 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKristen Grauman
SoundingActions: Learning How Actions Sound from Narrated Egocentric Videos
Apr 08, 2024
We propose a novel self-supervised embedding to learn how actions sound from narrated in-the-wild egocentric videos. Whereas existing methods rely on curated data with known audio-visual correspondence, our multimodal contrastive-consensus coding (MC3) embedding reinforces the associations between audio, language, and vision when all modality pairs agree, while diminishing those associations when any one pair does not. We show our approach can successfully discover how the long tail of human actions sound from egocentric video, outperforming an array of recent multimodal embedding techniques on two datasets (Ego4D and EPIC-Sounds) and multiple cross-modal tasks.
Put Myself in Your Shoes: Lifting the Egocentric Perspective from Exocentric Videos
Mar 11, 2024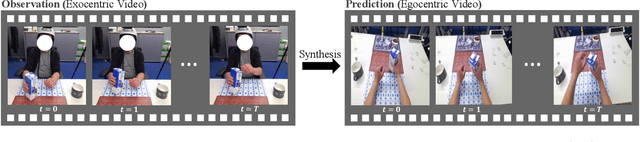
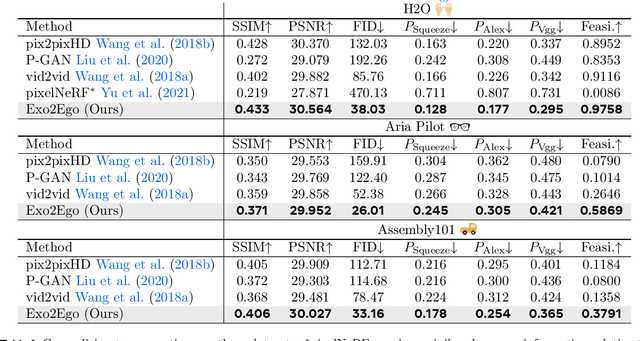
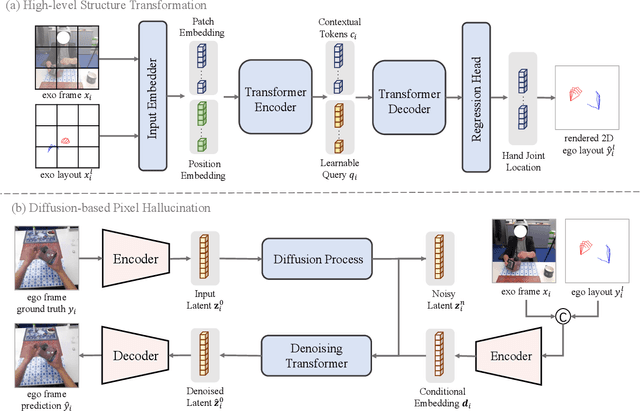
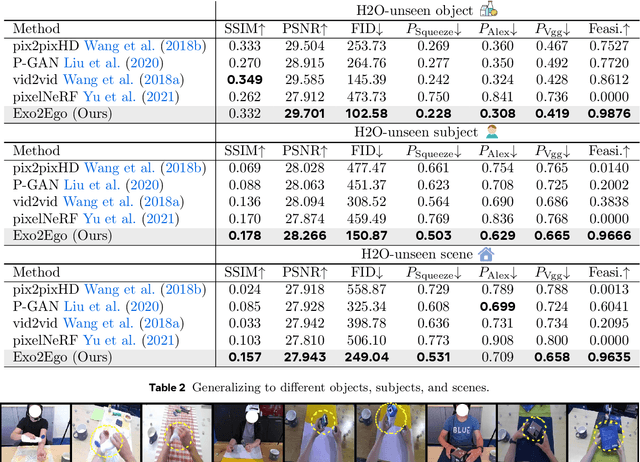
We investigate exocentric-to-egocentric cross-view translation, which aims to generate a first-person (egocentric) view of an actor based on a video recording that captures the actor from a third-person (exocentric) perspective. To this end, we propose a generative framework called Exo2Ego that decouples the translation process into two stages: high-level structure transformation, which explicitly encourages cross-view correspondence between exocentric and egocentric views, and a diffusion-based pixel-level hallucination, which incorporates a hand layout prior to enhance the fidelity of the generated egocentric view. To pave the way for future advancements in this field, we curate a comprehensive exo-to-ego cross-view translation benchmark. It consists of a diverse collection of synchronized ego-exo tabletop activity video pairs sourced from three public datasets: H2O, Aria Pilot, and Assembly101. The experimental results validate that Exo2Ego delivers photorealistic video results with clear hand manipulation details and outperforms several baselines in terms of both synthesis quality and generalization ability to new actions.
