 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunjie Chen
Constituents Correspond to Word Sequence Patterns among Sentences with Equivalent Predicate-Argument Structures: Unsupervised Constituency Parsing by Span Matching
Apr 18, 2024
Unsupervised constituency parsing is about identifying word sequences that form a syntactic unit (i.e., constituents) in a target sentence. Linguists identify the constituent by evaluating a set of Predicate-Argument Structure (PAS) equivalent sentences where we find the constituent corresponds to frequent word sequences. However, such information is unavailable to previous parsing methods which identify the constituent by observing sentences with diverse PAS. In this study, we empirically verify that \textbf{constituents correspond to word sequence patterns in the PAS-equivalent sentence set}. We propose a frequency-based method \emph{span-overlap}, applying the word sequence pattern to computational unsupervised parsing for the first time. Parsing experiments show that the span-overlap parser outperforms state-of-the-art parsers in eight out of ten languages. Further discrimination analysis confirms that the span-overlap method can non-trivially separate constituents from non-constituents. This result highlights the utility of the word sequence pattern. Additionally, we discover a multilingual phenomenon: \textbf{participant-denoting constituents are more frequent than event-denoting constituents}. The phenomenon indicates a behavioral difference between the two constituent types, laying the foundation for future labeled unsupervised parsing.
Meta-Point Learning and Refining for Category-Agnostic Pose Estimation
Mar 20, 2024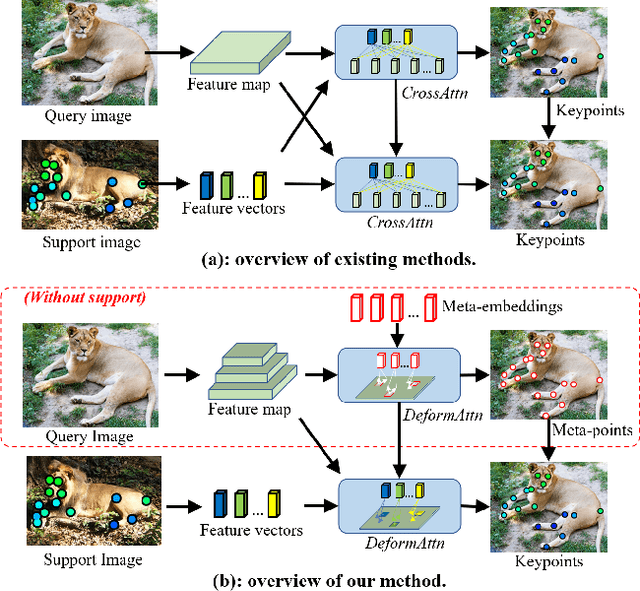
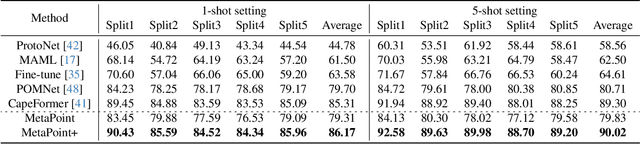
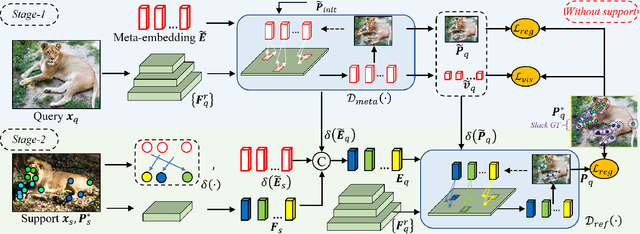
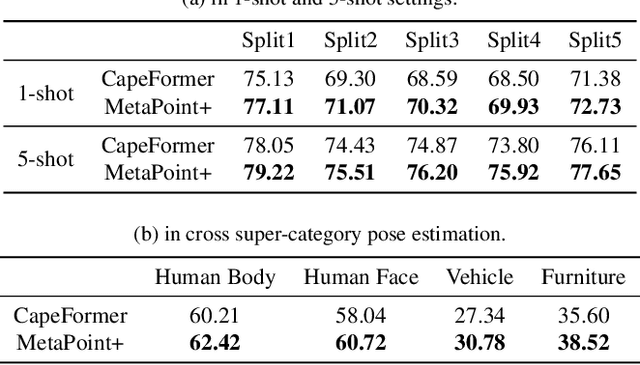
Category-agnostic pose estimation (CAPE) aims to predict keypoints for arbitrary classes given a few support images annotated with keypoints. Existing methods only rely on the features extracted at support keypoints to predict or refine the keypoints on query image, but a few support feature vectors are local and inadequate for CAPE. Considering that human can quickly perceive potential keypoints of arbitrary objects, we propose a novel framework for CAPE based on such potential keypoints (named as meta-points). Specifically, we