 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYufeng Zhang
A Mean-Field Analysis of Neural Gradient Descent-Ascent: Applications to Functional Conditional Moment Equations
Apr 18, 2024
We study minimax optimization problems defined over infinite-dimensional function classes. In particular, we restrict the functions to the class of overparameterized two-layer neural networks and study (i) the convergence of the gradient descent-ascent algorithm and (ii) the representation learning of the neural network. As an initial step, we consider the minimax optimization problem stemming from estimating a functional equation defined by conditional expectations via adversarial estimation, where the objective function is quadratic in the functional space. For this problem, we establish convergence under the mean-field regime by considering the continuous-time and infinite-width limit of the optimization dynamics. Under this regime, gradient descent-ascent corresponds to a Wasserstein gradient flow over the space of probability measures defined over the space of neural network parameters. We prove that the Wasserstein gradient flow converges globally to a stationary point of the minimax objective at a $\mathcal{O}(T^{-1} + \alpha^{-1} ) $ sublinear rate, and additionally finds the solution to the functional equation when the regularizer of the minimax objective is strongly convex. Here $T$ denotes the time and $\alpha$ is a scaling parameter of the neural network. In terms of representation learning, our results show that the feature representation induced by the neural networks is allowed to deviate from the initial one by the magnitude of $\mathcal{O}(\alpha^{-1})$, measured in terms of the Wasserstein distance. Finally, we apply our general results to concrete examples including policy evaluation, nonparametric instrumental variable regression, and asset pricing.
Super-resolution of biomedical volumes with 2D supervision
Apr 15, 2024Volumetric biomedical microscopy has the potential to increase the diagnostic information extracted from clinical tissue specimens and improve the diagnostic accuracy of both human pathologists and computational pathology models. Unfortunately, barriers to integrating 3-dimensional (3D) volumetric microscopy into clinical medicine include long imaging times, poor depth / z-axis resolution, and an insufficient amount of high-quality volumetric data. Leveraging the abundance of high-resolution 2D microscopy data, we introduce masked slice diffusion for super-resolution (MSDSR), which exploits the inherent equivalence in the data-generating distribution across all spatial dimensions of biological specimens. This intrinsic characteristic allows for super-resolution models trained on high-resolution images from one plane (e.g., XY) to effectively generalize to others (XZ, YZ), overcoming the traditional dependency on orientation. We focus on the application of MSDSR to stimulated Raman histology (SRH), an optical imaging modality for biological specimen analysis and intraoperative diagnosis, characterized by its rapid acquisition of high-resolution 2D images but slow and costly optical z-sectioning. To evaluate MSDSR's efficacy, we introduce a new performance metric, SliceFID, and demonstrate MSDSR's superior performance over baseline models through extensive evaluations. Our findings reveal that MSDSR not only significantly enhances the quality and resolution of 3D volumetric data, but also addresses major obstacles hindering the broader application of 3D volumetric microscopy in clinical diagnostics and biomedical research.
