 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Jing
STAA-Net: A Sparse and Transferable Adversarial Attack for Speech Emotion Recognition
Feb 02, 2024
Speech contains rich information on the emotions of humans, and Speech Emotion Recognition (SER) has been an important topic in the area of human-computer interaction. The robustness of SER models is crucial, particularly in privacy-sensitive and reliability-demanding domains like private healthcare. Recently, the vulnerability of deep neural networks in the audio domain to adversarial attacks has become a popular area of research. However, prior works on adversarial attacks in the audio domain primarily rely on iterative gradient-based techniques, which are time-consuming and prone to overfitting the specific threat model. Furthermore, the exploration of sparse perturbations, which have the potential for better stealthiness, remains limited in the audio domain. To address these challenges, we propose a generator-based attack method to generate sparse and transferable adversarial examples to deceive SER models in an end-to-end and efficient manner. We evaluate our method on two widely-used SER datasets, Database of Elicited Mood in Speech (DEMoS) and Interactive Emotional dyadic MOtion CAPture (IEMOCAP), and demonstrate its ability to generate successful sparse adversarial examples in an efficient manner. Moreover, our generated adversarial examples exhibit model-agnostic transferability, enabling effective adversarial attacks on advanced victim models.
U-DiT TTS: U-Diffusion Vision Transformer for Text-to-Speech
May 22, 2023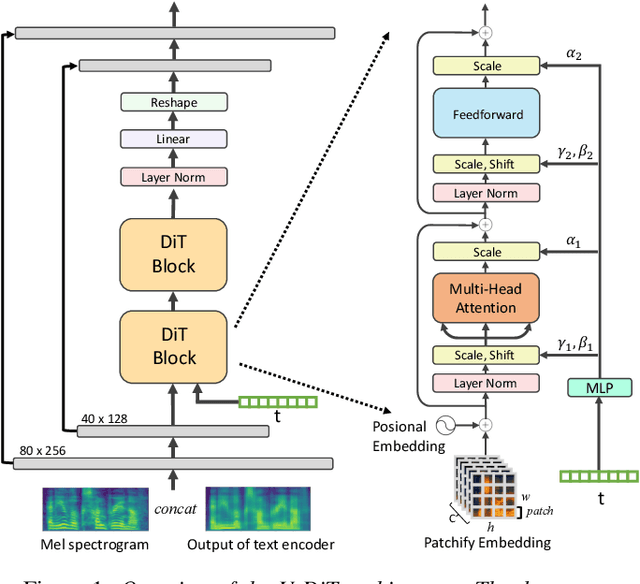
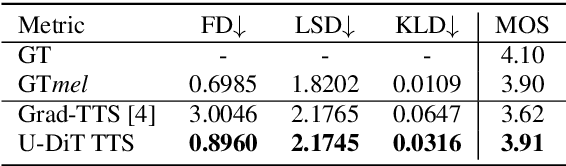
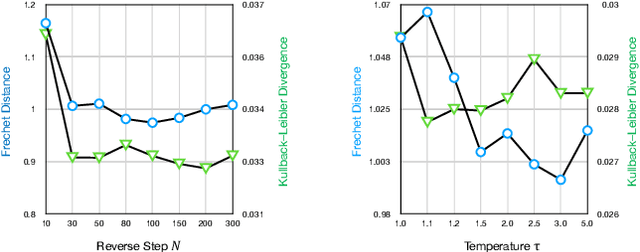
Deep learning has led to considerable advances in text-to-speech synthesis. Most recently, the adoption of Score-based Generative Models (SGMs), also known as Diffusion Probabilistic Models (DPMs), has gained traction due to their ability to produce high-quality synthesized neural speech in neural speech synthesis systems. In SGMs, the U-Net architecture and its variants have long dominated as the backbone since its first successful adoption. In this research, we mainly focus on the neural network in diffusion-model-based Text-to-Speech (TTS) systems and propose the U-DiT architecture, exploring the potential of vision transformer architecture as the core component of the diffusion models in a TTS system. The modular design of the U-DiT architecture, inherited from the best parts of U-Net and ViT, allows for great scalability and versatility across different data scales. The proposed U-DiT TTS system is a mel spectrogram-based acoustic model and utilizes a pretrained HiFi-GAN as the vocoder. The objective (ie Frechet distance) and MOS results show that our DiT-TTS system achieves state-of-art performance on the single speaker dataset LJSpeech. Our demos are publicly available at: https://eihw.github.io/u-dit-tts/
HEAR4Health: A blueprint for making computer audition a staple of modern healthcare
Jan 25, 2023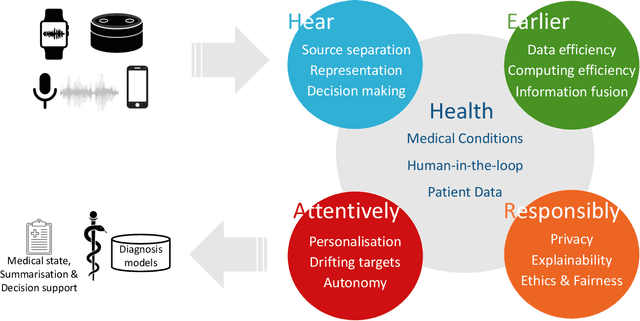

