 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenpeng Du
AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding
May 06, 2024
The paper introduces AniTalker, an innovative framework designed to generate lifelike talking faces from a single portrait. Unlike existing models that primarily focus on verbal cues such as lip synchronization and fail to capture the complex dynamics of facial expressions and nonverbal cues, AniTalker employs a universal motion representation. This innovative representation effectively captures a wide range of facial dynamics, including subtle expressions and head movements. AniTalker enhances motion depiction through two self-supervised learning strategies: the first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations, and the second develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This approach ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the need for labeled data. Additionally, the integration of a diffusion model with a variance adapter allows for the generation of diverse and controllable facial animations. This method not only demonstrates AniTalker's capability to create detailed and realistic facial movements but also underscores its potential in crafting dynamic avatars for real-world applications. Synthetic results can be viewed at https://github.com/X-LANCE/AniTalker.
Attention-Constrained Inference for Robust Decoder-Only Text-to-Speech
Apr 30, 2024Recent popular decoder-only text-to-speech models are known for their ability of generating natural-sounding speech. However, such models sometimes suffer from word skipping and repeating due to the lack of explicit monotonic alignment constraints. In this paper, we notice from the attention maps that some particular attention heads of the decoder-only model indicate the alignments between speech and text. We call the attention maps of those heads Alignment-Emerged Attention Maps (AEAMs). Based on this discovery, we propose a novel inference method without altering the training process, named Attention-Constrained Inference (ACI), to facilitate monotonic synthesis. It first identifies AEAMs using the Attention Sweeping algorithm and then applies constraining masks on AEAMs. Our experimental results on decoder-only TTS model VALL-E show that the WER of synthesized speech is reduced by up to 20.5% relatively with ACI while the naturalness and speaker similarity are comparable.
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
Apr 29, 2024We present GStalker, a 3D audio-driven talking face generation model with Gaussian Splatting for both fast training (40 minutes) and real-time rendering (125 FPS) with a 3$\sim$5 minute video for training material, in comparison with previous 2D and 3D NeRF-based modeling frameworks which require hours of training and seconds of rendering per frame. Specifically, GSTalker learns an audio-driven Gaussian deformation field to translate and transform 3D Gaussians to synchronize with audio information, in which multi-resolution hashing grid-based tri-plane and temporal smooth module are incorporated to learn accurate deformation for fine-grained facial details. In addition, a pose-conditioned deformation field is designed to model the stabilized torso. To enable efficient optimization of the condition Gaussian deformation field, we initialize 3D Gaussians by learning a coarse static Gaussian representation. Extensive experiments in person-specific videos with audio tracks validate that GSTalker can generate high-fidelity and audio-lips synchronized results with fast training and real-time rendering speed.
The X-LANCE Technical Report for Interspeech 2024 Speech Processing Using Discrete Speech Unit Challenge
Apr 10, 2024Discrete speech tokens have been more and more popular in multiple speech processing fields, including automatic speech recognition (ASR), text-to-speech (TTS) and singing voice synthesis (SVS). In this paper, we describe the systems developed by the SJTU X-LANCE group for the TTS (acoustic + vocoder), SVS, and ASR tracks in the Interspeech 2024 Speech Processing Using Discrete Speech Unit Challenge. Notably, we achieved 1st rank on the leaderboard in the TTS track both with the whole training set and only 1h training data, with the highest UTMOS score and lowest bitrate among all submissions.