$\mathbf{(N,K)}$-Puzzle: A Cost-Efficient Testbed for Benchmarking Reinforcement Learning Algorithms in Generative Language Model
Mar 11, 2024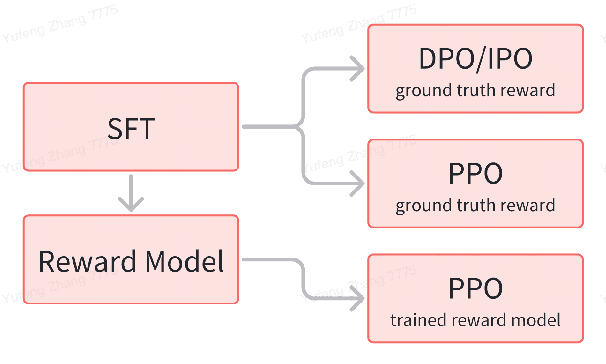
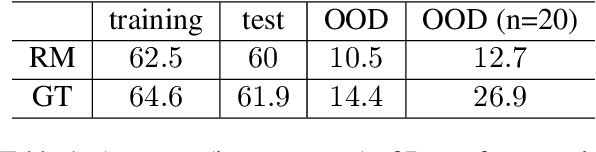
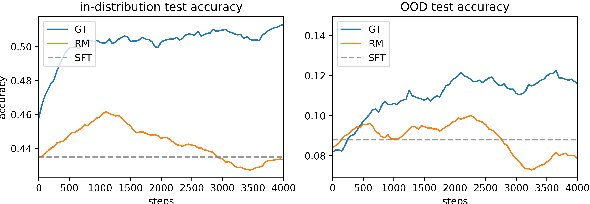
Recent advances in reinforcement learning (RL) algorithms aim to enhance the performance of language models at scale. Yet, there is a noticeable absence of a cost-effective and standardized testbed tailored to evaluating and comparing these algorithms. To bridge this gap, we present a generalized version of the 24-Puzzle: the $(N,K)$-Puzzle, which challenges language models to reach a target value $K$ with $N$ integers. We evaluate the effectiveness of established RL algorithms such as Proximal Policy Optimization (PPO), alongside novel approaches like Identity Policy Optimization (IPO) and Direct Policy Optimization (DPO).
Can Large Language Models Play Games? A Case Study of A Self-Play Approach
Mar 08, 2024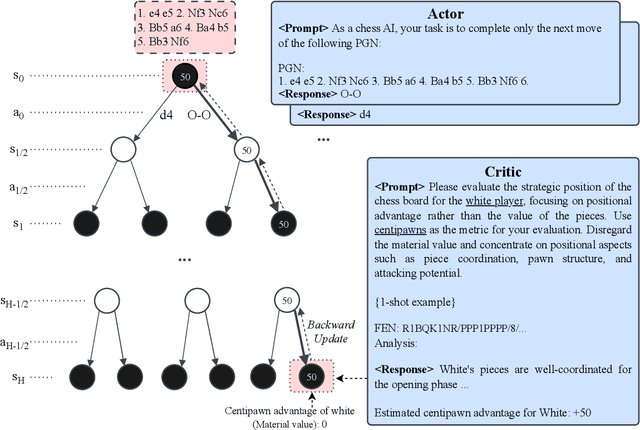



Large Language Models (LLMs) harness extensive data from the Internet, storing a broad spectrum of prior knowledge. While LLMs have proven beneficial as decision-making aids, their reliability is hampered by limitations in reasoning, hallucination phenomenon, and so on. On the other hand, Monte-Carlo Tree Search (MCTS) is a heuristic search algorithm that provides reliable decision-making solutions, achieved through recursive rollouts and self-play. However, the effectiveness of MCTS relies heavily on heuristic pruning and external value functions, particularly in complex decision scenarios. This work introduces an innovative approach that bolsters LLMs with MCTS self-play to efficiently resolve deterministic turn-based zero-sum games (DTZG), such as chess and go, without the need for additional training. Specifically, we utilize LLMs as both action pruners and proxies for value functions without the need for additional training. We theoretically prove that the suboptimality of the estimated value in our proposed method scales with $\tilde{\mathcal O}\Bigl(\frac{|\tilde {\mathcal A}|}{\sqrt{N}} + \epsilon_\mathrm{pruner} + \epsilon_\mathrm{critic}\Bigr)$, where \(N\) is the number of simulations, $|\tilde {\mathcal A}|$ is the cardinality of the pruned action space by LLM, and $\epsilon_\mathrm{pruner}$ and $\epsilon_\mathrm{critic}$ quantify the errors incurred by adopting LLMs as action space pruner and value function proxy, respectively. Our experiments in chess and go demonstrate the capability of our method to address challenges beyond the scope of MCTS and improve the performance of the directly application of LLMs.
