 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Dong
Counterfactual Explanations for Face Forgery Detection via Adversarial Removal of Artifacts
Apr 12, 2024
Highly realistic AI generated face forgeries known as deepfakes have raised serious social concerns. Although DNN-based face forgery detection models have achieved good performance, they are vulnerable to latest generative methods that have less forgery traces and adversarial attacks. This limitation of generalization and robustness hinders the credibility of detection results and requires more explanations. In this work, we provide counterfactual explanations for face forgery detection from an artifact removal perspective. Specifically, we first invert the forgery images into the StyleGAN latent space, and then adversarially optimize their latent representations with the discrimination supervision from the target detection model. We verify the effectiveness of the proposed explanations from two aspects: (1) Counterfactual Trace Visualization: the enhanced forgery images are useful to reveal artifacts by visually contrasting the original images and two different visualization methods; (2) Transferable Adversarial Attacks: the adversarial forgery images generated by attacking the detection model are able to mislead other detection models, implying the removed artifacts are general. Extensive experiments demonstrate that our method achieves over 90% attack success rate and superior attack transferability. Compared with naive adversarial noise methods, our method adopts both generative and discriminative model priors, and optimize the latent representations in a synthesis-by-analysis way, which forces the search of counterfactual explanations on the natural face manifold. Thus, more general counterfactual traces can be found and better adversarial attack transferability can be achieved.
Convergence to Nash Equilibrium and No-regret Guarantee in (Markov) Potential Games
Apr 04, 2024In this work, we study potential games and Markov potential games under stochastic cost and bandit feedback. We propose a variant of the Frank-Wolfe algorithm with sufficient exploration and recursive gradient estimation, which provably converges to the Nash equilibrium while attaining sublinear regret for each individual player. Our algorithm simultaneously achieves a Nash regret and a regret bound of $O(T^{4/5})$ for potential games, which matches the best available result, without using additional projection steps. Through carefully balancing the reuse of past samples and exploration of new samples, we then extend the results to Markov potential games and improve the best available Nash regret from $O(T^{5/6})$ to $O(T^{4/5})$. Moreover, our algorithm requires no knowledge of the game, such as the distribution mismatch coefficient, which provides more flexibility in its practical implementation. Experimental results corroborate our theoretical findings and underscore the practical effectiveness of our method.
Latent Watermark: Inject and Detect Watermarks in Latent Diffusion Space
Mar 30, 2024Watermarking is a tool for actively identifying and attributing the images generated by latent diffusion models. Existing methods face the dilemma of watermark robustness and image quality. The reason for this dilemma is that watermark detection is performed in pixel space, implying an intrinsic link between image quality and watermark robustness. In this paper, we highlight that an effective solution to the problem is to both inject and detect watermarks in latent space, and propose Latent Watermark (LW) with a progressive training strategy. Experiments show that compared to the recently proposed methods such as StegaStamp, StableSignature, RoSteALS and TreeRing, LW not only surpasses them in terms of robustness but also offers superior image quality. When we inject 64-bit messages, LW can achieve an identification performance close to 100% and an attribution performance above 97% under 9 single-attack scenarios and one all-attack scenario. Our code will be available on GitHub.
Artifact Feature Purification for Cross-domain Detection of AI-generated Images
Mar 17, 2024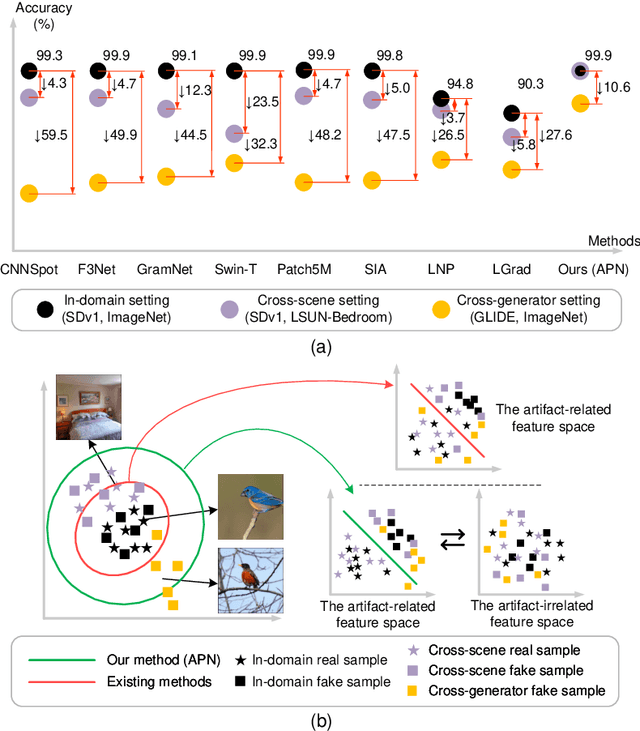
