 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlex Dimakis
Put Myself in Your Shoes: Lifting the Egocentric Perspective from Exocentric Videos
Mar 11, 2024
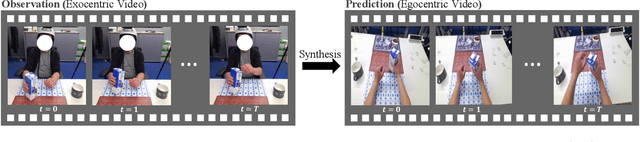
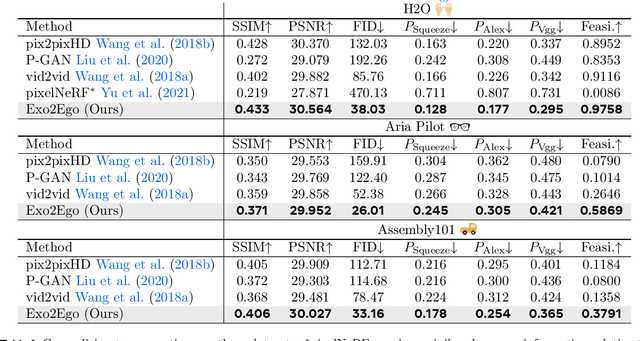
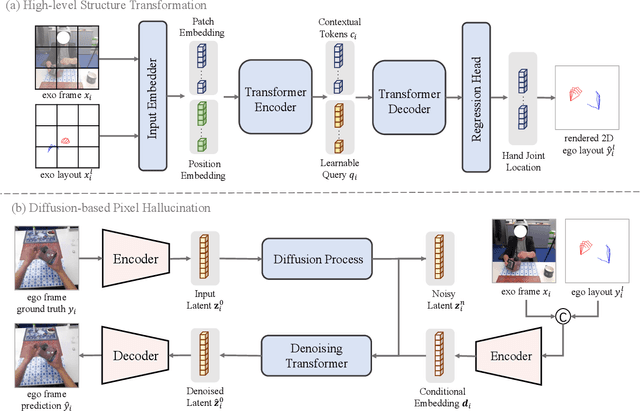
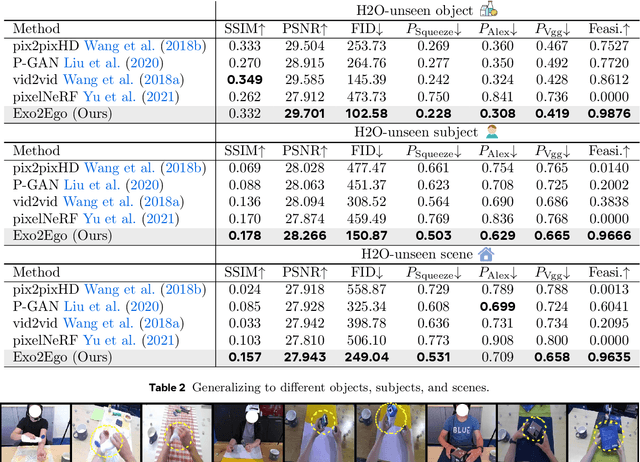
We investigate exocentric-to-egocentric cross-view translation, which aims to generate a first-person (egocentric) view of an actor based on a video recording that captures the actor from a third-person (exocentric) perspective. To this end, we propose a generative framework called Exo2Ego that decouples the translation process into two stages: high-level structure transformation, which explicitly encourages cross-view correspondence between exocentric and egocentric views, and a diffusion-based pixel-level hallucination, which incorporates a hand layout prior to enhance the fidelity of the generated egocentric view. To pave the way for future advancements in this field, we curate a comprehensive exo-to-ego cross-view translation benchmark. It consists of a diverse collection of synchronized ego-exo tabletop activity video pairs sourced from three public datasets: H2O, Aria Pilot, and Assembly101. The experimental results validate that Exo2Ego delivers photorealistic video results with clear hand manipulation details and outperforms several baselines in terms of both synthesis quality and generalization ability to new actions.
On a Foundation Model for Operating Systems
Dec 13, 2023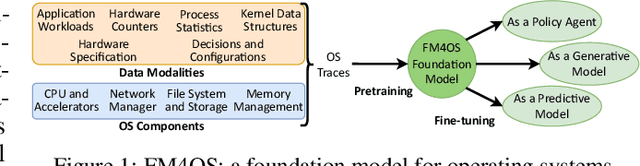
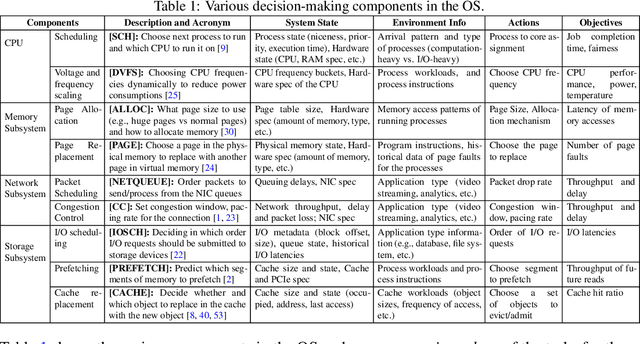
This paper lays down the research agenda for a domain-specific foundation model for operating systems (OSes). Our case for a foundation model revolves around the observations that several OS components such as CPU, memory, and network subsystems are interrelated and that OS traces offer the ideal dataset for a foundation model to grasp the intricacies of diverse OS components and their behavior in varying environments and workloads. We discuss a wide range of possibilities that then arise, from employing foundation models as policy agents to utilizing them as generators and predictors to assist traditional OS control algorithms. Our hope is that this paper spurs further research into OS foundation models and creating the next generation of operating systems for the evolving computing landscape.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023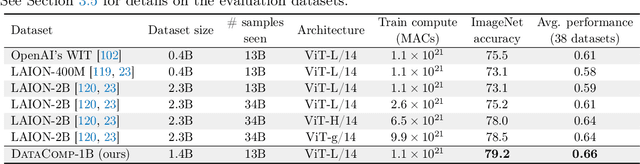
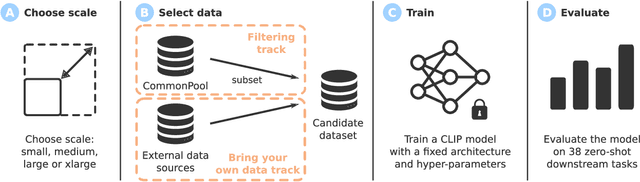


Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.