Recent years have seen a rapid increase in digital medicine research in an attempt to transform traditional healthcare systems to their modern, intelligent, and versatile equivalents that are adequately equipped to tackle contemporary challenges. This has led to a wave of applications that utilise AI technologies; first and foremost in the fields of medical imaging, but also in the use of wearables and other intelligent sensors. In comparison, computer audition can be seen to be lagging behind, at least in terms of commercial interest. Yet, audition has long been a staple assistant for medical practitioners, with the stethoscope being the quintessential sign of doctors around the world. Transforming this traditional technology with the use of AI entails a set of unique challenges. We categorise the advances needed in four key pillars: Hear, corresponding to the cornerstone technologies needed to analyse auditory signals in real-life conditions; Earlier, for the advances needed in computational and data efficiency; Attentively, for accounting to individual differences and handling the longitudinal nature of medical data; and, finally, Responsibly, for ensuring compliance to the ethical standards accorded to the field of medicine.
Redundancy Reduction Twins Network: A Training framework for Multi-output Emotion Regression
Jun 28, 2022


In this paper, we propose the Redundancy Reduction Twins Network (RRTN), a redundancy reduction training framework that minimizes redundancy by measuring the cross-correlation matrix between the outputs of the same network fed with distorted versions of a sample and bringing it as close to the identity matrix as possible. RRTN also applies a new loss function, the Barlow Twins loss function, to help maximize the similarity of representations obtained from different distorted versions of a sample. However, as the distribution of losses can cause performance fluctuations in the network, we also propose the use of a Restrained Uncertainty Weight Loss (RUWL) or joint training to identify the best weights for the loss function. Our best approach on CNN14 with the proposed methodology obtains a CCC over emotion regression of 0.678 on the ExVo Multi-task dev set, a 4.8% increase over a vanilla CNN 14 CCC of 0.647, which achieves a significant difference at the 95% confidence interval (2-tailed).
Dynamic Restrained Uncertainty Weighting Loss for Multitask Learning of Vocal Expression
Jun 27, 2022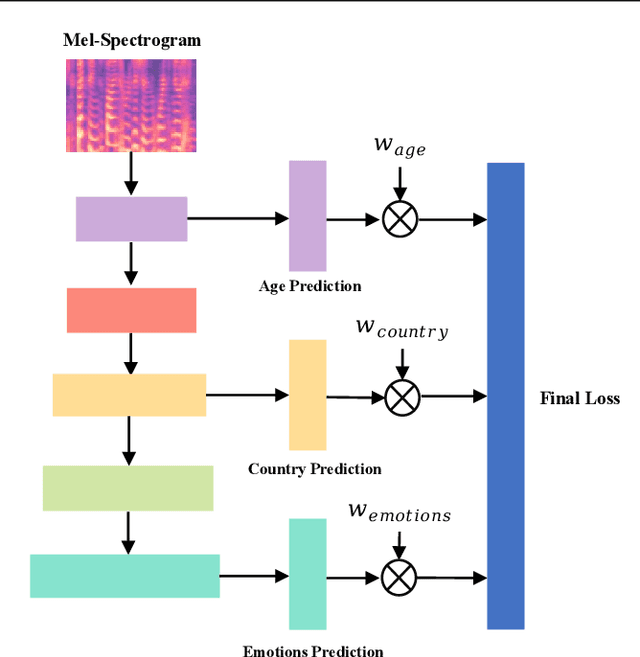
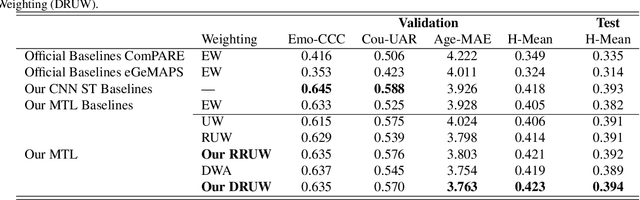
We propose a novel Dynamic Restrained Uncertainty Weighting Loss to experimentally handle the problem of balancing the contributions of multiple tasks on the ICML ExVo 2022 Challenge. The multitask aims to recognize expressed emotions and demographic traits from vocal bursts jointly. Our strategy combines the advantages of Uncertainty Weight and Dynamic Weight Average, by extending weights with a restraint term to make the learning process more explainable. We use a lightweight multi-exit CNN architecture to implement our proposed loss approach. The experimental H-Mean score (0.394) shows a substantial improvement over the baseline H-Mean score (0.335).