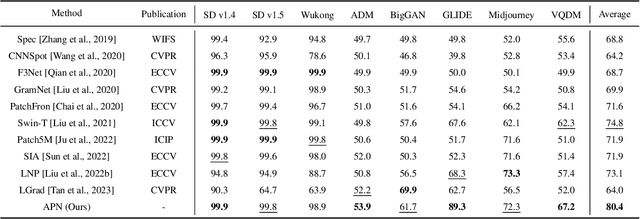
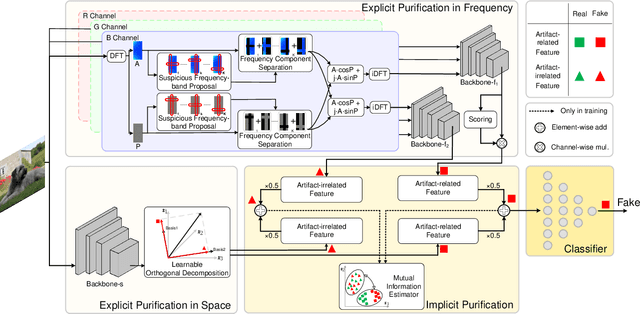
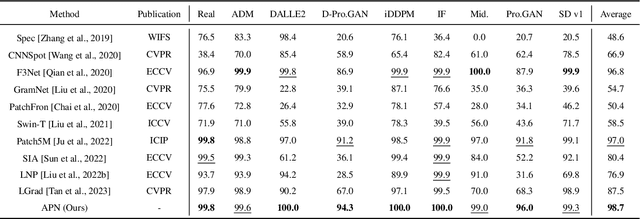
In the era of AIGC, the fast development of visual content generation technologies, such as diffusion models, bring potential security risks to our society. Existing generated image detection methods suffer from performance drop when faced with out-of-domain generators and image scenes. To relieve this problem, we propose Artifact Purification Network (APN) to facilitate the artifact extraction from generated images through the explicit and implicit purification processes. For the explicit one, a suspicious frequency-band proposal method and a spatial feature decomposition method are proposed to extract artifact-related features. For the implicit one, a training strategy based on mutual information estimation is proposed to further purify the artifact-related features. Experiments show that for cross-generator detection, the average accuracy of APN is 5.6% ~ 16.4% higher than the previous 10 methods on GenImage dataset and 1.7% ~ 50.1% on DiffusionForensics dataset. For cross-scene detection, APN maintains its high performance. Via visualization analysis, we find that the proposed method extracts flexible forgery patterns and condenses the forgery information diluted in irrelevant features. We also find that the artifact features APN focuses on across generators and scenes are global and diverse. The code will be available on GitHub.
Aria Everyday Activities Dataset
Feb 22, 2024We present Aria Everyday Activities (AEA) Dataset, an egocentric multimodal open dataset recorded using Project Aria glasses. AEA contains 143 daily activity sequences recorded by multiple wearers in five geographically diverse indoor locations. Each of the recording contains multimodal sensor data recorded through the Project Aria glasses. In addition, AEA provides machine perception data including high frequency globally aligned 3D trajectories, scene point cloud, per-frame 3D eye gaze vector and time aligned speech transcription. In this paper, we demonstrate a few exemplar research applications enabled by this dataset, including neural scene reconstruction and prompted segmentation. AEA is an open source dataset that can be downloaded from https://www.projectaria.com/datasets/aea/. We are also providing open-source implementations and examples of how to use the dataset in Project Aria Tools https://github.com/facebookresearch/projectaria_tools.
SeFi-IDE: Semantic-Fidelity Identity Embedding for Personalized Diffusion-Based Generation
Jan 31, 2024Advanced diffusion-based Text-to-Image (T2I) models, such as the Stable Diffusion Model, have made significant progress in generating diverse and high-quality images using text prompts alone. However, T2I models are unable to accurately map identities (IDs) when non-famous users require personalized image generation. The main problem is that existing T2I models do not learn the ID-image alignments of new users. The previous methods either failed to accurately fit the face region or lost the interactive generative ability with other existing concepts in T2I models (i.e., unable to generate other concepts described in given prompts such as scenes, actions, and facial attributes). In this paper, we focus on accurate and semantic-fidelity ID embedding into the Stable Diffusion Model for personalized generation. We address this challenge from two perspectives: face-wise region fitting, and semantic-fidelity token optimization. Specifically, we first visualize the attention overfit problem, and propose a face-wise attention loss to fit the face region instead of the whole target image. This key trick significantly enhances the ID accuracy and interactive generative ability with other existing concepts. Then, we optimize one ID representation as multiple per-stage tokens where each token contains two disentangled features. This expansion of the textual conditioning space enhances semantic-fidelity control. Extensive experiments validate that our results exhibit superior ID accuracy and manipulation ability compared to previous methods.
Is It Possible to Backdoor Face Forgery Detection with Natural Triggers?