VALL-T: Decoder-Only Generative Transducer for Robust and Decoding-Controllable Text-to-Speech
Jan 30, 2024Recent TTS models with decoder-only Transformer architecture, such as SPEAR-TTS and VALL-E, achieve impressive naturalness and demonstrate the ability for zero-shot adaptation given a speech prompt. However, such decoder-only TTS models lack monotonic alignment constraints, sometimes leading to hallucination issues such as mispronunciation, word skipping and repeating. To address this limitation, we propose VALL-T, a generative Transducer model that introduces shifting relative position embeddings for input phoneme sequence, explicitly indicating the monotonic generation process while maintaining the architecture of decoder-only Transformer. Consequently, VALL-T retains the capability of prompt-based zero-shot adaptation and demonstrates better robustness against hallucinations with a relative reduction of 28.3% in the word error rate. Furthermore, the controllability of alignment in VALL-T during decoding facilitates the use of untranscribed speech prompts, even in unknown languages. It also enables the synthesis of lengthy speech by utilizing an aligned context window.
DiffDub: Person-generic Visual Dubbing Using Inpainting Renderer with Diffusion Auto-encoder
Nov 03, 2023Generating high-quality and person-generic visual dubbing remains a challenge. Recent innovation has seen the advent of a two-stage paradigm, decoupling the rendering and lip synchronization process facilitated by intermediate representation as a conduit. Still, previous methodologies rely on rough landmarks or are confined to a single speaker, thus limiting their performance. In this paper, we propose DiffDub: Diffusion-based dubbing. We first craft the Diffusion auto-encoder by an inpainting renderer incorporating a mask to delineate editable zones and unaltered regions. This allows for seamless filling of the lower-face region while preserving the remaining parts. Throughout our experiments, we encountered several challenges. Primarily, the semantic encoder lacks robustness, constricting its ability to capture high-level features. Besides, the modeling ignored facial positioning, causing mouth or nose jitters across frames. To tackle these issues, we employ versatile strategies, including data augmentation and supplementary eye guidance. Moreover, we encapsulated a conformer-based reference encoder and motion generator fortified by a cross-attention mechanism. This enables our model to learn person-specific textures with varying references and reduces reliance on paired audio-visual data. Our rigorous experiments comprehensively highlight that our ground-breaking approach outpaces existing methods with considerable margins and delivers seamless, intelligible videos in person-generic and multilingual scenarios.
Acoustic BPE for Speech Generation with Discrete Tokens
Oct 23, 2023Discrete audio tokens derived from self-supervised learning models have gained widespread usage in speech generation. However, current practice of directly utilizing audio tokens poses challenges for sequence modeling due to the length of the token sequence. Additionally, this approach places the burden on the model to establish correlations between tokens, further complicating the modeling process. To address this issue, we propose acoustic BPE which encodes frequent audio token patterns by utilizing byte-pair encoding. Acoustic BPE effectively reduces the sequence length and leverages the prior morphological information present in token sequence, which alleviates the modeling challenges of token correlation. Through comprehensive investigations on a speech language model trained with acoustic BPE, we confirm the notable advantages it offers, including faster inference and improved syntax capturing capabilities. In addition, we propose a novel rescore method to select the optimal synthetic speech among multiple candidates generated by rich-diversity TTS system. Experiments prove that rescore selection aligns closely with human preference, which highlights acoustic BPE's potential to other speech generation tasks.
