 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTanja Schultz
STAA-Net: A Sparse and Transferable Adversarial Attack for Speech Emotion Recognition
Feb 02, 2024
Speech contains rich information on the emotions of humans, and Speech Emotion Recognition (SER) has been an important topic in the area of human-computer interaction. The robustness of SER models is crucial, particularly in privacy-sensitive and reliability-demanding domains like private healthcare. Recently, the vulnerability of deep neural networks in the audio domain to adversarial attacks has become a popular area of research. However, prior works on adversarial attacks in the audio domain primarily rely on iterative gradient-based techniques, which are time-consuming and prone to overfitting the specific threat model. Furthermore, the exploration of sparse perturbations, which have the potential for better stealthiness, remains limited in the audio domain. To address these challenges, we propose a generator-based attack method to generate sparse and transferable adversarial examples to deceive SER models in an end-to-end and efficient manner. We evaluate our method on two widely-used SER datasets, Database of Elicited Mood in Speech (DEMoS) and Interactive Emotional dyadic MOtion CAPture (IEMOCAP), and demonstrate its ability to generate successful sparse adversarial examples in an efficient manner. Moreover, our generated adversarial examples exhibit model-agnostic transferability, enabling effective adversarial attacks on advanced victim models.
Uncovering the Full Potential of Visual Grounding Methods in VQA
Jan 15, 2024Visual Grounding (VG) methods in Visual Question Answering (VQA) attempt to improve VQA performance by strengthening a model's reliance on question-relevant visual information. The presence of such relevant information in the visual input is typically assumed in training and testing. This assumption, however, is inherently flawed when dealing with imperfect image representations common in large-scale VQA, where the information carried by visual features frequently deviates from expected ground-truth contents. As a result, training and testing of VG-methods is performed with largely inaccurate data, which obstructs proper assessment of their potential benefits. In this work, we demonstrate that current evaluation schemes for VG-methods are problematic due to the flawed assumption of availability of relevant visual information. Our experiments show that the potential benefits of these methods are severely underestimated as a result.
NeuroHeed: Neuro-Steered Speaker Extraction using EEG Signals
Jul 26, 2023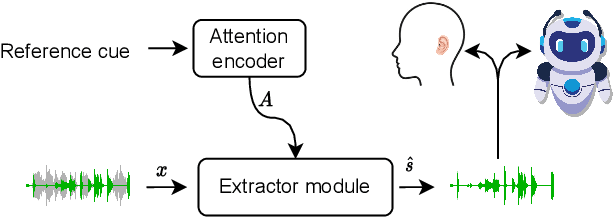
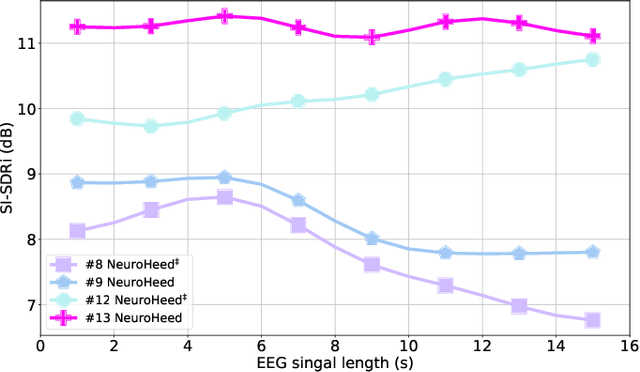
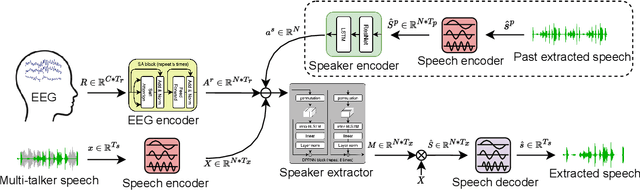
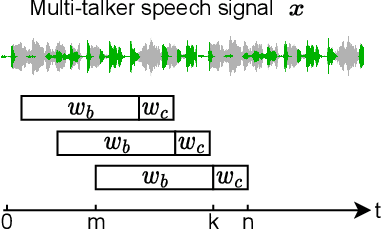
Humans possess the remarkable ability to selectively attend to a single speaker amidst competing voices and background noise, known as selective auditory attention. Recent studies in auditory neuroscience indicate a strong correlation between the attended speech signal and the corresponding brain's elicited neuronal activities, which the latter can be measured using affordable and non-intrusive electroencephalography (EEG) devices. In this study, we present NeuroHeed, a speaker extraction model that leverages EEG signals to establish a neuronal attractor which is temporally associated with the speech stimulus, facilitating the extraction of the attended speech signal in a cocktail party scenario. We propose both an offline and an online NeuroHeed, with the latter designed for real-time inference. In the online NeuroHeed, we additionally propose an autoregressive speaker encoder, which accumulates past extracted speech signals for self-enrollment of the attended speaker information into an auditory attractor, that retains the attentional momentum over time. Online NeuroHeed extracts the current window of the speech signals with guidance from both attractors. Experimental results demonstrate that NeuroHeed effectively extracts brain-attended speech signals, achieving high signal quality, excellent perceptual quality, and intelligibility in a two-speaker scenario.