CPT: Competence-progressive Training Strategy for Few-shot Node Classification
Feb 01, 2024Graph Neural Networks (GNNs) have made significant advancements in node classification, but their success relies on sufficient labeled nodes per class in the training data. Real-world graph data often exhibits a long-tail distribution with sparse labels, emphasizing the importance of GNNs' ability in few-shot node classification, which entails categorizing nodes with limited data. Traditional episodic meta-learning approaches have shown promise in this domain, but they face an inherent limitation: it might lead the model to converge to suboptimal solutions because of random and uniform task assignment, ignoring task difficulty levels. This could lead the meta-learner to face complex tasks too soon, hindering proper learning. Ideally, the meta-learner should start with simple concepts and advance to more complex ones, like human learning. So, we introduce CPT, a novel two-stage curriculum learning method that aligns task difficulty with the meta-learner's progressive competence, enhancing overall performance. Specifically, in CPT's initial stage, the focus is on simpler tasks, fostering foundational skills for engaging with complex tasks later. Importantly, the second stage dynamically adjusts task difficulty based on the meta-learner's growing competence, aiming for optimal knowledge acquisition. Extensive experiments on popular node classification datasets demonstrate significant improvements of our strategy over existing methods.
Answering Subjective Induction Questions on Products by Summarizing Multi-sources Multi-viewpoints Knowledge
Sep 12, 2023This paper proposes a new task in the field of Answering Subjective Induction Question on Products (SUBJPQA). The answer to this kind of question is non-unique, but can be interpreted from many perspectives. For example, the answer to 'whether the phone is heavy' has a variety of different viewpoints. A satisfied answer should be able to summarize these subjective opinions from multiple sources and provide objective knowledge, such as the weight of a phone. That is