Dec 31, 2023Deep neural networks have significantly improved the performance of face forgery detection models in discriminating Artificial Intelligent Generated Content (AIGC). However, their security is significantly threatened by the injection of triggers during model training (i.e., backdoor attacks). Although existing backdoor defenses and manual data selection can mitigate those using human-eye-sensitive triggers, such as patches or adversarial noises, the more challenging natural backdoor triggers remain insufficiently researched. To further investigate natural triggers, we propose a novel analysis-by-synthesis backdoor attack against face forgery detection models, which embeds natural triggers in the latent space. We thoroughly study such backdoor vulnerability from two perspectives: (1) Model Discrimination (Optimization-Based Trigger): we adopt a substitute detection model and find the trigger by minimizing the cross-entropy loss; (2) Data Distribution (Custom Trigger): we manipulate the uncommon facial attributes in the long-tailed distribution to generate poisoned samples without the supervision from detection models. Furthermore, to completely evaluate the detection models towards the latest AIGC, we utilize both state-of-the-art StyleGAN and Stable Diffusion for trigger generation. Finally, these backdoor triggers introduce specific semantic features to the generated poisoned samples (e.g., skin textures and smile), which are more natural and robust. Extensive experiments show that our method is superior from three levels: (1) Attack Success Rate: ours achieves a high attack success rate (over 99%) and incurs a small model accuracy drop (below 0.2%) with a low poisoning rate (less than 3%); (2) Backdoor Defense: ours shows better robust performance when faced with existing backdoor defense methods; (3) Human Inspection: ours is less human-eye-sensitive from a comprehensive user study.
RS-Corrector: Correcting the Racial Stereotypes in Latent Diffusion Models
Dec 20, 2023Recent text-conditioned image generation models have demonstrated an exceptional capacity to produce diverse and creative imagery with high visual quality. However, when pre-trained on billion-sized datasets randomly collected from the Internet, where potential biased human preferences exist, these models tend to produce images with common and recurring stereotypes, particularly for certain racial groups. In this paper, we conduct an initial analysis of the publicly available Stable Diffusion model and its derivatives, highlighting the presence of racial stereotypes. These models often generate distorted or biased images for certain racial groups, emphasizing stereotypical characteristics. To address these issues, we propose a framework called "RS-Corrector", designed to establish an anti-stereotypical preference in the latent space and update the latent code for refined generated results. The correction process occurs during the inference stage without requiring fine-tuning of the original model. Extensive empirical evaluations demonstrate that the introduced \themodel effectively corrects the racial stereotypes of the well-trained Stable Diffusion model while leaving the original model unchanged.
Learning Dense Correspondence for NeRF-Based Face Reenactment
Dec 19, 2023Face reenactment is challenging due to the need to establish dense correspondence between various face representations for motion transfer. Recent studies have utilized Neural Radiance Field (NeRF) as fundamental representation, which further enhanced the performance of multi-view face reenactment in photo-realism and 3D consistency. However, establishing dense correspondence between different face NeRFs is non-trivial, because implicit representations lack ground-truth correspondence annotations like mesh-based 3D parametric models (e.g., 3DMM) with index-aligned vertexes. Although aligning 3DMM space with NeRF-based face representations can realize motion control, it is sub-optimal for their limited face-only modeling and low identity fidelity. Therefore, we are inspired to ask: Can we learn the dense correspondence between different NeRF-based face representations without a 3D parametric model prior? To address this challenge, we propose a novel framework, which adopts tri-planes as fundamental NeRF representation and decomposes face tri-planes into three components: canonical tri-planes, identity deformations, and motion. In terms of motion control, our key contribution is proposing a Plane Dictionary (PlaneDict) module, which efficiently maps the motion conditions to a linear weighted addition of learnable orthogonal plane bases. To the best of our knowledge, our framework is the first method that achieves one-shot multi-view face reenactment without a 3D parametric model prior. Extensive experiments demonstrate that we produce better results in fine-grained motion control and identity preservation than previous methods.
AE-NeRF: Audio Enhanced Neural Radiance Field for Few Shot Talking Head Synthesis
Dec 18, 2023Audio-driven talking head synthesis is a promising topic with wide applications in digital human, film making and virtual reality. Recent NeRF-based approaches have shown superiority in quality and fidelity compared to previous studies. However, when it comes to few-shot talking head generation, a practical scenario where only few seconds of talking video is available for one identity, two limitations emerge: 1) they either have no base model, which serves as a facial prior for fast convergence, or ignore the importance of audio when building the prior; 2) most of them overlook the degree of correlation between different face regions and audio, e.g., mouth is audio related, while ear is audio independent. In this paper, we present Audio Enhanced Neural Radiance Field (AE-NeRF) to tackle the above issues, which can generate realistic portraits of a new speaker with fewshot dataset. Specifically, we introduce an Audio Aware Aggregation module into the feature fusion stage of the reference scheme, where the weight is determined by the similarity of audio between reference and target image. Then, an Audio-Aligned Face Generation strategy is proposed to model the audio related and audio independent regions respectively, with a dual-NeRF framework. Extensive experiments have shown AE-NeRF surpasses the state-of-the-art on image fidelity, audio-lip synchronization, and generalization ability, even in limited training set or training iterations.