 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXie Chen
AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding
May 06, 2024
The paper introduces AniTalker, an innovative framework designed to generate lifelike talking faces from a single portrait. Unlike existing models that primarily focus on verbal cues such as lip synchronization and fail to capture the complex dynamics of facial expressions and nonverbal cues, AniTalker employs a universal motion representation. This innovative representation effectively captures a wide range of facial dynamics, including subtle expressions and head movements. AniTalker enhances motion depiction through two self-supervised learning strategies: the first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations, and the second develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This approach ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the need for labeled data. Additionally, the integration of a diffusion model with a variance adapter allows for the generation of diverse and controllable facial animations. This method not only demonstrates AniTalker's capability to create detailed and realistic facial movements but also underscores its potential in crafting dynamic avatars for real-world applications. Synthetic results can be viewed at https://github.com/X-LANCE/AniTalker.
Attention-Constrained Inference for Robust Decoder-Only Text-to-Speech
Apr 30, 2024Recent popular decoder-only text-to-speech models are known for their ability of generating natural-sounding speech. However, such models sometimes suffer from word skipping and repeating due to the lack of explicit monotonic alignment constraints. In this paper, we notice from the attention maps that some particular attention heads of the decoder-only model indicate the alignments between speech and text. We call the attention maps of those heads Alignment-Emerged Attention Maps (AEAMs). Based on this discovery, we propose a novel inference method without altering the training process, named Attention-Constrained Inference (ACI), to facilitate monotonic synthesis. It first identifies AEAMs using the Attention Sweeping algorithm and then applies constraining masks on AEAMs. Our experimental results on decoder-only TTS model VALL-E show that the WER of synthesized speech is reduced by up to 20.5% relatively with ACI while the naturalness and speaker similarity are comparable.
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
Apr 29, 2024We present GStalker, a 3D audio-driven talking face generation model with Gaussian Splatting for both fast training (40 minutes) and real-time rendering (125 FPS) with a 3$\sim$5 minute video for training material, in comparison with previous 2D and 3D NeRF-based modeling frameworks which require hours of training and seconds of rendering per frame. Specifically, GSTalker learns an audio-driven Gaussian deformation field to translate and transform 3D Gaussians to synchronize with audio information, in which multi-resolution hashing grid-based tri-plane and temporal smooth module are incorporated to learn accurate deformation for fine-grained facial details. In addition, a pose-conditioned deformation field is designed to model the stabilized torso. To enable efficient optimization of the condition Gaussian deformation field, we initialize 3D Gaussians by learning a coarse static Gaussian representation. Extensive experiments in person-specific videos with audio tracks validate that GSTalker can generate high-fidelity and audio-lips synchronized results with fast training and real-time rendering speed.
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
StoryTTS: A Highly Expressive Text-to-Speech Dataset with Rich Textual Expressiveness Annotations
Apr 23, 2024While acoustic expressiveness has long been studied in expressive text-to-speech (ETTS), the inherent expressiveness in text lacks sufficient attention, especially for ETTS of artistic works. In this paper, we introduce StoryTTS, a highly ETTS dataset that contains rich expressiveness both in acoustic and textual perspective, from the recording of a Mandarin storytelling show. A systematic and comprehensive labeling framework is proposed for textual expressiveness. We analyze and define speech-related textual expressiveness in StoryTTS to include five distinct dimensions through linguistics, rhetoric, etc. Then we employ large language models and prompt them with a few manual annotation examples for batch annotation. The resulting corpus contains 61 hours of consecutive and highly prosodic speech equipped with accurate text transcriptions and rich textual expressiveness annotations. Therefore, StoryTTS can aid future ETTS research to fully mine the abundant intrinsic textual and acoustic features. Experiments are conducted to validate that TTS models can generate speech with improved expressiveness when integrating with the annotated textual labels in StoryTTS.