quite different from the traditional QA task, in which the answer to a factoid question is unique and can be found from a single data source. To address this new task, we propose a three-steps method. We first retrieve all answer-related clues from multiple knowledge sources on facts and opinions. The implicit commonsense facts are also collected to supplement the necessary but missing contexts. We then capture their relevance with the questions by interactive attention. Next, we design a reinforcement-based summarizer to aggregate all these knowledgeable clues. Based on a template-controlled decoder, we can output a comprehensive and multi-perspective answer. Due to the lack of a relevant evaluated benchmark set for the new task, we construct a large-scale dataset, named SupQA, consisting of 48,352 samples across 15 product domains. Evaluation results show the effectiveness of our approach.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023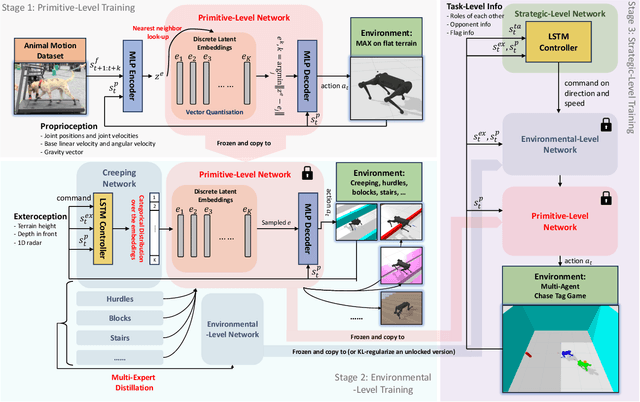
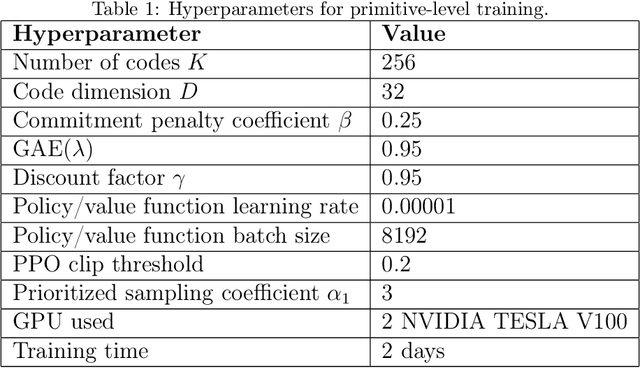
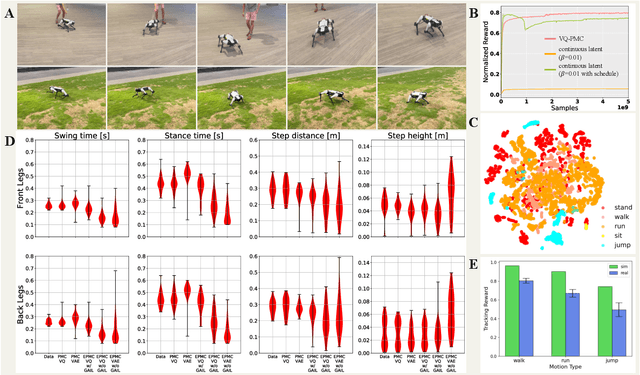
Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
Robust and Efficient Fault Diagnosis of mm-Wave Active Phased Arrays using Baseband Signal
Jun 07, 2023
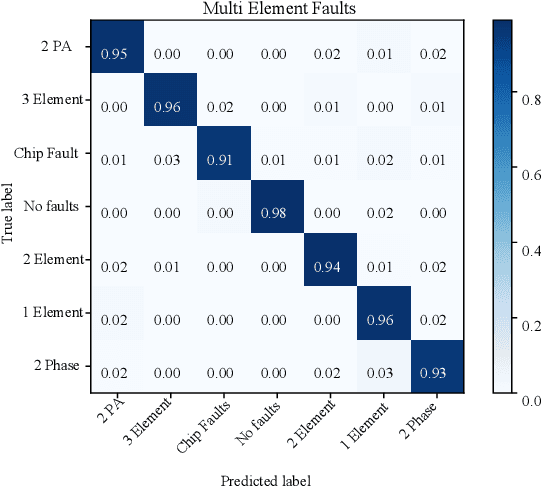
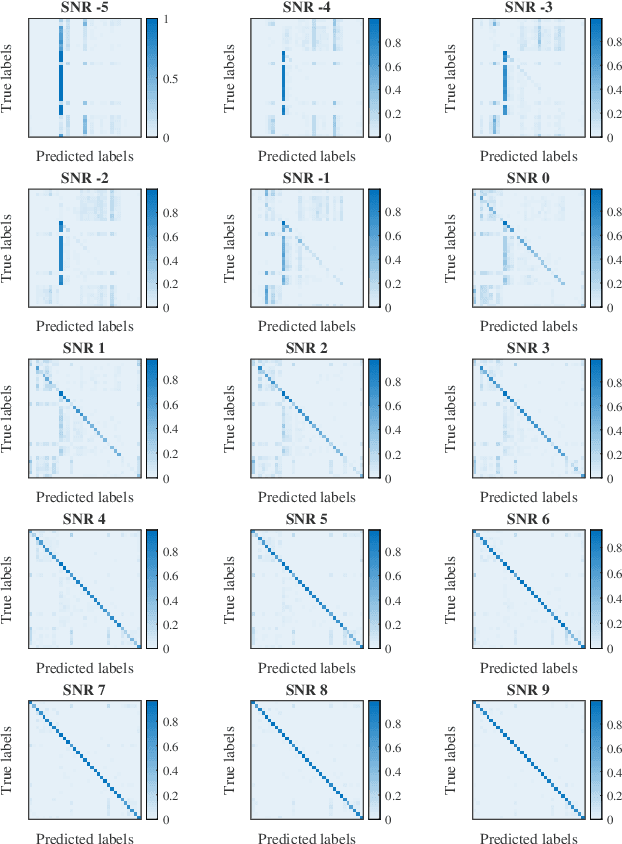
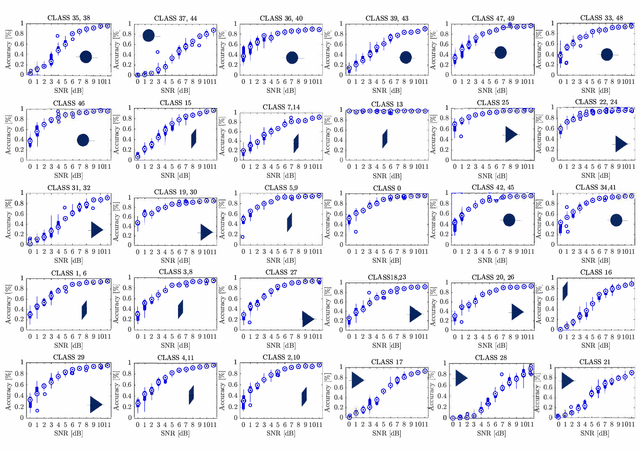
One key communication block in 5G and 6G radios is the active phased array (APA). To ensure reliable operation, efficient and timely fault diagnosis of APAs on-site is crucial. To date, fault diagnosis has relied on measurement of frequency domain radiation patterns using costly equipment and multiple strictly controlled measurement probes, which are time-consuming, complex, and therefore infeasible for on-site deployment. This paper proposes a novel method exploiting a Deep Neural Network (DNN) tailored to extract the features hidden in the baseband in-phase and quadrature signals for classifying the different faults. It requires only a single probe in one measurement point for fast and accurate diagnosis of the faulty elements and components in APAs. Validation