 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid Harwath
SoundingActions: Learning How Actions Sound from Narrated Egocentric Videos
Apr 08, 2024
We propose a novel self-supervised embedding to learn how actions sound from narrated in-the-wild egocentric videos. Whereas existing methods rely on curated data with known audio-visual correspondence, our multimodal contrastive-consensus coding (MC3) embedding reinforces the associations between audio, language, and vision when all modality pairs agree, while diminishing those associations when any one pair does not. We show our approach can successfully discover how the long tail of human actions sound from egocentric video, outperforming an array of recent multimodal embedding techniques on two datasets (Ego4D and EPIC-Sounds) and multiple cross-modal tasks.
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
Mar 25, 2024We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
SpeechCLIP+: Self-supervised multi-task representation learning for speech via CLIP and speech-image data
Feb 10, 2024The recently proposed visually grounded speech model SpeechCLIP is an innovative framework that bridges speech and text through images via CLIP without relying on text transcription. On this basis, this paper introduces two extensions to SpeechCLIP. First, we apply the Continuous Integrate-and-Fire (CIF) module to replace a fixed number of CLS tokens in the cascaded architecture. Second, we propose a new hybrid architecture that merges the cascaded and parallel architectures of SpeechCLIP into a multi-task learning framework. Our experimental evaluation is performed on the Flickr8k and SpokenCOCO datasets. The results show that in the speech keyword extraction task, the CIF-based cascaded SpeechCLIP model outperforms the previous cascaded SpeechCLIP model using a fixed number of CLS tokens. Furthermore, through our hybrid architecture, cascaded task learning boosts the performance of the parallel branch in image-speech retrieval tasks.
Integrating Self-supervised Speech Model with Pseudo Word-level Targets from Visually-grounded Speech Model
Feb 08, 2024Recent advances in self-supervised speech models have shown significant improvement in many downstream tasks. However, these models predominantly centered on frame-level training objectives, which can fall short in spoken language understanding tasks that require semantic comprehension. Existing works often rely on additional speech-text data as intermediate targets, which is costly in the real-world setting. To address this challenge, we propose Pseudo-Word HuBERT (PW-HuBERT), a framework that integrates pseudo word-level targets into the training process, where the targets are derived from a visually-ground speech model, notably eliminating the need for speech-text paired data. Our experimental results on four spoken language understanding (SLU) benchmarks suggest the superiority of our model in capturing semantic information.
BAT: Learning to Reason about Spatial Sounds with Large Language Models
Feb 02, 2024Spatial sound reasoning is a fundamental human skill, enabling us to navigate and interpret our surroundings based on sound. In this paper we present BAT, which combines the spatial sound perception ability of a binaural acoustic scene analysis model with the natural language reasoning capabilities of a large language model (LLM) to replicate this innate ability. To address the lack of existing datasets of in-the-wild spatial sounds, we synthesized a binaural audio dataset using AudioSet and SoundSpaces 2.0. Next, we developed SpatialSoundQA, a spatial sound-based question-answering dataset, offering a range of QA tasks that train BAT in various aspects of spatial sound perception and reasoning. The acoustic front end encoder of BAT is a novel spatial audio encoder named Spatial Audio Spectrogram Transformer, or Spatial-AST, which by itself achieves strong performance across sound event detection, spatial localization, and distance estimation. By integrating Spatial-AST with LLaMA-2 7B model, BAT transcends standard Sound Event Localization and Detection (SELD) tasks, enabling the model to reason about the relationships between the sounds in its environment. Our experiments demonstrate BAT's superior performance on both spatial sound perception and reasoning, showcasing the immense potential of LLMs in navigating and interpreting complex spatial audio environments.