Detours for Navigating Instructional Videos
Jan 03, 2024We introduce the video detours problem for navigating instructional videos. Given a source video and a natural language query asking to alter the how-to video's current path of execution in a certain way, the goal is to find a related ''detour video'' that satisfies the requested alteration. To address this challenge, we propose VidDetours, a novel video-language approach that learns to retrieve the targeted temporal segments from a large repository of how-to's using video-and-text conditioned queries. Furthermore, we devise a language-based pipeline that exploits how-to video narration text to create weakly supervised training data. We demonstrate our idea applied to the domain of how-to cooking videos, where a user can detour from their current recipe to find steps with alternate ingredients, tools, and techniques. Validating on a ground truth annotated dataset of 16K samples, we show our model's significant improvements over best available methods for video retrieval and question answering, with recall rates exceeding the state of the art by 35%.
Learning Object State Changes in Videos: An Open-World Perspective
Dec 19, 2023Object State Changes (OSCs) are pivotal for video understanding. While humans can effortlessly generalize OSC understanding from familiar to unknown objects, current approaches are confined to a closed vocabulary. Addressing this gap, we introduce a novel open-world formulation for the video OSC problem. The goal is to temporally localize the three stages of an OSC -- the object's initial state, its transitioning state, and its end state -- whether or not the object has been observed during training. Towards this end, we develop VidOSC, a holistic learning approach that: (1) leverages text and vision-language models for supervisory signals to obviate manually labeling OSC training data, and (2) abstracts fine-grained shared state representations from objects to enhance generalization. Furthermore, we present HowToChange, the first open-world benchmark for video OSC localization, which offers an order of magnitude increase in the label space and annotation volume compared to the best existing benchmark. Experimental results demonstrate the efficacy of our approach, in both traditional closed-world and open-world scenarios.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023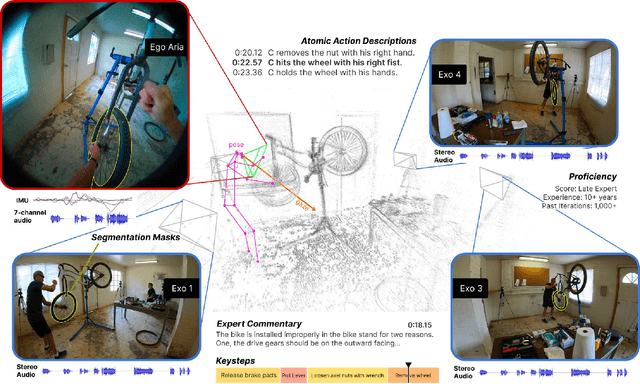


We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Self-Supervised Visual Acoustic Matching
Jul 27, 2023
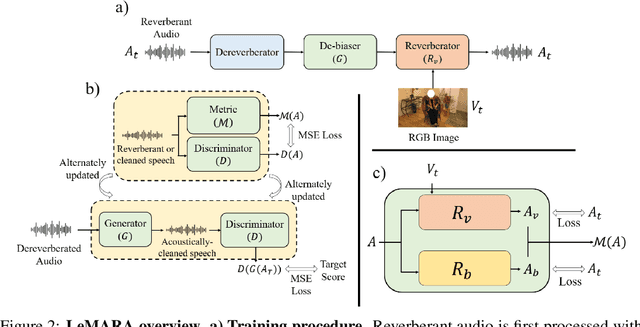


Acoustic matching aims to re-synthesize an audio clip to sound as if it were recorded in a target acoustic environment. Existing methods assume access to paired training data, where the audio is observed in both source and target environments, but this limits the diversity of training data or requires the use of simulated data or heuristics to create paired samples. We propose a self-supervised approach to visual acoustic matching where training samples include only the target scene image and audio -- without acoustically mismatched source audio for reference. Our approach jointly learns to disentangle room acoustics and re-synthesize audio into the target environment, via a conditional GAN framework and a novel metric that quantifies the level of residual acoustic information in the de-biased audio. Training with either in-the-wild web data or simulated data, we demonstrate it outperforms the state-of-the-art on multiple challenging datasets and a wide variety of real-world audio and environments.
