 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTong Su
Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Apr 05, 2024
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
ProphNet: Efficient Agent-Centric Motion Forecasting with Anchor-Informed Proposals
Mar 21, 2023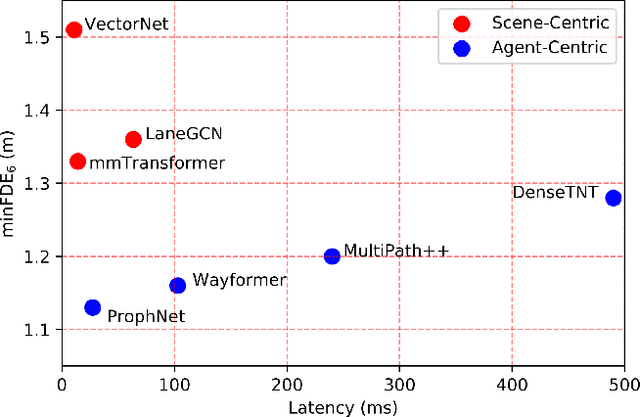
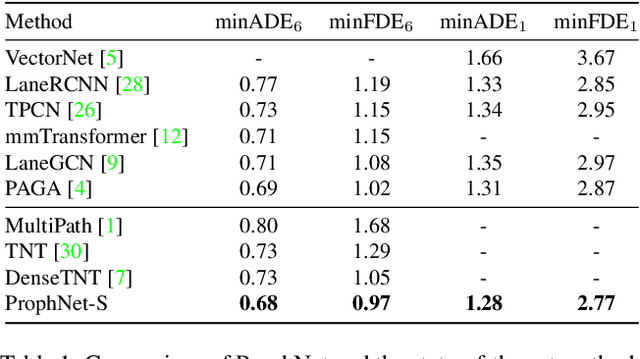
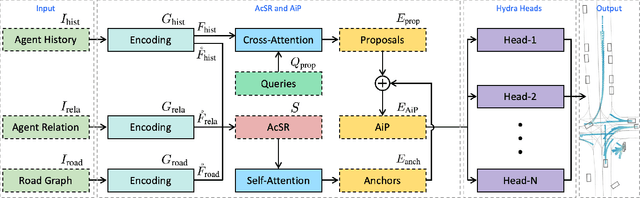
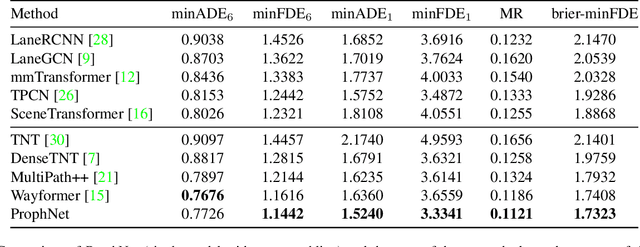
Motion forecasting is a key module in an autonomous driving system. Due to the heterogeneous nature of multi-sourced input, multimodality in agent behavior, and low latency required by onboard deployment, this task is notoriously challenging. To cope with these difficulties, this paper proposes a novel agent-centric model with anchor-informed proposals for efficient multimodal motion prediction. We design a modality-agnostic strategy to concisely encode the complex input in a unified manner. We generate diverse proposals, fused with anchors bearing goal-oriented scene context, to induce multimodal prediction that covers a wide range of future trajectories. Our network architecture is highly uniform and succinct, leading to an efficient model amenable for real-world driving deployment. Experiments reveal that our agent-centric network compares favorably with the state-of-the-art methods in prediction accuracy, while achieving scene-centric level inference latency.
QML for Argoverse 2 Motion Forecasting Challenge
Jul 13, 2022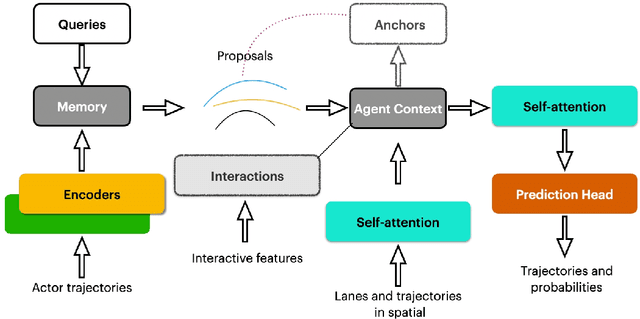

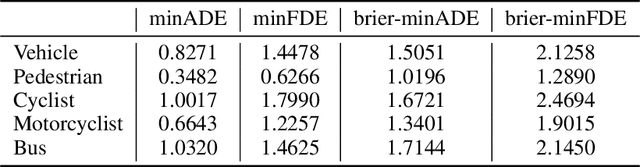

To safely navigate in various complex traffic scenarios, autonomous driving systems are generally equipped with a motion forecasting module to provide vital information for the downstream planning module. For the real-world onboard applications, both accuracy and latency of a motion forecasting model are essential. In this report, we present an effective and efficient solution, which ranks the 3rd place in the Argoverse 2 Motion Forecasting Challenge 2022.
Pedestrian Trajectory Prediction via Spatial Interaction Transformer Network
Dec 13, 2021



As a core technology of the autonomous driving system, pedestrian trajectory prediction can significantly enhance the function of active vehicle safety and reduce road traffic injuries. In traffic scenes, when encountering with oncoming people, pedestrians may make sudden turns or stop immediately, which often leads to complicated trajectories. To predict such unpredictable trajectories, we can gain insights into the interaction between pedestrians. In this paper, we present a novel generative method named Spatial Interaction Transformer (SIT), which learns the spatio-temporal correlation of pedestrian trajectories through attention mechanisms. Furthermore, we introduce the conditional variational autoencoder (CVAE) framework to model the future latent motion states of pedestrians. In particular, the experiments based on large-scale trafc dataset nuScenes [2] show that SIT has an outstanding performance than state-of-the-art (SOTA) methods. Experimental evaluation on the challenging ETH and UCY datasets conrms the robustness of our proposed model