Exploring speaker enrolment for few-shot personalisation in emotional vocalisation prediction
Jun 20, 2022

In this work, we explore a novel few-shot personalisation architecture for emotional vocalisation prediction. The core contribution is an `enrolment' encoder which utilises two unlabelled samples of the target speaker to adjust the output of the emotion encoder; the adjustment is based on dot-product attention, thus effectively functioning as a form of `soft' feature selection. The emotion and enrolment encoders are based on two standard audio architectures: CNN14 and CNN10. The two encoders are further guided to forget or learn auxiliary emotion and/or speaker information. Our best approach achieves a CCC of $.650$ on the ExVo Few-Shot dev set, a $2.5\%$ increase over our baseline CNN14 CCC of $.634$.
A Temporal-oriented Broadcast ResNet for COVID-19 Detection
Mar 31, 2022



Detecting COVID-19 from audio signals, such as breathing and coughing, can be used as a fast and efficient pre-testing method to reduce the virus transmission. Due to the promising results of deep learning networks in modelling time sequences, and since applications to rapidly identify COVID in-the-wild should require low computational effort, we present a temporal-oriented broadcasting residual learning method that achieves efficient computation and high accuracy with a small model size. Based on the EfficientNet architecture, our novel network, named Temporal-oriented ResNet~(TorNet), constitutes of a broadcasting learning block, i.e. the Alternating Broadcast (AB) Block, which contains several Broadcast Residual Blocks (BC ResBlocks) and a convolution layer. With the AB Block, the network obtains useful audio-temporal features and higher level embeddings effectively with much less computation than Recurrent Neural Networks~(RNNs), typically used to model temporal information. TorNet achieves 72.2% Unweighted Average Recall (UAR) on the INTERPSEECH 2021 Computational Paralinguistics Challenge COVID-19 cough Sub-Challenge, by this showing competitive results with a higher computational efficiency than other state-of-the-art alternatives.
An Overview & Analysis of Sequence-to-Sequence Emotional Voice Conversion
Mar 29, 2022
Emotional voice conversion (EVC) focuses on converting a speech utterance from a source to a target emotion; it can thus be a key enabling technology for human-computer interaction applications and beyond. However, EVC remains an unsolved research problem with several challenges. In particular, as speech rate and rhythm are two key factors of emotional conversion, models have to generate output sequences of differing length. Sequence-to-sequence modelling is recently emerging as a competitive paradigm for models that can overcome those challenges. In an attempt to stimulate further research in this promising new direction, recent sequence-to-sequence EVC papers were systematically investigated and reviewed from six perspectives: their motivation, training strategies, model architectures, datasets, model inputs, and evaluation methods. This information is organised to provide the research community with an easily digestible overview of the current state-of-the-art. Finally, we discuss existing challenges of sequence-to-sequence EVC.
