 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYufan Liu
Distributed Invariant Kalman Filter for Cooperative Localization using Matrix Lie Groups
May 07, 2024
This paper studies the problem of Cooperative Localization (CL) for multi-robot systems, where a group of mobile robots jointly localize themselves by using measurements from onboard sensors and shared information from other robots. We propose a novel distributed invariant Kalman Filter (DInEKF) based on the Lie group theory, to solve the CL problem in a 3-D environment. Unlike the standard EKF which computes the Jacobians based on the linearization at the state estimate, DInEKF defines the robots' motion model on matrix Lie groups and offers the advantage of state estimate-independent Jacobians. This significantly improves the consistency of the estimator. Moreover, the proposed algorithm is fully distributed, relying solely on each robot's ego-motion measurements and information received from its one-hop communication neighbors. The effectiveness of the proposed algorithm is validated in both Monte-Carlo simulations and real-world experiments. The results show that the proposed DInEKF outperforms the standard distributed EKF in terms of both accuracy and consistency.
Learning to Route Among Specialized Experts for Zero-Shot Generalization
Feb 08, 2024Recently, there has been a widespread proliferation of "expert" language models that are specialized to a specific task or domain through parameter-efficient fine-tuning. How can we recycle large collections of expert language models to improve zero-shot generalization to unseen tasks? In this work, we propose Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE), which learns to route among specialized modules that were produced through parameter-efficient fine-tuning. Unlike past methods that learn to route among specialized models, PHATGOOSE explores the possibility that zero-shot generalization will be improved if different experts can be adaptively chosen for each token and at each layer in the model. Crucially, our method is post-hoc - it does not require simultaneous access to the datasets used to create the specialized models and only requires a modest amount of additional compute after each expert model is trained. In experiments covering a range of specialized model collections and zero-shot generalization benchmarks, we find that PHATGOOSE outperforms past methods for post-hoc routing and, in some cases, outperforms explicit multitask training (which requires simultaneous data access). To better understand the routing strategy learned by PHATGOOSE, we perform qualitative experiments to validate that PHATGOOSE's performance stems from its ability to make adaptive per-token and per-module expert choices. We release all of our code to support future work on improving zero-shot generalization by recycling specialized experts.
Cross-Architecture Knowledge Distillation
Jul 12, 2022



Transformer attracts much attention because of its ability to learn global relations and superior performance. In order to achieve higher performance, it is natural to distill complementary knowledge from Transformer to convolutional neural network (CNN). However, most existing knowledge distillation methods only consider homologous-architecture distillation, such as distilling knowledge from CNN to CNN. They may not be suitable when applying to cross-architecture scenarios, such as from Transformer to CNN. To deal with this problem, a novel cross-architecture knowledge distillation method is proposed. Specifically, instead of directly mimicking output/intermediate features of the teacher, a partially cross attention projector and a group-wise linear projector are introduced to align the student features with the teacher's in two projected feature spaces. And a multi-view robust training scheme is further presented to improve the robustness and stability of the framework. Extensive experiments show that the proposed method outperforms 14 state-of-the-arts on both small-scale and large-scale datasets.
Joint Learning of Visual-Audio Saliency Prediction and Sound Source Localization on Multi-face Videos
Nov 05, 2021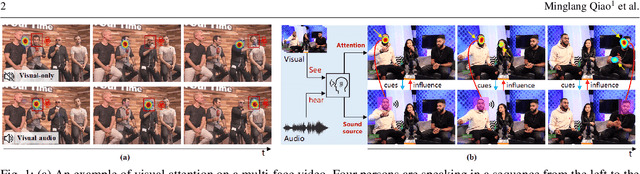
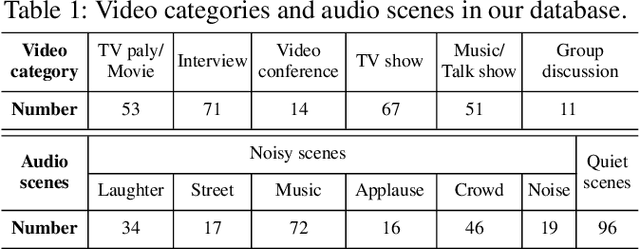