* Accepted by ICASSP 2024
The X-LANCE Technical Report for Interspeech 2024 Speech Processing Using Discrete Speech Unit Challenge
Apr 10, 2024Discrete speech tokens have been more and more popular in multiple speech processing fields, including automatic speech recognition (ASR), text-to-speech (TTS) and singing voice synthesis (SVS). In this paper, we describe the systems developed by the SJTU X-LANCE group for the TTS (acoustic + vocoder), SVS, and ASR tracks in the Interspeech 2024 Speech Processing Using Discrete Speech Unit Challenge. Notably, we achieved 1st rank on the leaderboard in the TTS track both with the whole training set and only 1h training data, with the highest UTMOS score and lowest bitrate among all submissions.
Quantum State Generation with Structure-Preserving Diffusion Model
Apr 09, 2024This article considers the generative modeling of the states of quantum systems, and an approach based on denoising diffusion model is proposed. The key contribution is an algorithmic innovation that respects the physical nature of quantum states. More precisely, the commonly used density matrix representation of mixed-state has to be complex-valued Hermitian, positive semi-definite, and trace one. Generic diffusion models, or other generative methods, may not be able to generate data that strictly satisfy these structural constraints, even if all training data do. To develop a machine learning algorithm that has physics hard-wired in, we leverage the recent development of Mirror Diffusion Model and design a previously unconsidered mirror map, to enable strict structure-preserving generation. Both unconditional generation and conditional generation via classifier-free guidance are experimentally demonstrated efficacious, the latter even enabling the design of new quantum states when generated on unseen labels.
Advanced Long-Content Speech Recognition With Factorized Neural Transducer
Mar 20, 2024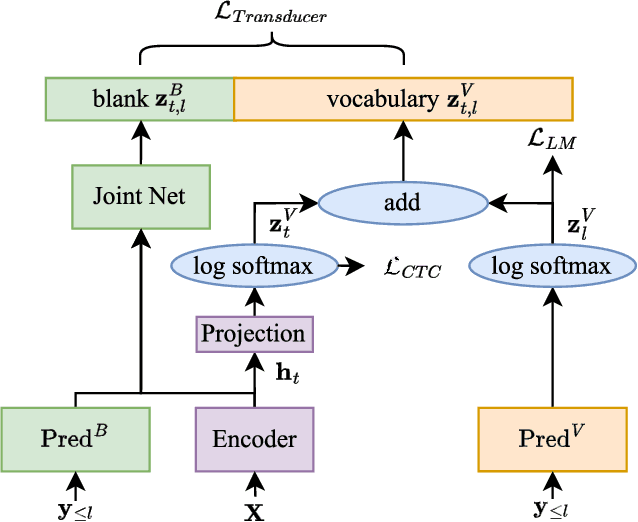
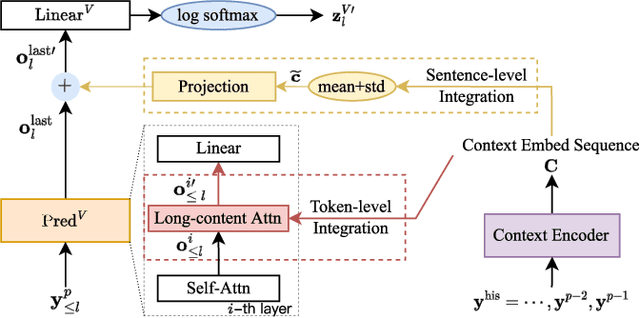
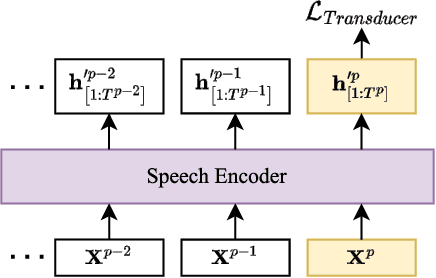
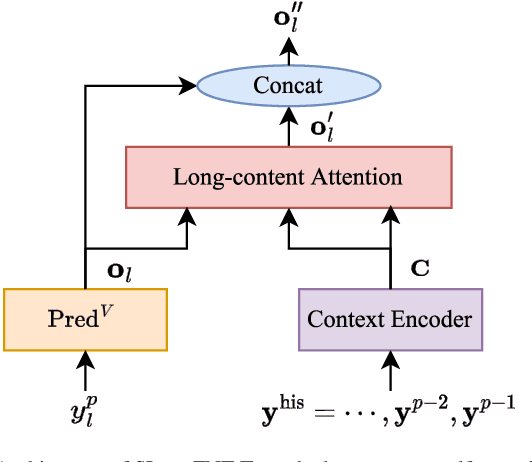
In this paper, we propose two novel approaches, which integrate long-content information into the factorized neural transducer (FNT) based architecture in both non-streaming (referred to as LongFNT ) and streaming (referred to as SLongFNT ) scenarios. We first investigate whether long-content transcriptions can improve the vanilla conformer transducer (C-T) models. Our experiments indicate that the vanilla C-T models do not exhibit improved performance when utilizing long-content transcriptions, possibly due to the predictor network of C-T models not functioning as a pure language model. Instead, FNT shows its potential in utilizing long-content information, where we propose the LongFNT model and explore the impact of long-content information in both text (LongFNT-Text) and speech (LongFNT-Speech). The proposed LongFNT-Text and LongFNT-Speech models further complement each other to achieve better performance, with transcription history proving more valuable to the model. The effectiveness of our LongFNT approach is evaluated on LibriSpeech and GigaSpeech corpora, and obtains relative 19% and 12% word error rate reduction, respectively. Furthermore, we extend the LongFNT model to the streaming scenario, which is named SLongFNT , consisting of SLongFNT-Text and SLongFNT-Speech approaches to utilize long-content text and speech information. Experiments show that the proposed SLongFNT model achieves relative 26% and 17% WER reduction on LibriSpeech and GigaSpeech respectively while keeping a good latency, compared to the FNT baseline. Overall, our proposed LongFNT and SLongFNT highlight the significance of considering long-content speech and transcription knowledge for improving both non-streaming and streaming speech recognition systems.