Towards Universal Speech Discrete Tokens: A Case Study for ASR and TTS
Sep 14, 2023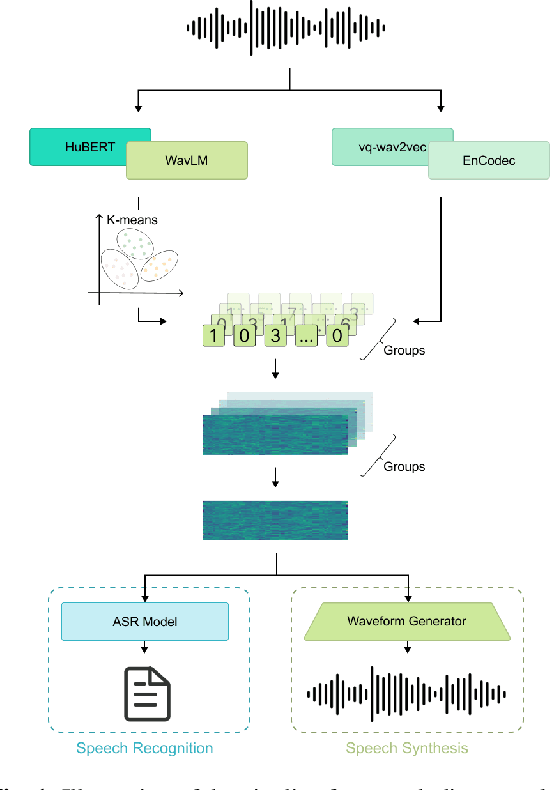
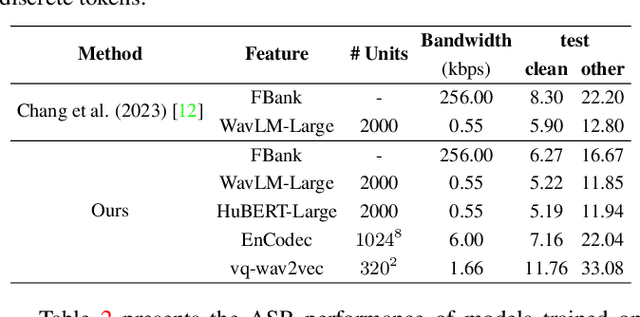

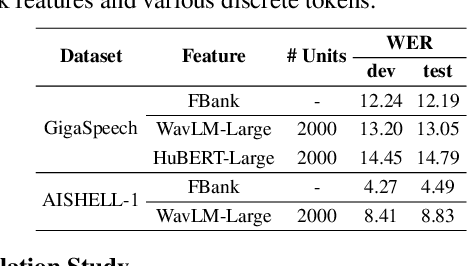
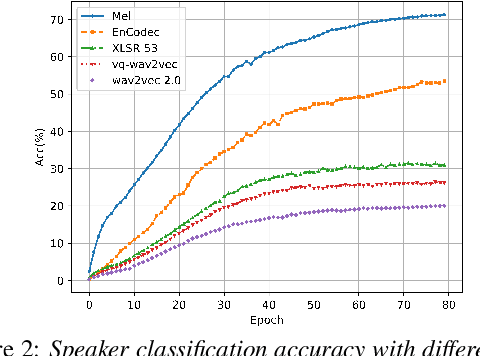
Self-supervised learning (SSL) proficiency in speech-related tasks has driven research into utilizing discrete tokens for speech tasks like recognition and translation, which offer lower storage requirements and great potential to employ natural language processing techniques. However, these studies, mainly single-task focused, faced challenges like overfitting and performance degradation in speech recognition tasks, often at the cost of sacrificing performance in multi-task scenarios. This study presents a comprehensive comparison and optimization of discrete tokens generated by various leading SSL models in speech recognition and synthesis tasks. We aim to explore the universality of speech discrete tokens across multiple speech tasks. Experimental results demonstrate that discrete tokens achieve comparable results against systems trained on FBank features in speech recognition tasks and outperform mel-spectrogram features in speech synthesis in subjective and objective metrics. These findings suggest that universal discrete tokens have enormous potential in various speech-related tasks. Our work is open-source and publicly available to facilitate research in this direction.