Measuring Faithful and Plausible Visual Grounding in VQA
May 24, 2023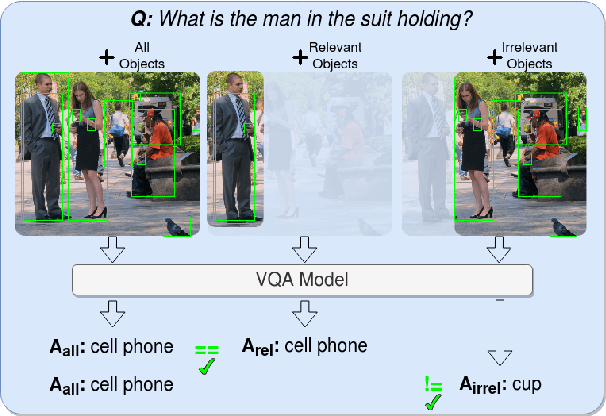

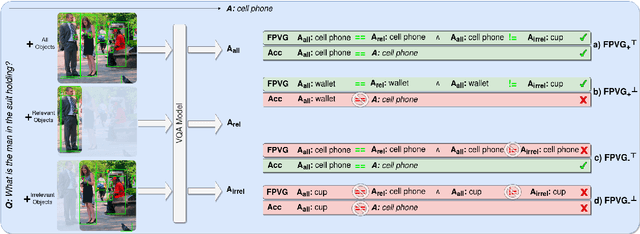
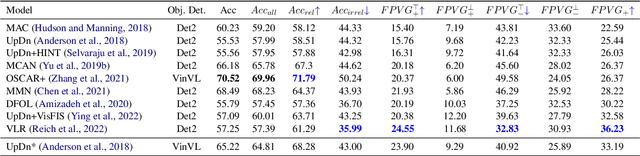
Metrics for Visual Grounding (VG) in Visual Question Answering (VQA) systems primarily aim to measure a system's reliance on relevant parts of the image when inferring an answer to the given question. Lack of VG has been a common problem among state-of-the-art VQA systems and can manifest in over-reliance on irrelevant image parts or a disregard for the visual modality entirely. Although inference capabilities of VQA models are often illustrated by a few qualitative illustrations, most systems are not quantitatively assessed for their VG properties. We believe, an easily calculated criterion for meaningfully measuring a system's VG can help remedy this shortcoming, as well as add another valuable dimension to model evaluations and analysis. To this end, we propose a new VG metric that captures if a model a) identifies question-relevant objects in the scene, and b) actually relies on the information contained in the relevant objects when producing its answer, i.e., if its visual grounding is both "faithful" and "plausible". Our metric, called "Faithful and Plausible Visual Grounding" (FPVG), is straightforward to determine for most VQA model designs. We give a detailed description of FPVG and evaluate several reference systems spanning various VQA architectures. Code to support the metric calculations on the GQA data set is available on GitHub.