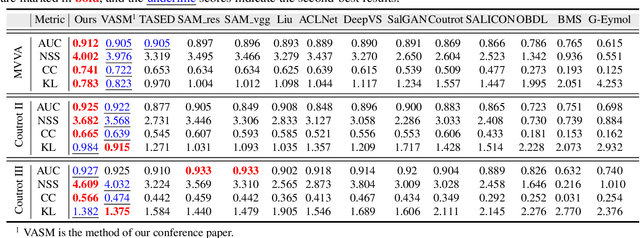
Visual and audio events simultaneously occur and both attract attention. However, most existing saliency prediction works ignore the influence of audio and only consider vision modality. In this paper, we propose a multitask learning method for visual-audio saliency prediction and sound source localization on multi-face video by leveraging visual, audio and face information. Specifically, we first introduce a large-scale database of multi-face video in visual-audio condition (MVVA), containing eye-tracking data and sound source annotations. Using this database, we find that sound influences human attention, and conversly attention offers a cue to determine sound source on multi-face video. Guided by these findings, a visual-audio multi-task network (VAM-Net) is introduced to predict saliency and locate sound source. VAM-Net consists of three branches corresponding to visual, audio and face modalities. Visual branch has a two-stream architecture to capture spatial and temporal information. Face and audio branches encode audio signals and faces, respectively. Finally, a spatio-temporal multi-modal graph (STMG) is constructed to model the interaction among multiple faces. With joint optimization of these branches, the intrinsic correlation of the tasks of saliency prediction and sound source localization is utilized and their performance is boosted by each other. Experiments show that the proposed method outperforms 12 state-of-the-art saliency prediction methods, and achieves competitive results in sound source localization.
SDTP: Semantic-aware Decoupled Transformer Pyramid for Dense Image Prediction
Sep 18, 2021



Although transformer has achieved great progress on computer vision tasks, the scale variation in dense image prediction is still the key challenge. Few effective multi-scale techniques are applied in transformer and there are two main limitations in the current methods. On one hand, self-attention module in vanilla transformer fails to sufficiently exploit the diversity of semantic information because of its rigid mechanism. On the other hand, it is hard to build attention and interaction among different levels due to the heavy computational burden. To alleviate this problem, we first revisit multi-scale problem in dense prediction, verifying the significance of diverse semantic representation and multi-scale interaction, and exploring the adaptation of transformer to pyramidal structure. Inspired by these findings, we propose a novel Semantic-aware Decoupled Transformer Pyramid (SDTP) for dense image prediction, consisting of Intra-level Semantic Promotion (ISP), Cross-level Decoupled Interaction (CDI) and Attention Refinement Function (ARF). ISP explores the semantic diversity in different receptive space. CDI builds the global attention and interaction among different levels in decoupled space which also solves the problem of heavy computation. Besides, ARF is further added to refine the attention in transformer. Experimental results demonstrate the validity and generality of the proposed method, which outperforms the state-of-the-art by a significant margin in dense image prediction tasks. Furthermore, the proposed components are all plug-and-play, which can be embedded in other methods.
Learning to Predict Salient Faces: A Novel Visual-Audio Saliency Model
Mar 29, 2021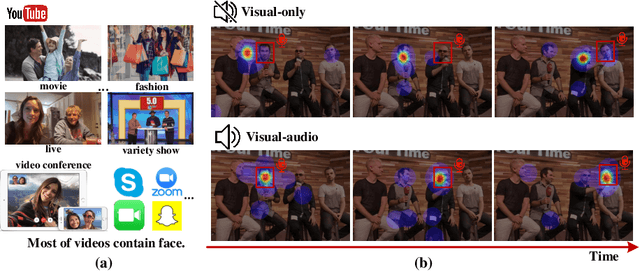
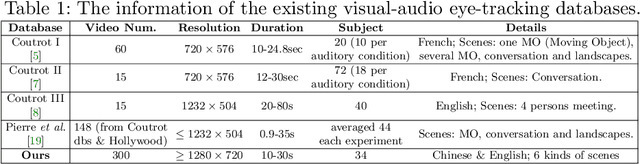
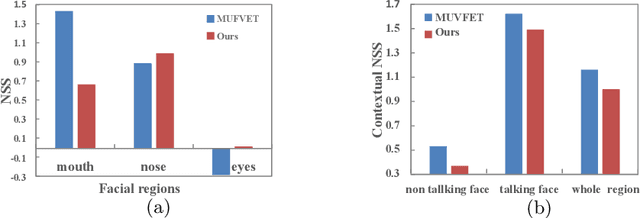
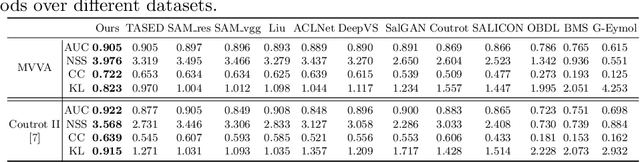
Recently, video streams have occupied a large proportion of Internet traffic, most of which contain human faces. Hence, it is necessary to predict saliency on multiple-face videos, which can provide attention cues for many content based applications. However, most of multiple-face saliency prediction works only consider visual information and ignore audio, which is not consistent with the naturalistic scenarios. Several behavioral studies have established that sound influences human attention, especially during the speech turn-taking in multiple-face videos. In this paper, we thoroughly investigate such influences by establishing a large-scale eye-tracking database of Multiple-face Video in Visual-Audio condition (MVVA). Inspired by the findings of our investigation, we propose a novel multi-modal video saliency model consisting of three branches: visual, audio and face. The visual branch takes the RGB frames as the input and encodes them into visual feature maps. The audio and face branches encode the audio signal and multiple cropped faces, respectively. A fusion module is introduced to integrate the information from three modalities, and to generate the final saliency map. Experimental results show that the proposed method outperforms 11 state-of-the-art saliency prediction works. It performs closer to human multi-modal attention.