 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuchen Zhu
A Mean-Field Analysis of Neural Gradient Descent-Ascent: Applications to Functional Conditional Moment Equations
Apr 18, 2024
We study minimax optimization problems defined over infinite-dimensional function classes. In particular, we restrict the functions to the class of overparameterized two-layer neural networks and study (i) the convergence of the gradient descent-ascent algorithm and (ii) the representation learning of the neural network. As an initial step, we consider the minimax optimization problem stemming from estimating a functional equation defined by conditional expectations via adversarial estimation, where the objective function is quadratic in the functional space. For this problem, we establish convergence under the mean-field regime by considering the continuous-time and infinite-width limit of the optimization dynamics. Under this regime, gradient descent-ascent corresponds to a Wasserstein gradient flow over the space of probability measures defined over the space of neural network parameters. We prove that the Wasserstein gradient flow converges globally to a stationary point of the minimax objective at a $\mathcal{O}(T^{-1} + \alpha^{-1} ) $ sublinear rate, and additionally finds the solution to the functional equation when the regularizer of the minimax objective is strongly convex. Here $T$ denotes the time and $\alpha$ is a scaling parameter of the neural network. In terms of representation learning, our results show that the feature representation induced by the neural networks is allowed to deviate from the initial one by the magnitude of $\mathcal{O}(\alpha^{-1})$, measured in terms of the Wasserstein distance. Finally, we apply our general results to concrete examples including policy evaluation, nonparametric instrumental variable regression, and asset pricing.
Quantum State Generation with Structure-Preserving Diffusion Model
Apr 09, 2024This article considers the generative modeling of the states of quantum systems, and an approach based on denoising diffusion model is proposed. The key contribution is an algorithmic innovation that respects the physical nature of quantum states. More precisely, the commonly used density matrix representation of mixed-state has to be complex-valued Hermitian, positive semi-definite, and trace one. Generic diffusion models, or other generative methods, may not be able to generate data that strictly satisfy these structural constraints, even if all training data do. To develop a machine learning algorithm that has physics hard-wired in, we leverage the recent development of Mirror Diffusion Model and design a previously unconsidered mirror map, to enable strict structure-preserving generation. Both unconditional generation and conditional generation via classifier-free guidance are experimentally demonstrated efficacious, the latter even enabling the design of new quantum states when generated on unseen labels.
Meaningful Causal Aggregation and Paradoxical Confounding
Apr 23, 2023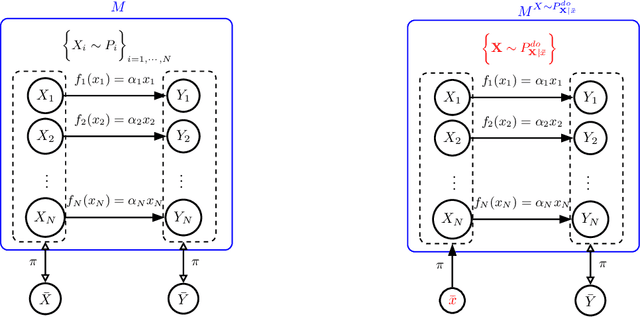
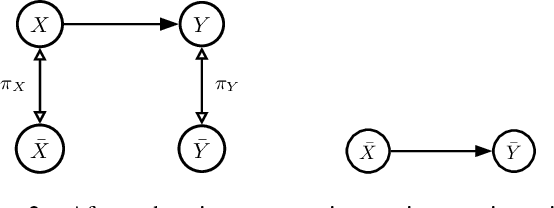


In aggregated variables the impact of interventions is typically ill-defined because different micro-realizations of the same macro-intervention can result in different changes of downstream macro-variables. We show that this ill-definedness of causality on aggregated variables can turn unconfounded causal relations into confounded ones and vice versa, depending on the respective micro-realization. We argue that it is practically infeasible to only use aggregated causal systems when we are free from this ill-definedness. Instead, we need to accept that macro causal relations are typically defined only with reference to the micro states. On the positive side, we show that cause-effect relations can be aggregated when the macro interventions are such that the distribution of micro states is the same as in the observational distribution and also discuss generalizations of this observation.
Deep Learning for Mean Field Optimal Transport
Feb 28, 2023