Visually Grounded VQA by Lattice-based Retrieval
Nov 15, 2022
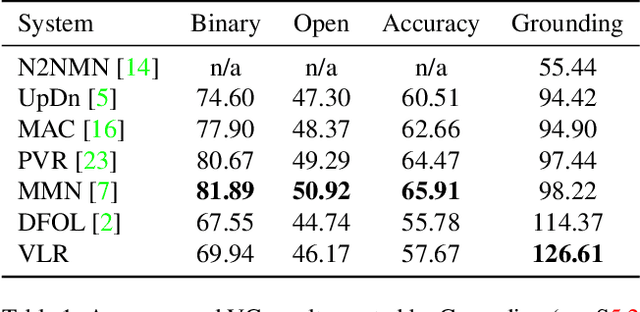


Visual Grounding (VG) in Visual Question Answering (VQA) systems describes how well a system manages to tie a question and its answer to relevant image regions. Systems with strong VG are considered intuitively interpretable and suggest an improved scene understanding. While VQA accuracy performances have seen impressive gains over the past few years, explicit improvements to VG performance and evaluation thereof have often taken a back seat on the road to overall accuracy improvements. A cause of this originates in the predominant choice of learning paradigm for VQA systems, which consists of training a discriminative classifier over a predetermined set of answer options. In this work, we break with the dominant VQA modeling paradigm of classification and investigate VQA from the standpoint of an information retrieval task. As such, the developed system directly ties VG into its core search procedure. Our system operates over a weighted, directed, acyclic graph, a.k.a. "lattice", which is derived from the scene graph of a given image in conjunction with region-referring expressions extracted from the question. We give a detailed analysis of our approach and discuss its distinctive properties and limitations. Our approach achieves the strongest VG performance among examined systems and exhibits exceptional generalization capabilities in a number of scenarios.
Adventurer's Treasure Hunt: A Transparent System for Visually Grounded Compositional Visual Question Answering based on Scene Graphs
Jun 28, 2021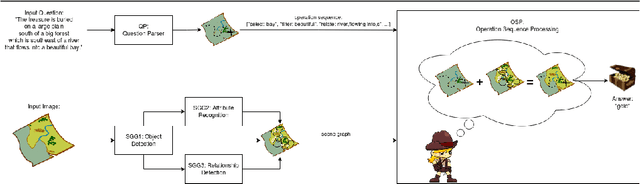
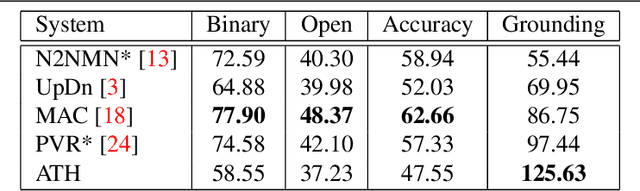
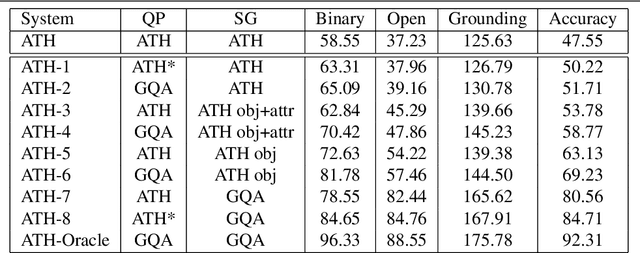
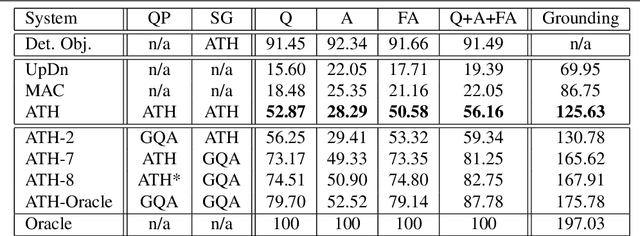
With the expressed goal of improving system transparency and visual grounding in the reasoning process in VQA, we present a modular system for the task of compositional VQA based on scene graphs. Our system is called "Adventurer's Treasure Hunt" (or ATH), named after an analogy we draw between our model's search procedure for an answer and an adventurer's search for treasure. We developed ATH with three characteristic features in mind: 1. By design, ATH allows us to explicitly quantify the impact of each of the sub-components on overall VQA performance, as well as their performance on their individual sub-task. 2. By modeling the search task after a treasure hunt, ATH inherently produces an explicit, visually grounded inference path for the processed question. 3. ATH is the first GQA-trained VQA system that dynamically extracts answers by querying the visual knowledge base directly, instead of selecting one from a specially learned classifier's output distribution over a pre-fixed answer vocabulary. We report detailed results on all components and their contributions to overall VQA performance on the GQA dataset and show that ATH achieves the highest visual grounding score among all examined systems.