of the proposed method is done using a commercial 28 GHz APA. Accuracies of 99% and 80% have been demonstrated for single- and multi-element failure detection, respectively. Three different test scenarios are investigated: on-off antenna elements, phase variations, and magnitude attenuation variations. In a low signal to noise ratio of 4 dB, stable fault detection accuracy above 90% is maintained. This is all achieved with a detection time of milliseconds (e.g 6~ms), showing a high potential for on-site deployment.
* 10 pages
What and How does In-Context Learning Learn? Bayesian Model Averaging, Parameterization, and Generalization
May 30, 2023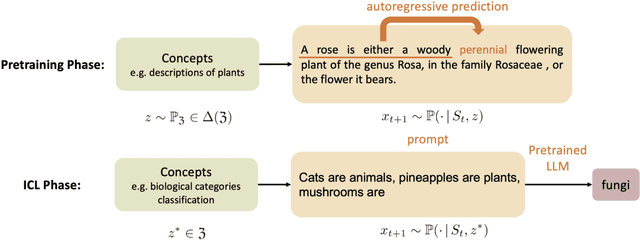
In this paper, we conduct a comprehensive study of In-Context Learning (ICL) by addressing several open questions: (a) What type of ICL estimator is learned within language models? (b) What are suitable performance metrics to evaluate ICL accurately and what are the error rates? (c) How does the transformer architecture enable ICL? To answer (a), we take a Bayesian view and demonstrate that ICL implicitly implements the Bayesian model averaging algorithm. This Bayesian model averaging algorithm is proven to be approximately parameterized by the attention mechanism. For (b), we analyze the ICL performance from an online learning perspective and establish a regret bound $\mathcal{O}(1/T)$, where $T$ is the ICL input sequence length. To address (c), in addition to the encoded Bayesian model averaging algorithm in attention, we show that during pertaining, the total variation distance between the learned model and the nominal model is bounded by a sum of an approximation error and a generalization error of $\tilde{\mathcal{O}}(1/\sqrt{N_{\mathrm{p}}T_{\mathrm{p}}})$, where $N_{\mathrm{p}}$ and $T_{\mathrm{p}}$ are the number of token sequences and the length of each sequence in pretraining, respectively. Our results provide a unified understanding of the transformer and its ICL ability with bounds on ICL regret, approximation, and generalization, which deepens our knowledge of these essential aspects of modern language models.