maintain learnable embeddings to capture inherent information of various keypoints, which interact with image feature maps to produce meta-points without any support. The produced meta-points could serve as meaningful potential keypoints for CAPE. Due to the inevitable gap between inherency and annotation, we finally utilize the identities and details offered by support keypoints to assign and refine meta-points to desired keypoints in query image. In addition, we propose a progressive deformable point decoder and a slacked regression loss for better prediction and supervision. Our novel framework not only reveals the inherency of keypoints but also outperforms existing methods of CAPE. Comprehensive experiments and in-depth studies on large-scale MP-100 dataset demonstrate the effectiveness of our framework.
A Large-scale Empirical Study on Improving the Fairness of Deep Learning Models
Jan 08, 2024Fairness has been a critical issue that affects the adoption of deep learning models in real practice. To improve model fairness, many existing methods have been proposed and evaluated to be effective in their own contexts. However, there is still no systematic evaluation among them for a comprehensive comparison under the same context, which makes it hard to understand the performance distinction among them, hindering the research progress and practical adoption of them. To fill this gap, this paper endeavours to conduct the first large-scale empirical study to comprehensively compare the performance of existing state-of-the-art fairness improving techniques. Specifically, we target the widely-used application scenario of image classification, and utilized three different datasets and five commonly-used performance metrics to assess in total 13 methods from diverse categories. Our findings reveal substantial variations in the performance of each method across different datasets and sensitive attributes, indicating over-fitting on specific datasets by many existing methods. Furthermore, different fairness evaluation metrics, due to their distinct focuses, yield significantly different assessment results. Overall, we observe that pre-processing methods and in-processing methods outperform post-processing methods, with pre-processing methods exhibiting the best performance. Our empirical study offers comprehensive recommendations for enhancing fairness in deep learning models. We approach the problem from multiple dimensions, aiming to provide a uniform evaluation platform and inspire researchers to explore more effective fairness solutions via a set of implications.