Low-latency auditory spatial attention detection based on spectro-spatial features from EEG
Mar 05, 2021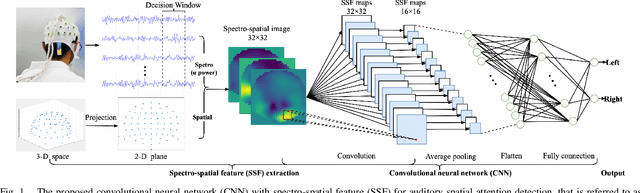

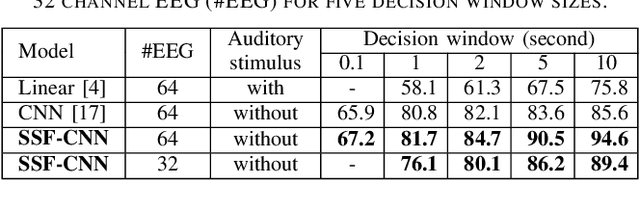
Detecting auditory attention based on brain signals enables many everyday applications, and serves as part of the solution to the cocktail party effect in speech processing. Several studies leverage the correlation between brain signals and auditory stimuli to detect the auditory attention of listeners. Recently, studies show that the alpha band (8-13 Hz) EEG signals enable the localization of auditory stimuli. We believe that it is possible to detect auditory spatial attention without the need of auditory stimuli as references. In this work, we use alpha power signals for automatic auditory spatial attention detection. To the best of our knowledge, this is the first attempt to detect spatial attention based on alpha power neural signals. We propose a spectro-spatial feature extraction technique to detect the auditory spatial attention (left/right) based on the topographic specificity of alpha power. Experiments show that the proposed neural approach achieves 81.7% and 94.6% accuracy for 1-second and 10-second decision windows, respectively. Our comparative results show that this neural approach outperforms other competitive models by a large margin in all test cases.
Syntactic and Semantic Features For Code-Switching Factored Language Models
Oct 04, 2017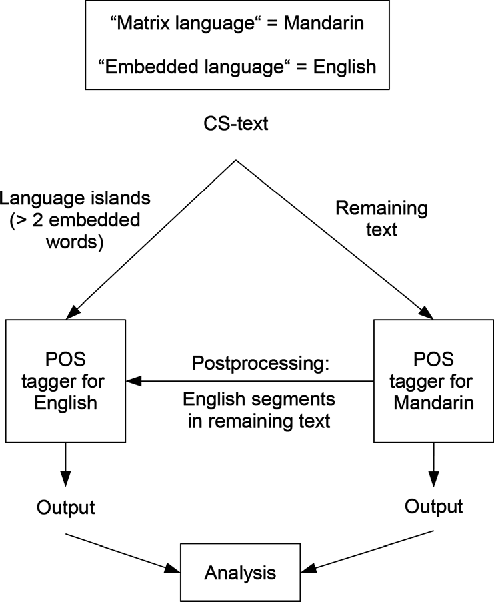
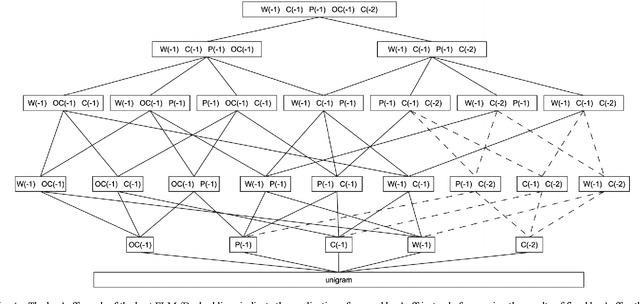
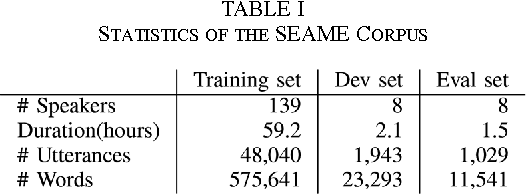
This paper presents our latest investigations on different features for factored language models for Code-Switching speech and their effect on automatic speech recognition (ASR) performance. We focus on syntactic and semantic features which can be extracted from Code-Switching text data and integrate them into factored language models. Different possible factors, such as words, part-of-speech tags, Brown word clusters, open class words and clusters of open class word embeddings are explored. The experimental results reveal that Brown word clusters, part-of-speech tags and open-class words are the most effective at reducing the perplexity of factored language models on the Mandarin-English Code-Switching corpus SEAME. In ASR experiments, the model containing Brown word clusters and part-of-speech tags and the model also including clusters of open class word embeddings yield the best mixed error rate results. In summary, the best language model can significantly reduce the perplexity on the SEAME evaluation set by up to 10.8% relative and the mixed error rate by up to 3.4% relative.