Audio-Visual Neural Syntax Acquisition
Oct 11, 2023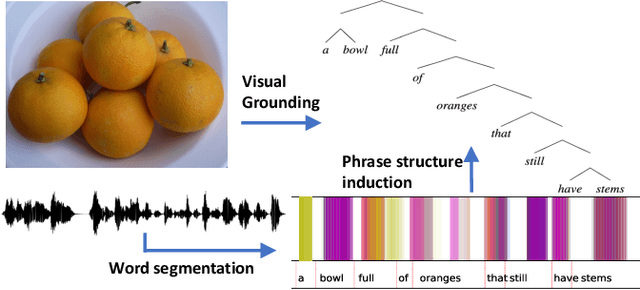

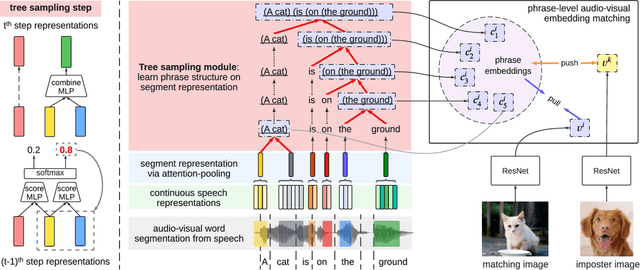
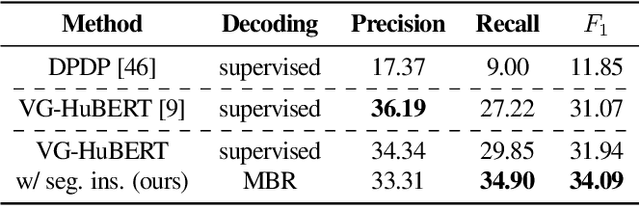
We study phrase structure induction from visually-grounded speech. The core idea is to first segment the speech waveform into sequences of word segments, and subsequently induce phrase structure using the inferred segment-level continuous representations. We present the Audio-Visual Neural Syntax Learner (AV-NSL) that learns phrase structure by listening to audio and looking at images, without ever being exposed to text. By training on paired images and spoken captions, AV-NSL exhibits the capability to infer meaningful phrase structures that are comparable to those derived by naturally-supervised text parsers, for both English and German. Our findings extend prior work in unsupervised language acquisition from speech and grounded grammar induction, and present one approach to bridge the gap between the two topics.
AV-SUPERB: A Multi-Task Evaluation Benchmark for Audio-Visual Representation Models
Sep 19, 2023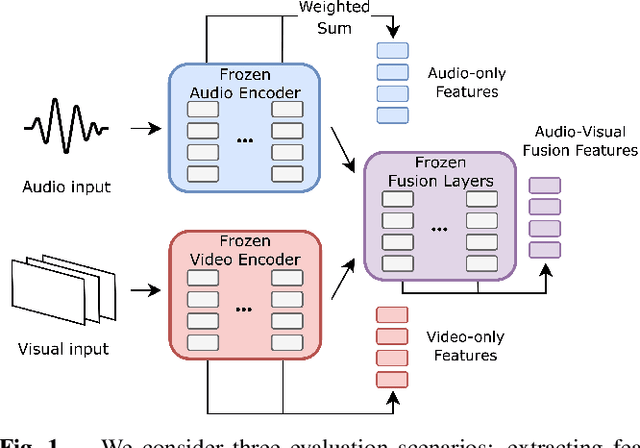

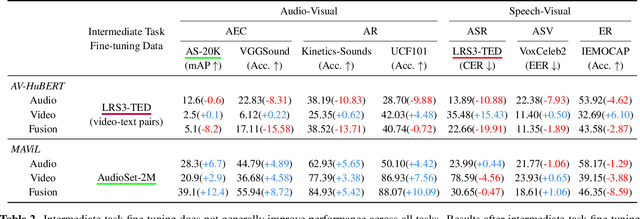
Audio-visual representation learning aims to develop systems with human-like perception by utilizing correlation between auditory and visual information. However, current models often focus on a limited set of tasks, and generalization abilities of learned representations are unclear. To this end, we propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing. We evaluate 5 recent self-supervised models and show that none of these models generalize to all tasks, emphasizing the need for future study on improving universal model performance. In addition, we show that representations may be improved with intermediate-task fine-tuning and audio event classification with AudioSet serves as a strong intermediate task. We release our benchmark with evaluation code and a model submission platform to encourage further research in audio-visual learning.
