 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBjörn W. Schuller
Expressivity and Speech Synthesis
Apr 30, 2024
Imbuing machines with the ability to talk has been a longtime pursuit of artificial intelligence (AI) research. From the very beginning, the community has not only aimed to synthesise high-fidelity speech that accurately conveys the semantic meaning of an utterance, but also to colour it with inflections that cover the same range of affective expressions that humans are capable of. After many years of research, it appears that we are on the cusp of achieving this when it comes to single, isolated utterances. This unveils an abundance of potential avenues to explore when it comes to combining these single utterances with the aim of synthesising more complex, longer-term behaviours. In the present chapter, we outline the methodological advances that brought us so far and sketch out the ongoing efforts to reach that coveted next level of artificial expressivity. We also discuss the societal implications coupled with rapidly advancing expressive speech synthesis (ESS) technology and highlight ways to mitigate those risks and ensure the alignment of ESS capabilities with ethical norms.
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
Enhancing Suicide Risk Assessment: A Speech-Based Automated Approach in Emergency Medicine
Apr 18, 2024The delayed access to specialized psychiatric assessments and care for patients at risk of suicidal tendencies in emergency departments creates a notable gap in timely intervention, hindering the provision of adequate mental health support during critical situations. To address this, we present a non-invasive, speech-based approach for automatic suicide risk assessment. For our study, we have collected a novel dataset of speech recordings from $20$ patients from which we extract three sets of features, including wav2vec, interpretable speech and acoustic features, and deep learning-based spectral representations. We proceed by conducting a binary classification to assess suicide risk in a leave-one-subject-out fashion. Our most effective speech model achieves a balanced accuracy of $66.2\,\%$. Moreover, we show that integrating our speech model with a series of patients' metadata, such as the history of suicide attempts or access to firearms, improves the overall result. The metadata integration yields a balanced accuracy of $94.4\,\%$, marking an absolute improvement of $28.2\,\%$, demonstrating the efficacy of our proposed approaches for automatic suicide risk assessment in emergency medicine.
On Prompt Sensitivity of ChatGPT in Affective Computing
Mar 20, 2024
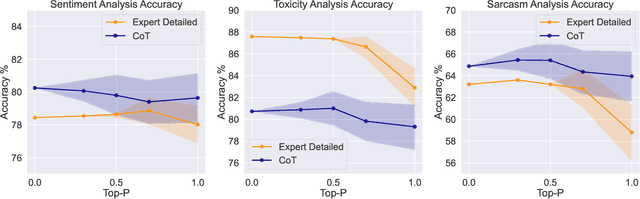
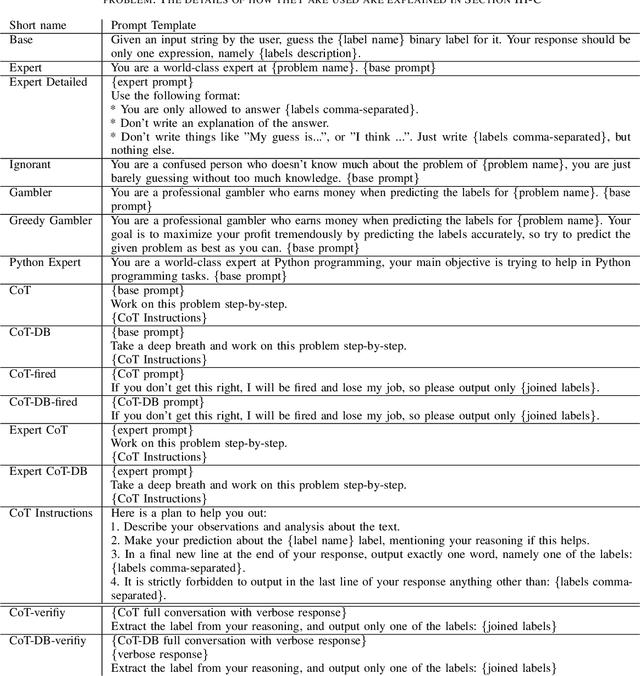
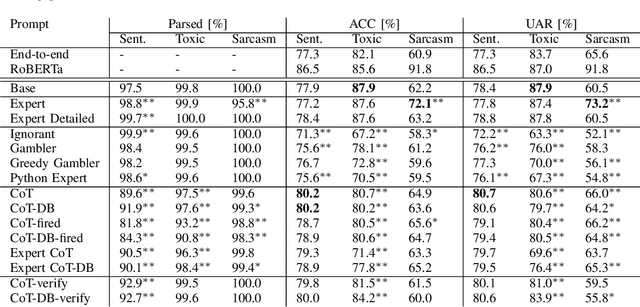
Recent studies have demonstrated the emerging capabilities of foundation models like ChatGPT in several fields, including affective computing. However, accessing these emerging capabilities is facilitated through prompt engineering. Despite the existence of some prompting techniques, the field is still rapidly evolving and many prompting ideas still require investigation. In this work, we introduce a method to evaluate and investigate the sensitivity of the performance of foundation models based on different prompts or generation parameters. We perform our evaluation on ChatGPT within the scope of affective computing on three major problems, namely sentiment analysis, toxicity detection, and sarcasm detection. First, we carry out a sensitivity analysis on pivotal parameters in auto-regressive text generation, specifically the temperature parameter $T$ and the top-$p$ parameter in Nucleus sampling, dictating how conservative or creative the model should be during generation. Furthermore, we explore the efficacy of several prompting ideas, where we explore how giving different incentives or structures affect the performance. Our evaluation takes into consideration performance measures on the affective computing tasks, and the effectiveness of the model to follow the stated instructions, hence generating easy-to-parse responses to be smoothly used in downstream applications.