Mean field control (MFC) problems have been introduced to study social optima in very large populations of strategic agents. The main idea is to consider an infinite population and to simplify the analysis by using a mean field approximation. These problems can also be viewed as optimal control problems for McKean-Vlasov dynamics. They have found applications in a wide range of fields, from economics and finance to social sciences and engineering. Usually, the goal for the agents is to minimize a total cost which consists in the integral of a running cost plus a terminal cost. In this work, we consider MFC problems in which there is no terminal cost but, instead, the terminal distribution is prescribed. We call such problems mean field optimal transport problems since they can be viewed as a generalization of classical optimal transport problems when mean field interactions occur in the dynamics or the running cost function. We propose three numerical methods based on neural networks. The first one is based on directly learning an optimal control. The second one amounts to solve a forward-backward PDE system characterizing the solution. The third one relies on a primal-dual approach. We illustrate these methods with numerical experiments conducted on two families of examples.
Causal Inference with Treatment Measurement Error: A Nonparametric Instrumental Variable Approach
Jun 18, 2022



We propose a kernel-based nonparametric estimator for the causal effect when the cause is corrupted by error. We do so by generalizing estimation in the instrumental variable setting. Despite significant work on regression with measurement error, additionally handling unobserved confounding in the continuous setting is non-trivial: we have seen little prior work. As a by-product of our investigation, we clarify a connection between mean embeddings and characteristic functions, and how learning one simultaneously allows one to learn the other. This opens the way for kernel method research to leverage existing results in characteristic function estimation. Finally, we empirically show that our proposed method, MEKIV, improves over baselines and is robust under changes in the strength of measurement error and to the type of error distributions.
Graph Intervention Networks for Causal Effect Estimation
Jun 18, 2021
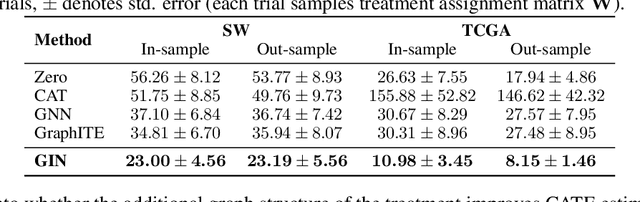

We address the estimation of conditional average treatment effects (CATEs) when treatments are graph-structured (e.g., molecular graphs of drugs). Given a weak condition on the effect, we propose a plug-in estimator that decomposes CATE estimation into separate, simpler optimization problems. Our estimator (a) isolates the causal estimands (reducing regularization bias), and (b) allows one to plug in arbitrary models for learning. In experiments with small-world and molecular graphs, we show that our approach outperforms prior approaches and is robust to varying selection biases. Our implementation is online.
Proximal Causal Learning with Kernels: Two-Stage Estimation and Moment Restriction
Jun 06, 2021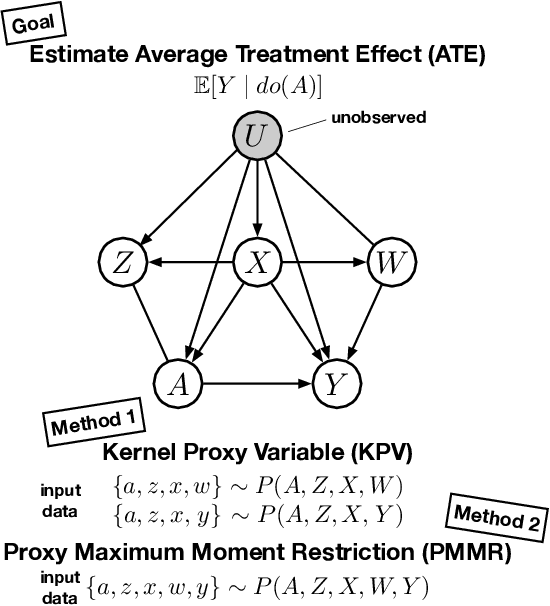
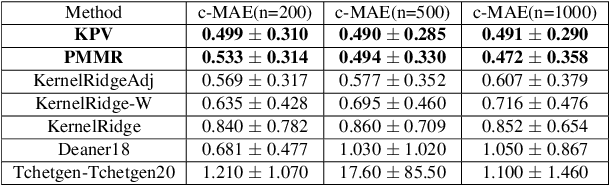
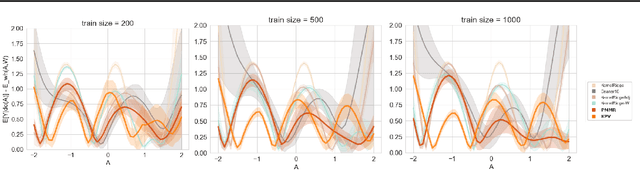