* Accepted by TASLP 2024
An Embarrassingly Simple Approach for LLM with Strong ASR Capacity
Feb 13, 2024In this paper, we focus on solving one of the most important tasks in the field of speech processing, i.e., automatic speech recognition (ASR), with speech foundation encoders and large language models (LLM). Recent works have complex designs such as compressing the output temporally for the speech encoder, tackling modal alignment for the projector, and utilizing parameter-efficient fine-tuning for the LLM. We found that delicate designs are not necessary, while an embarrassingly simple composition of off-the-shelf speech encoder, LLM, and the only trainable linear projector is competent for the ASR task. To be more specific, we benchmark and explore various combinations of LLMs and speech encoders, leading to the optimal LLM-based ASR system, which we call SLAM-ASR. The proposed SLAM-ASR provides a clean setup and little task-specific design, where only the linear projector is trained. To the best of our knowledge, SLAM-ASR achieves the best performance on the Librispeech benchmark among LLM-based ASR models and even outperforms the latest LLM-based audio-universal model trained on massive pair data. Finally, we explore the capability emergence of LLM-based ASR in the process of modal alignment. We hope that our study can facilitate the research on extending LLM with cross-modality capacity and shed light on the LLM-based ASR community.
BAT: Learning to Reason about Spatial Sounds with Large Language Models
Feb 02, 2024Spatial sound reasoning is a fundamental human skill, enabling us to navigate and interpret our surroundings based on sound. In this paper we present BAT, which combines the spatial sound perception ability of a binaural acoustic scene analysis model with the natural language reasoning capabilities of a large language model (LLM) to replicate this innate ability. To address the lack of existing datasets of in-the-wild spatial sounds, we synthesized a binaural audio dataset using AudioSet and SoundSpaces 2.0. Next, we developed SpatialSoundQA, a spatial sound-based question-answering dataset, offering a range of QA tasks that train BAT in various aspects of spatial sound perception and reasoning. The acoustic front end encoder of BAT is a novel spatial audio encoder named Spatial Audio Spectrogram Transformer, or Spatial-AST, which by itself achieves strong performance across sound event detection, spatial localization, and distance estimation. By integrating Spatial-AST with LLaMA-2 7B model, BAT transcends standard Sound Event Localization and Detection (SELD) tasks, enabling the model to reason about the relationships between the sounds in its environment. Our experiments demonstrate BAT's superior performance on both spatial sound perception and reasoning, showcasing the immense potential of LLMs in navigating and interpreting complex spatial audio environments.