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos
Jun 27, 2023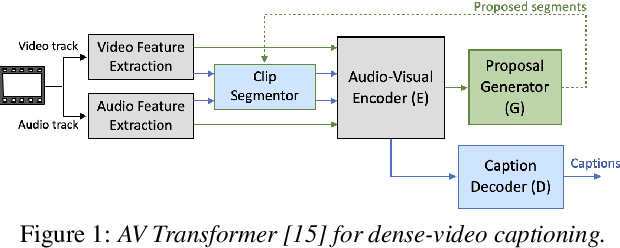

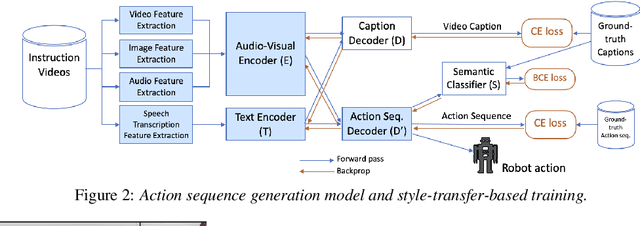
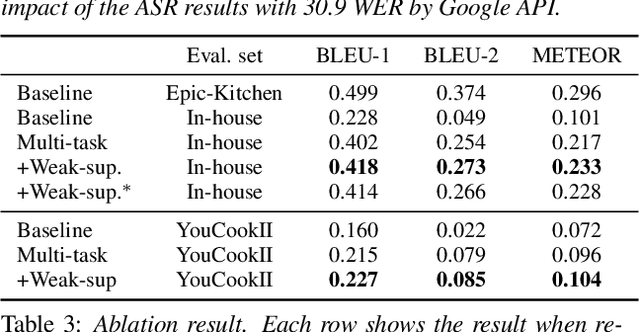
To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
When to Use Efficient Self Attention? Profiling Text, Speech and Image Transformer Variants
Jun 14, 2023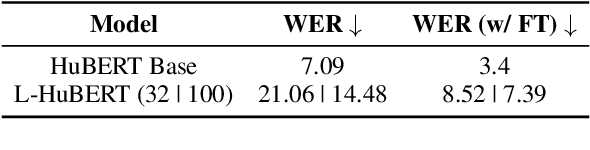
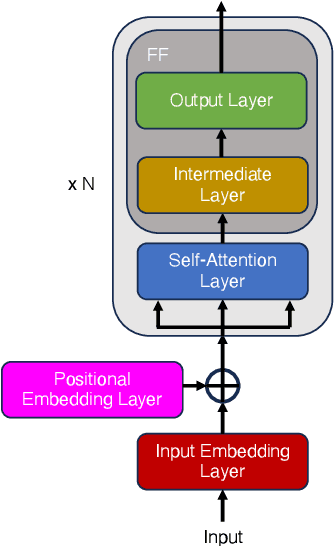
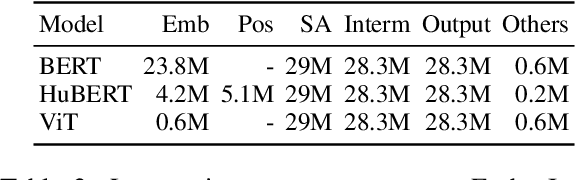
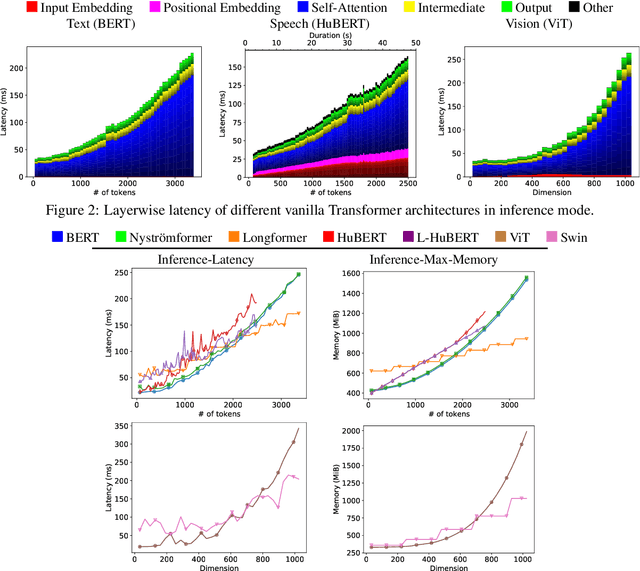
We present the first unified study of the efficiency of self-attention-based Transformer variants spanning text, speech and vision. We identify input length thresholds (tipping points) at which efficient Transformer variants become more efficient than vanilla models, using a variety of efficiency metrics (latency, throughput, and memory). To conduct this analysis for speech, we introduce L-HuBERT, a novel local-attention variant of a self-supervised speech model. We observe that these thresholds are (a) much higher than typical dataset sequence lengths and (b) dependent on the metric and modality, showing that choosing the right model depends on modality, task type (long-form vs. typical context) and resource constraints (time vs. memory). By visualising the breakdown of the computational costs for transformer components, we also show that non-self-attention components exhibit significant computational costs. We release our profiling toolkit at https://github.com/ajd12342/profiling-transformers .