Video-Mined Task Graphs for Keystep Recognition in Instructional Videos
Jul 17, 2023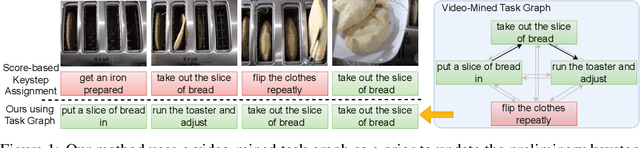
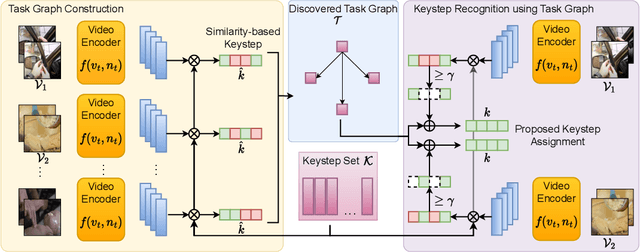
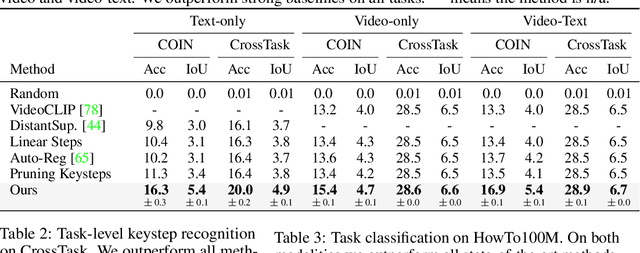
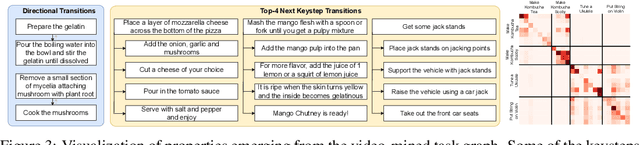
Procedural activity understanding requires perceiving human actions in terms of a broader task, where multiple keysteps are performed in sequence across a long video to reach a final goal state -- such as the steps of a recipe or a DIY fix-it task. Prior work largely treats keystep recognition in isolation of this broader structure, or else rigidly confines keysteps to align with a predefined sequential script. We propose discovering a task graph automatically from how-to videos to represent probabilistically how people tend to execute keysteps, and then leverage this graph to regularize keystep recognition in novel videos. On multiple datasets of real-world instructional videos, we show the impact: more reliable zero-shot keystep localization and improved video representation learning, exceeding the state of the art.
Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos
Jul 10, 2023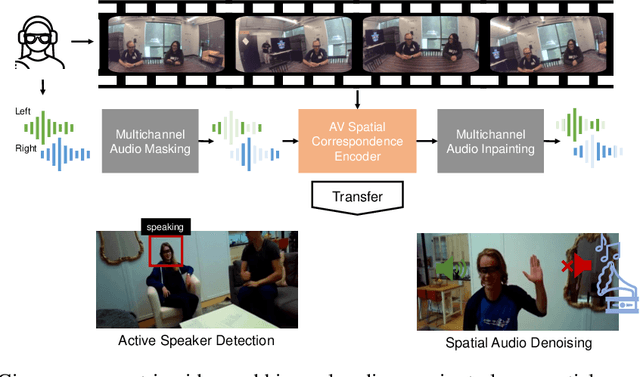
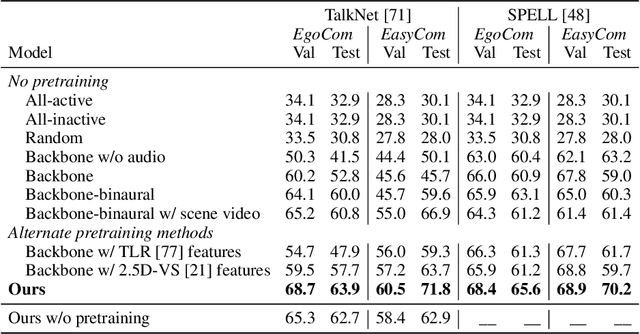
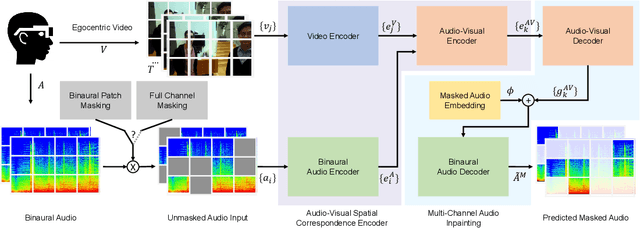
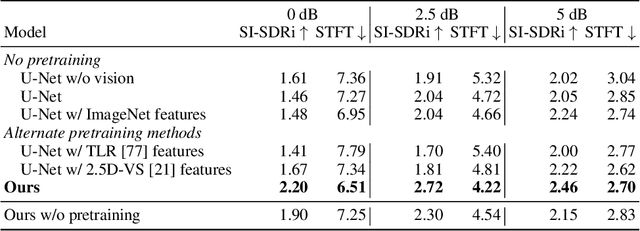
We propose a self-supervised method for learning representations based on spatial audio-visual correspondences in egocentric videos. In particular, our method leverages a masked auto-encoding framework to synthesize masked binaural audio through the synergy of audio and vision, thereby learning useful spatial relationships between the two modalities. We use our pretrained features to tackle two downstream video tasks requiring spatial understanding in social scenarios: active speaker detection and spatial audio denoising. We show through extensive experiments that our features are generic enough to improve over multiple state-of-the-art baselines on two public challenging egocentric video datasets, EgoCom and EasyCom. Project: http://vision.cs.utexas.edu/projects/ego_av_corr.
SpotEM: Efficient Video Search for Episodic Memory
Jun 28, 2023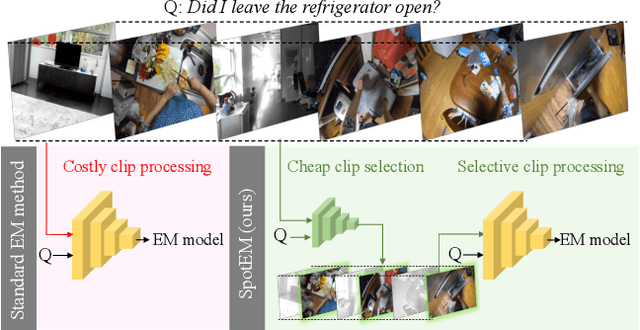
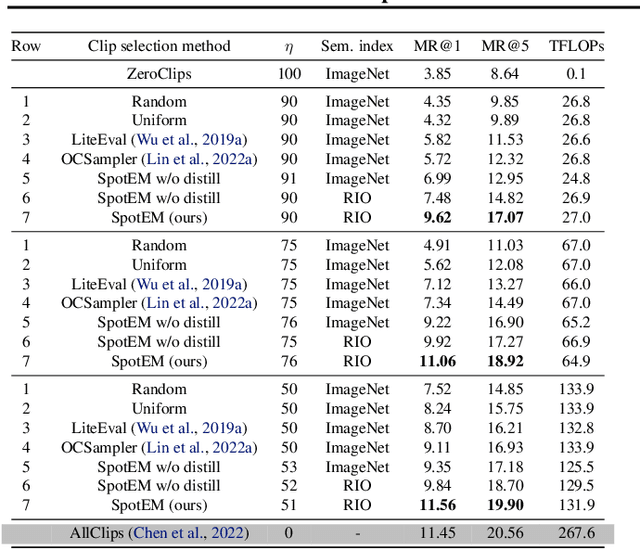
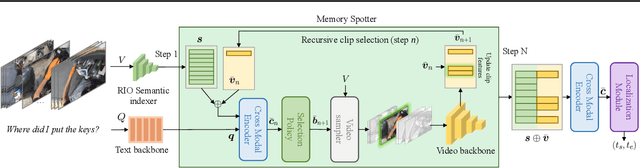
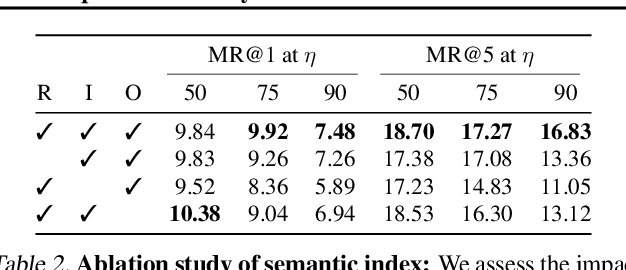
The goal in episodic memory (EM) is to search a long egocentric video to answer a natural language query (e.g., "where did I leave my purse?"). Existing EM methods exhaustively extract expensive fixed-length clip features to look everywhere in the video for the answer, which is infeasible for long wearable-camera videos that span hours or even days. We propose SpotEM, an approach to achieve efficiency for a given EM method while maintaining good accuracy. SpotEM consists of three key ideas: 1) a novel clip selector that learns to identify promising video regions to search conditioned on the language query; 2) a set of low-cost semantic indexing features