular MPC to optimize the pose of the robotic arm. The core of our methodology involves a two-step iterative design: At each planning horizon, we select the best pose of the robotic arm (joint angle combination) from a candidate set, aiming to achieve the lowest estimated control cost. This selection is based on solving an uncertainty-aware Discrete Algebraic Ricatti Equation (DARE), which also informs the optimal control inputs for both the mobile base and the robotic arm. To validate the effectiveness of the proposed approach, we provide theoretical derivation for the uncertainty-aware DARE and perform simulated and proof-of-concept hardware experiments using a Fetch robot under varying conditions, including different nominal trajectories and noise levels. The results reveal that our proposed approach outperforms baseline algorithms, maintaining similar execution time with that do not consider human uncertainty or do not perform pose optimization.
AI for Biomedicine in the Era of Large Language Models
Mar 23, 2024The capabilities of AI for biomedicine span a wide spectrum, from the atomic level, where it solves partial differential equations for quantum systems, to the molecular level, predicting chemical or protein structures, and further extending to societal predictions like infectious disease outbreaks. Recent advancements in large language models, exemplified by models like ChatGPT, have showcased significant prowess in natural language tasks, such as translating languages, constructing chatbots, and answering questions. When we consider biomedical data, we observe a resemblance to natural language in terms of sequences: biomedical literature and health records presented as text, biological sequences or sequencing data arranged in sequences, or sensor data like brain signals as time series. The question arises: Can we harness the potential of recent large language models to drive biomedical knowledge discoveries? In this survey, we will explore the application of large language models to three crucial categories of biomedical data: 1) textual data, 2) biological sequences, and 3) brain signals. Furthermore, we will delve into large language model challenges in biomedical research, including ensuring trustworthiness, achieving personalization, and adapting to multi-modal data representation
Bridging 3D Gaussian and Mesh for Freeview Video Rendering
Mar 18, 2024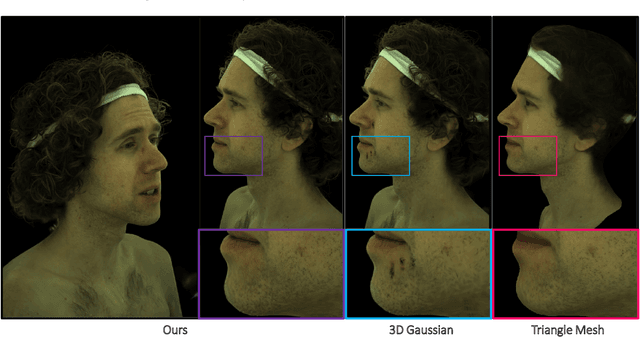
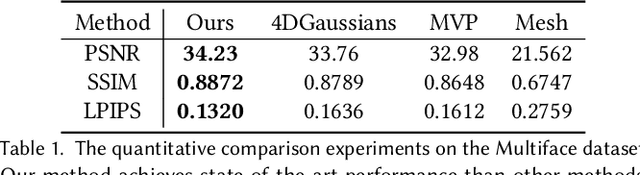


This is only a preview version of GauMesh. Recently, primitive-based rendering has been proven to achieve convincing results in solving the problem of modeling and rendering the 3D dynamic scene from 2D images. Despite this, in the context of novel view synthesis, each type of primitive has its inherent defects in terms of representation ability. It is difficult to exploit the mesh to depict the fuzzy geometry. Meanwhile, the point-based splatting (e.g. the 3D Gaussian Splatting) method usually produces artifacts or blurry pixels in the area with smooth geometry and sharp textures. As a result, it is difficult, even not impossible, to represent the complex and dynamic scene with a single type of primitive. To this end, we propose a novel approach, GauMesh, to bridge the 3D Gaussian and Mesh for modeling and rendering the dynamic scenes. Given a sequence of tracked mesh as initialization, our goal is to simultaneously optimize the mesh geometry, color texture, opacity maps, a set of 3D Gaussians, and the deformation field. At a specific time, we perform $\alpha$-blending on the RGB and opacity values based on the merged and re-ordered z-buffers from mesh and 3D Gaussian rasterizations. This produces the final rendering, which is supervised by the ground-truth image. Experiments demonstrate that our approach adapts the appropriate type of primitives to represent the different parts of the dynamic scene and outperforms all the baseline methods in both quantitative and qualitative comparisons without losing render speed.
Scaling Team Coordination on Graphs with Reinforcement Learning
Mar 09, 2024
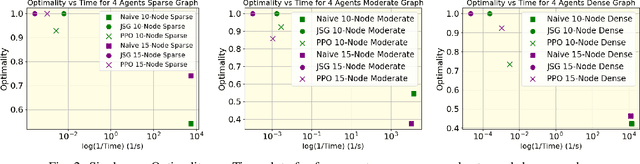
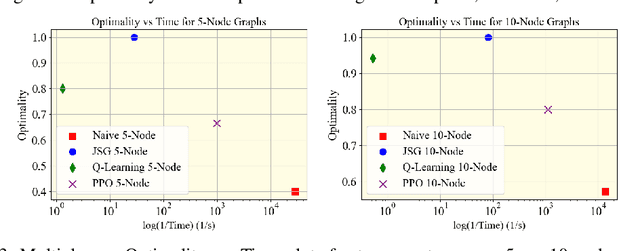
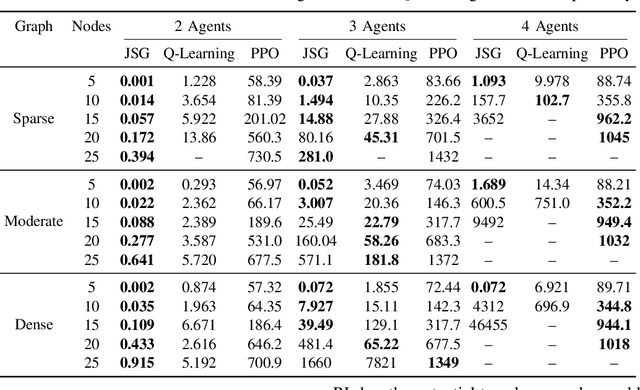
This paper studies Reinforcement Learning (RL) techniques to enable team coordination behaviors in graph environments with support actions among teammates to reduce the costs of traversing certain risky edges in a centralized manner. While classical approaches can solve this non-standard multi-agent path planning problem by converting the original Environment Graph (EG) into a Joint State Graph (JSG) to implicitly incorporate the support actions, those methods do not scale well to large graphs and teams. To address this curse of dimensionality, we propose to use RL to enable agents to learn such graph traversal and teammate supporting behaviors in a data-driven manner. Specifically, through a new formulation of the team coordination on graphs with risky edges problem into Markov Decision Processes (MDPs) with a novel state and action space, we investigate how RL can solve it in two paradigms: First, we use RL for a team of agents to learn how to coordinate and reach the goal with minimal cost on a single EG. We show that RL efficiently solves problems with up to 20/4 or 25/3 nodes/agents, using a fraction of the time needed for JSG to solve such complex problems; Second, we learn a general RL policy for any $N$-node EGs to produce efficient supporting behaviors. We present extensive experiments and compare our RL approaches against their classical counterparts.