Unit-based Speech-to-Speech Translation Without Parallel Data
May 24, 2023
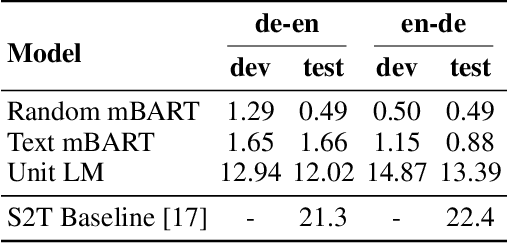
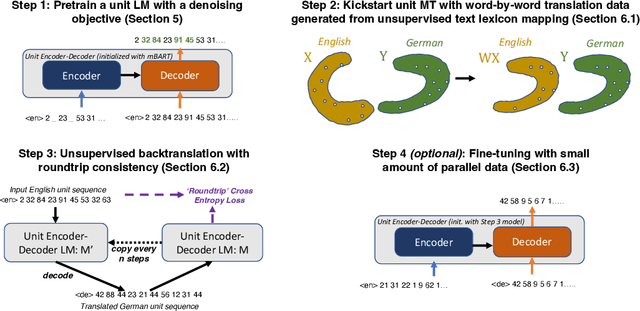
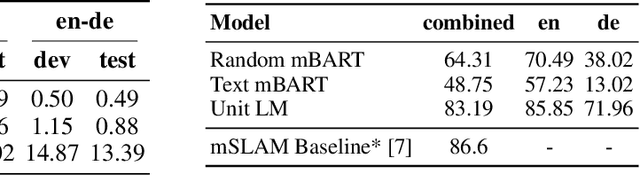
We propose an unsupervised speech-to-speech translation (S2ST) system that does not rely on parallel data between the source and target languages. Our approach maps source and target language speech signals into automatically discovered, discrete units and reformulates the problem as unsupervised unit-to-unit machine translation. We develop a three-step training procedure that involves (a) pre-training an unit-based encoder-decoder language model with a denoising objective (b) training it with word-by-word translated utterance pairs created by aligning monolingual text embedding spaces and (c) running unsupervised backtranslation bootstrapping off of the initial translation model. Our approach avoids mapping the speech signal into text and uses speech-to-unit and unit-to-speech models instead of automatic speech recognition and text to speech models. We evaluate our model on synthetic-speaker Europarl-ST English-German and German-English evaluation sets, finding that unit-based translation is feasible under this constrained scenario, achieving 9.29 ASR-BLEU in German to English and 8.07 in English to German.