that capture the context of rooms, objects, and interactions that suggest where to look; and 3) distillation losses that address the optimization issues arising from end-to-end joint training of the clip selector and EM model. Our experiments on 200+ hours of video from the Ego4D EM Natural Language Queries benchmark and three different EM models demonstrate the effectiveness of our approach: computing only 10% - 25% of the clip features, we preserve 84% - 97% of the original EM model's accuracy. Project page: https://vision.cs.utexas.edu/projects/spotem
Single-Stage Visual Query Localization in Egocentric Videos
Jun 15, 2023
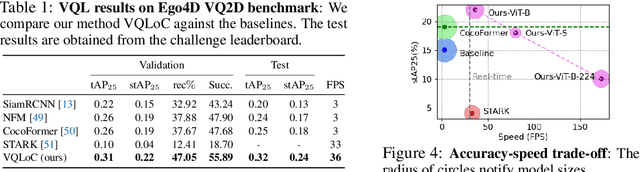
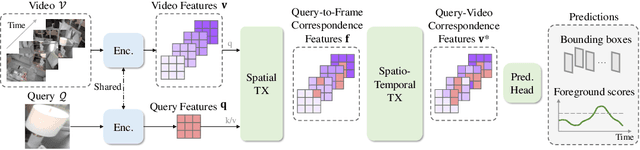
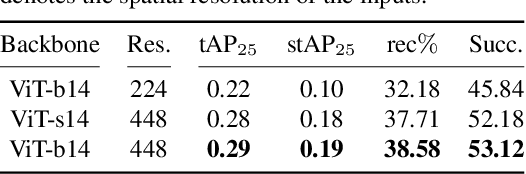
Visual Query Localization on long-form egocentric videos requires spatio-temporal search and localization of visually specified objects and is vital to build episodic memory systems. Prior work develops complex multi-stage pipelines that leverage well-established object detection and tracking methods to perform VQL. However, each stage is independently trained and the complexity of the pipeline results in slow inference speeds. We propose VQLoC, a novel single-stage VQL framework that is end-to-end trainable. Our key idea is to first build a holistic understanding of the query-video relationship and then perform spatio-temporal localization in a single shot manner. Specifically, we establish the query-video relationship by jointly considering query-to-frame correspondences between the query and each video frame and frame-to-frame correspondences between nearby video frames. Our experiments demonstrate that our approach outperforms prior VQL methods by 20% accuracy while obtaining a 10x improvement in inference speed. VQLoC is also the top entry on the Ego4D VQ2D challenge leaderboard. Project page: https://hwjiang1510.github.io/VQLoC/