DXQ-Net: Differentiable LiDAR-Camera Extrinsic Calibration Using Quality-aware Flow
Mar 17, 2022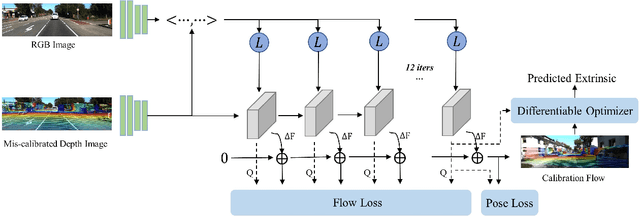

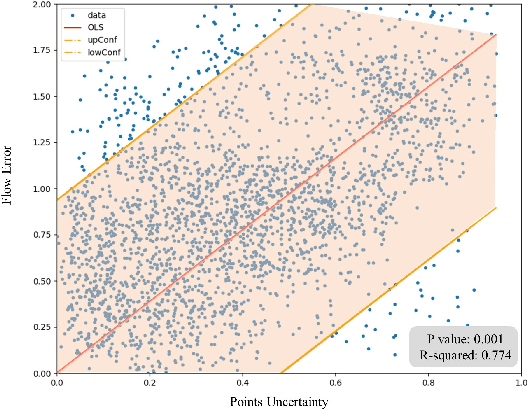

Accurate LiDAR-camera extrinsic calibration is a precondition for many multi-sensor systems in mobile robots. Most calibration methods rely on laborious manual operations and calibration targets. While working online, the calibration methods should be able to extract information from the environment to construct the cross-modal data association. Convolutional neural networks (CNNs) have powerful feature extraction ability and have been used for calibration. However, most of the past methods solve the extrinsic as a regression task, without considering the geometric constraints involved. In this paper, we propose a novel end-to-end extrinsic calibration method named DXQ-Net, using a differentiable pose estimation module for generalization. We formulate a probabilistic model for LiDAR-camera calibration flow, yielding a prediction of uncertainty to measure the quality of LiDAR-camera data association. Testing experiments illustrate that our method achieves a competitive with other methods for the translation component and state-of-the-art performance for the rotation component. Generalization experiments illustrate that the generalization performance of our method is significantly better than other deep learning-based methods.
Audio Self-supervised Learning: A Survey
Mar 02, 2022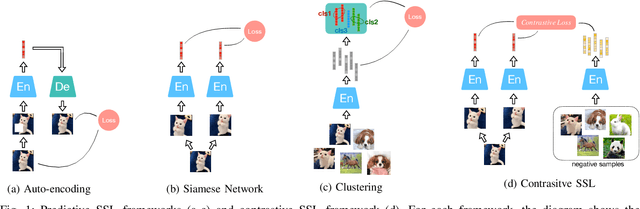
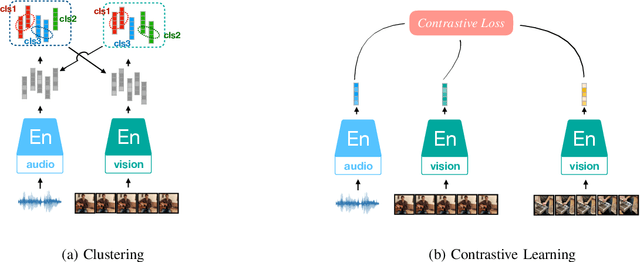
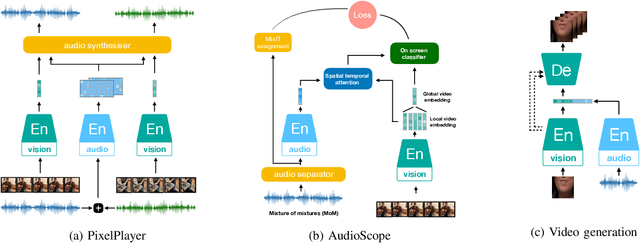
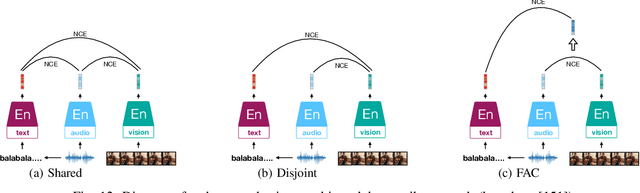
Inspired by the humans' cognitive ability to generalise knowledge and skills, Self-Supervised Learning (SSL) targets at discovering general representations from large-scale data without requiring human annotations, which is an expensive and time consuming task. Its success in the fields of computer vision and natural language processing have prompted its recent adoption into the field of audio and speech processing. Comprehensive reviews summarising the knowledge in audio SSL are currently missing. To fill this gap, in the present work, we provide an overview of the SSL methods used for audio and speech processing applications. Herein, we also summarise the empirical works that exploit the audio modality in multi-modal SSL frameworks, and the existing suitable benchmarks to evaluate the power of SSL in the computer audition domain. Finally, we discuss some open problems and point out the future directions on the development of audio SSL.