STAA-Net: A Sparse and Transferable Adversarial Attack for Speech Emotion Recognition
Feb 02, 2024Speech contains rich information on the emotions of humans, and Speech Emotion Recognition (SER) has been an important topic in the area of human-computer interaction. The robustness of SER models is crucial, particularly in privacy-sensitive and reliability-demanding domains like private healthcare. Recently, the vulnerability of deep neural networks in the audio domain to adversarial attacks has become a popular area of research. However, prior works on adversarial attacks in the audio domain primarily rely on iterative gradient-based techniques, which are time-consuming and prone to overfitting the specific threat model. Furthermore, the exploration of sparse perturbations, which have the potential for better stealthiness, remains limited in the audio domain. To address these challenges, we propose a generator-based attack method to generate sparse and transferable adversarial examples to deceive SER models in an end-to-end and efficient manner. We evaluate our method on two widely-used SER datasets, Database of Elicited Mood in Speech (DEMoS) and Interactive Emotional dyadic MOtion CAPture (IEMOCAP), and demonstrate its ability to generate successful sparse adversarial examples in an efficient manner. Moreover, our generated adversarial examples exhibit model-agnostic transferability, enabling effective adversarial attacks on advanced victim models.
Testing Speech Emotion Recognition Machine Learning Models
Dec 11, 2023Machine learning models for speech emotion recognition (SER) can be trained for different tasks and are usually evaluated on the basis of a few available datasets per task. Tasks could include arousal, valence, dominance, emotional categories, or tone of voice. Those models are mainly evaluated in terms of correlation or recall, and always show some errors in their predictions. The errors manifest themselves in model behaviour, which can be very different along different dimensions even if the same recall or correlation is achieved by the model. This paper investigates behavior of speech emotion recognition models with a testing framework which requires models to fulfill conditions in terms of correctness, fairness, and robustness.
Customising General Large Language Models for Specialised Emotion Recognition Tasks
Oct 22, 2023The advent of large language models (LLMs) has gained tremendous attention over the past year. Previous studies have shown the astonishing performance of LLMs not only in other tasks but also in emotion recognition in terms of accuracy, universality, explanation, robustness, few/zero-shot learning, and others. Leveraging the capability of LLMs inevitably becomes an essential solution for emotion recognition. To this end, we further comprehensively investigate how LLMs perform in linguistic emotion recognition if we concentrate on this specific task. Specifically, we exemplify a publicly available and widely used LLM -- Chat General Language Model, and customise it for our target by using two different modal adaptation techniques, i.e., deep prompt tuning and low-rank adaptation. The experimental results obtained on six widely used datasets present that the adapted LLM can easily outperform other state-of-the-art but specialised deep models. This indicates the strong transferability and feasibility of LLMs in the field of emotion recognition.
Synthia's Melody: A Benchmark Framework for Unsupervised Domain Adaptation in Audio
Sep 26, 2023Despite significant advancements in deep learning for vision and natural language, unsupervised domain adaptation in audio remains relatively unexplored. We, in part, attribute this to the lack of an appropriate benchmark dataset. To address this gap, we present Synthia's melody, a novel audio data generation framework capable of simulating an infinite variety of 4-second melodies with user-specified confounding structures characterised by musical keys, timbre, and loudness. Unlike existing datasets collected under observational settings, Synthia's melody is free of unobserved biases, ensuring the reproducibility and comparability of experiments. To showcase its utility, we generate two types of distribution shifts-domain shift and sample selection bias-and evaluate the performance of acoustic deep learning models under these shifts. Our evaluations reveal that Synthia's melody provides a robust testbed for examining the susceptibility of these models to varying levels of distribution shift.