We address the problem of causal effect estimation in the presence of unobserved confounding, but where proxies for the latent confounder(s) are observed. We propose two kernel-based methods for nonlinear causal effect estimation in this setting: (a) a two-stage regression approach, and (b) a maximum moment restriction approach. We focus on the proximal causal learning setting, but our methods can be used to solve a wider class of inverse problems characterised by a Fredholm integral equation. In particular, we provide a unifying view of two-stage and moment restriction approaches for solving this problem in a nonlinear setting. We provide consistency guarantees for each algorithm, and we demonstrate these approaches achieve competitive results on synthetic data and data simulating a real-world task. In particular, our approach outperforms earlier methods that are not suited to leveraging proxy variables.
Model Rectification via Unknown Unknowns Extraction from Deployment Samples
Feb 08, 2021



Model deficiency that results from incomplete training data is a form of structural blindness that leads to costly errors, oftentimes with high confidence. During the training of classification tasks, underrepresented class-conditional distributions that a given hypothesis space can recognize results in a mismatch between the model and the target space. To mitigate the consequences of this discrepancy, we propose Random Test Sampling and Cross-Validation (RTSCV) as a general algorithmic framework that aims to perform a post-training model rectification at deployment time in a supervised way. RTSCV extracts unknown unknowns (u.u.s), i.e., examples from the class-conditional distributions that a classifier is oblivious to, and works in combination with a diverse family of modern prediction models. RTSCV augments the training set with a sample of the test set (or deployment data) and uses this redefined class layout to discover u.u.s via cross-validation, without relying on active learning or budgeted queries to an oracle. We contribute a theoretical analysis that establishes performance guarantees based on the design bases of modern classifiers. Our experimental evaluation demonstrates RTSCV's effectiveness, using 7 benchmark tabular and computer vision datasets, by reducing a performance gap as large as 41% from the respective pre-rectification models. Last we show that RTSCV consistently outperforms state-of-the-art approaches.
EQuANt (Enhanced Question Answer Network)
Jul 03, 2019



Machine Reading Comprehension (MRC) is an important topic in the domain of automated question answering and in natural language processing more generally. Since the release of the SQuAD 1.1 and SQuAD 2 datasets, progress in the field has been particularly significant, with current state-of-the-art models now exhibiting near-human performance at both answering well-posed questions and detecting questions which are unanswerable given a corresponding context. In this work, we present Enhanced Question Answer Network (EQuANt), an MRC model which extends the successful QANet architecture of Yu et al. to cope with unanswerable questions. By training and evaluating EQuANt on SQuAD 2, we show that it is indeed possible to extend QANet to the unanswerable domain. We achieve results which are close to 2 times better than our chosen baseline obtained by evaluating a lightweight version of the original QANet architecture on SQuAD 2. In addition, we report that the performance of EQuANt on SQuAD 1.1 after being trained on SQuAD2 exceeds that of our lightweight QANet architecture trained and evaluated on SQuAD 1.1, demonstrating the utility of multi-task learning in the MRC context.