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
Sep 10, 2023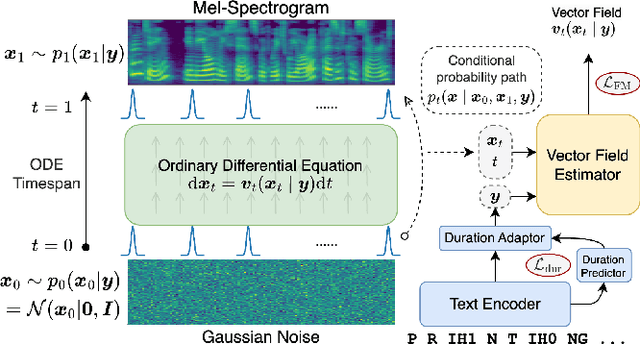
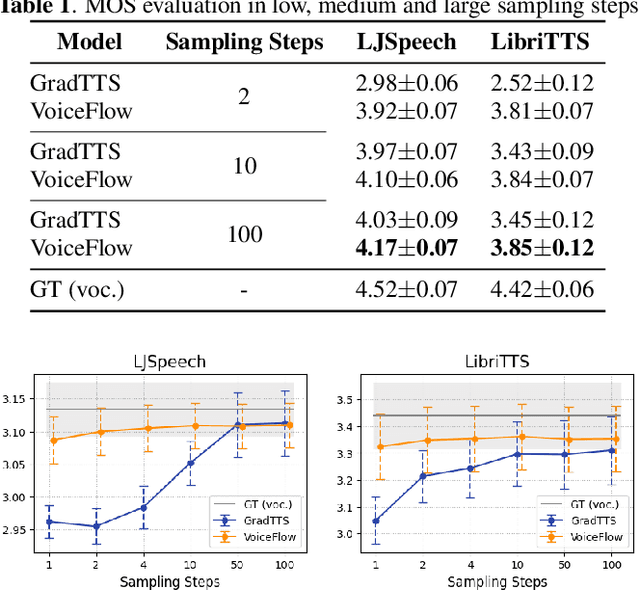


Although diffusion models in text-to-speech have become a popular choice due to their strong generative ability, the intrinsic complexity of sampling from diffusion models harms their efficiency. Alternatively, we propose VoiceFlow, an acoustic model that utilizes a rectified flow matching algorithm to achieve high synthesis quality with a limited number of sampling steps. VoiceFlow formulates the process of generating mel-spectrograms into an ordinary differential equation conditional on text inputs, whose vector field is then estimated. The rectified flow technique then effectively straightens its sampling trajectory for efficient synthesis. Subjective and objective evaluations on both single and multi-speaker corpora showed the superior synthesis quality of VoiceFlow compared to the diffusion counterpart. Ablation studies further verified the validity of the rectified flow technique in VoiceFlow.
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
Jun 25, 2023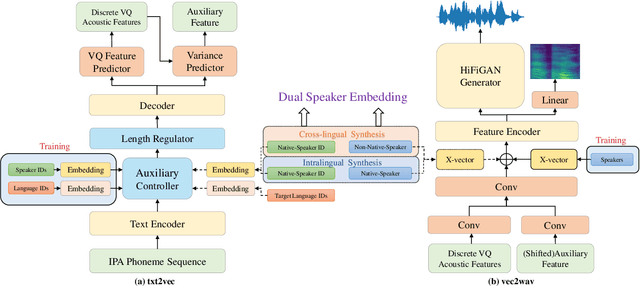
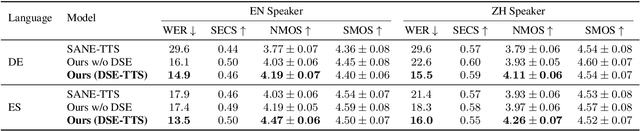
Although high-fidelity speech can be obtained for intralingual speech synthesis, cross-lingual text-to-speech (CTTS) is still far from satisfactory as it is difficult to accurately retain the speaker timbres(i.e. speaker similarity) and eliminate the accents from their first language(i.e. nativeness). In this paper, we demonstrated that vector-quantized(VQ) acoustic feature contains less speaker information than mel-spectrogram. Based on this finding, we propose a novel dual speaker embedding TTS (DSE-TTS) framework for CTTS with authentic speaking style. Here, one embedding is fed to the acoustic model to learn the linguistic speaking style, while the other one is integrated into the vocoder to mimic the target speaker's timbre. Experiments show that by combining both embeddings, DSE-TTS significantly outperforms the state-of-the-art SANE-TTS in cross-lingual synthesis, especially in terms of nativeness.