An Analysis of Attention via the Lens of Exchangeability and Latent Variable Models
Dec 30, 2022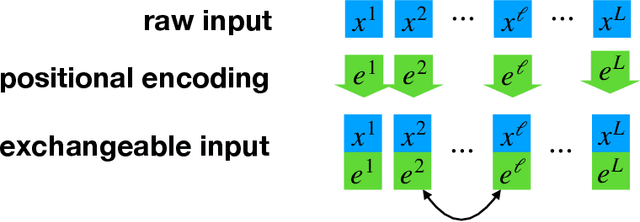
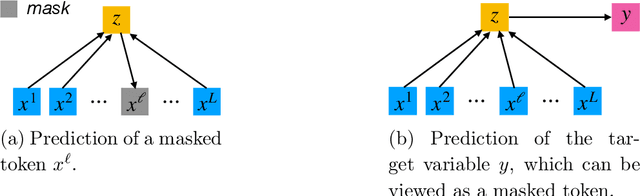
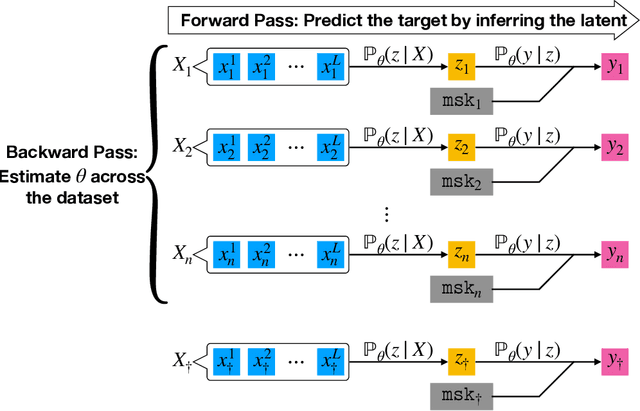
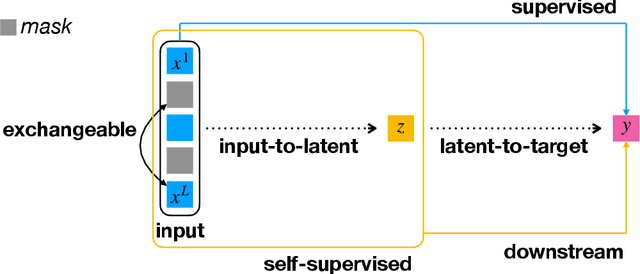
With the attention mechanism, transformers achieve significant empirical successes. Despite the intuitive understanding that transformers perform relational inference over long sequences to produce desirable representations, we lack a rigorous theory on how the attention mechanism achieves it. In particular, several intriguing questions remain open: (a) What makes a desirable representation? (b) How does the attention mechanism infer the desirable representation within the forward pass? (c) How does a pretraining procedure learn to infer the desirable representation through the backward pass? We observe that, as is the case in BERT and ViT, input tokens are often exchangeable since they already include positional encodings. The notion of exchangeability induces a latent variable model that is invariant to input sizes, which enables our theoretical analysis. - To answer (a) on representation, we establish the existence of a sufficient and minimal representation of input tokens. In particular, such a representation instantiates the posterior distribution of the latent variable given input tokens, which plays a central role in predicting output labels and solving downstream tasks. - To answer (b) on inference, we prove that attention with the desired parameter infers the latent posterior up to an approximation error, which is decreasing in input sizes. In detail, we quantify how attention approximates the conditional mean of the value given the key, which characterizes how it performs relational inference over long sequences. - To answer (c) on learning, we prove that both supervised and self-supervised objectives allow empirical risk minimization to learn the desired parameter up to a generalization error, which is independent of input sizes. Particularly, in the self-supervised setting, we identify a condition number that is pivotal to solving downstream tasks.