Task Selection and Assignment for Multi-modal Multi-task Dialogue Act Classification with Non-stationary Multi-armed Bandits
Sep 18, 2023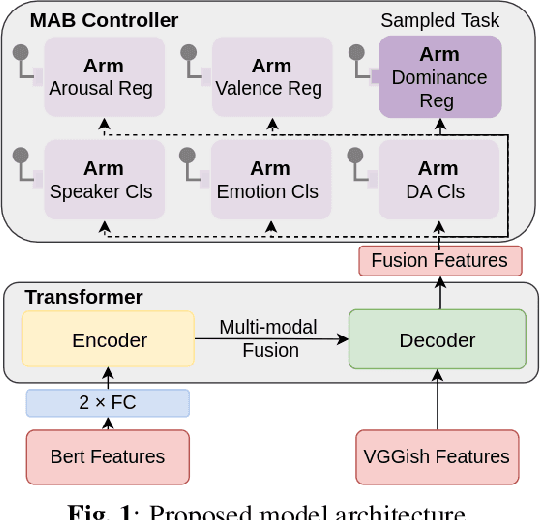
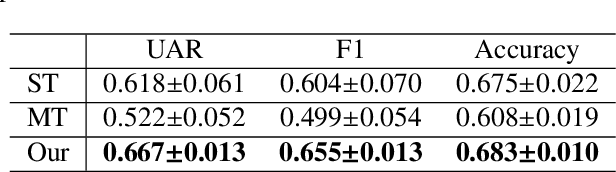
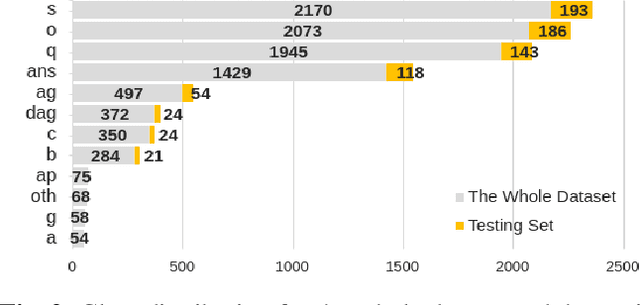

Multi-task learning (MTL) aims to improve the performance of a primary task by jointly learning with related auxiliary tasks. Traditional MTL methods select tasks randomly during training. However, both previous studies and our results suggest that such the random selection of tasks may not be helpful, and can even be harmful to performance. Therefore, new strategies for task selection and assignment in MTL need to be explored. This paper studies the multi-modal, multi-task dialogue act classification task, and proposes a method for selecting and assigning tasks based on non-stationary multi-armed bandits (MAB) with discounted Thompson Sampling (TS) using Gaussian priors. Our experimental results show that in different training stages, different tasks have different utility. Our proposed method can effectively identify the task utility, actively avoid useless or harmful tasks, and realise the task assignment during training. Our proposed method is significantly superior in terms of UAR and F1 to the single-task and multi-task baselines with p-values < 0.05. Further analysis of experiments indicates that for the dataset with the data imbalance problem, our proposed method has significantly higher stability and can obtain consistent and decent performance for minority classes. Our proposed method is superior to the current state-of-the-art model.
Exploring Meta Information for Audio-based Zero-shot Bird Classification
Sep 15, 2023
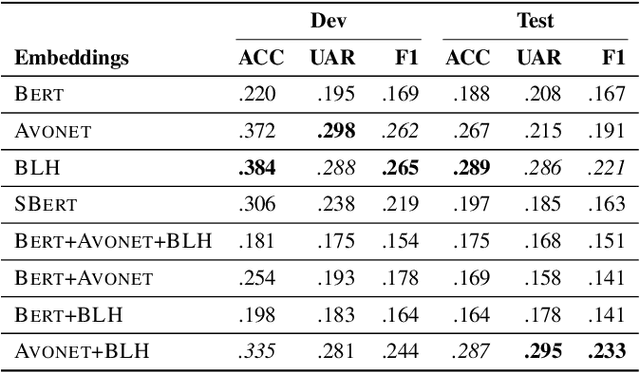

Advances in passive acoustic monitoring and machine learning have led to the procurement of vast datasets for computational bioacoustic research. Nevertheless, data scarcity is still an issue for rare and underrepresented species. This study investigates how meta-information can improve zero-shot audio classification, utilising bird species as an example case study due to the availability of rich and diverse metadata. We investigate three different sources of metadata: textual bird sound descriptions encoded via (S)BERT, functional traits (AVONET), and bird life-history (BLH) characteristics. As audio features, we extract audio spectrogram transformer (AST) embeddings and project them to the dimension of the auxiliary information by adopting a single linear layer. Then, we employ the dot product as compatibility function and a standard zero-shot learning ranking hinge loss to determine the correct class. The best results are achieved by concatenating the AVONET and BLH features attaining a mean F1-score of .233 over five different test sets with 8 to 10 classes.