Triple-View Knowledge Distillation for Semi-Supervised Semantic Segmentation
Sep 22, 2023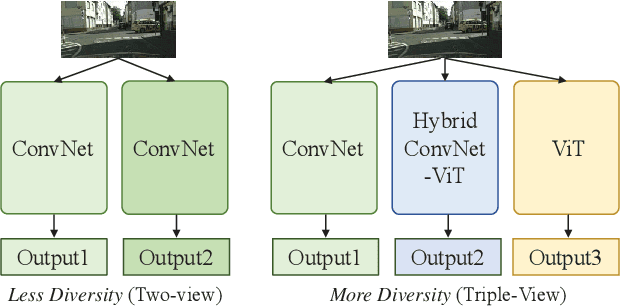
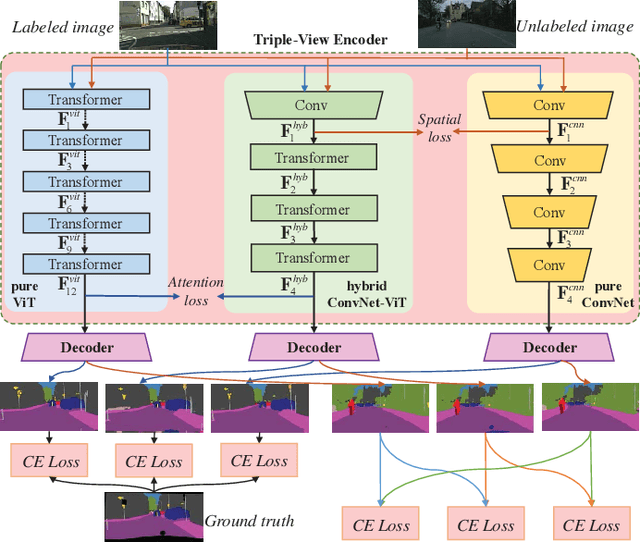
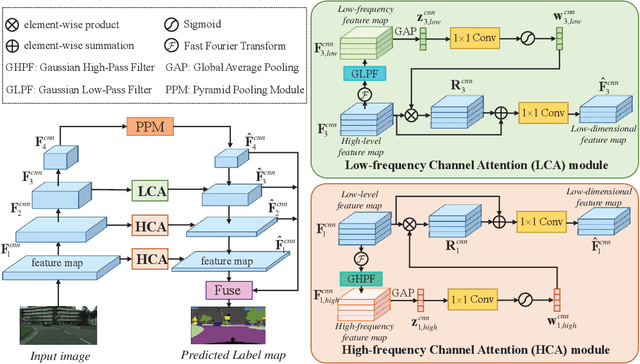

To alleviate the expensive human labeling, semi-supervised semantic segmentation employs a few labeled images and an abundant of unlabeled images to predict the pixel-level label map with the same size. Previous methods often adopt co-training using two convolutional networks with the same architecture but different initialization, which fails to capture the sufficiently diverse features. This motivates us to use tri-training and develop the triple-view encoder to utilize the encoders with different architectures to derive diverse features, and exploit the knowledge distillation skill to learn the complementary semantics among these encoders. Moreover, existing methods simply concatenate the features from both encoder and decoder, resulting in redundant features that require large memory cost. This inspires us to devise a dual-frequency decoder that selects those important features by projecting the features from the spatial domain to the frequency domain, where the dual-frequency channel attention mechanism is introduced to model the feature importance. Therefore, we propose a Triple-view Knowledge Distillation framework, termed TriKD, for semi-supervised semantic segmentation, including the triple-view encoder and the dual-frequency decoder. Extensive experiments were conducted on two benchmarks, \ie, Pascal VOC 2012 and Cityscapes, whose results verify the superiority of the proposed method with a good tradeoff between precision and inference speed.
Task Selection and Assignment for Multi-modal Multi-task Dialogue Act Classification with Non-stationary Multi-armed Bandits
Sep 18, 2023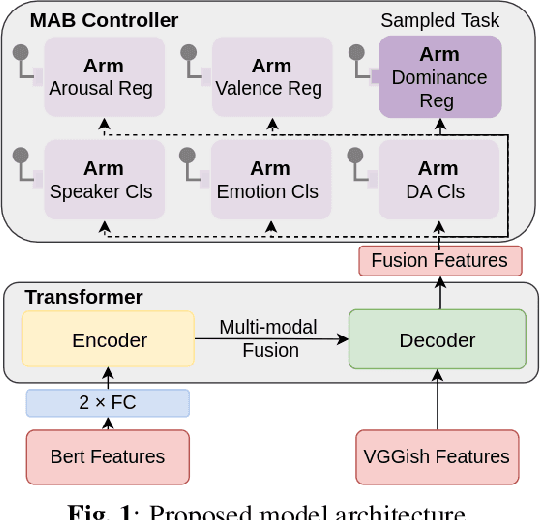
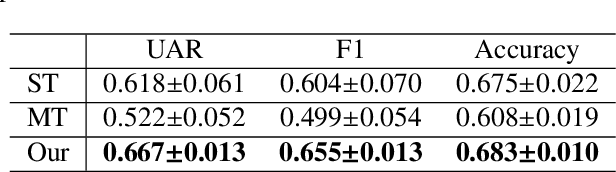

Multi-task learning (MTL) aims to improve the performance of a primary task by jointly learning with related auxiliary tasks. Traditional MTL methods select tasks randomly during training. However, both previous studies and our results suggest that such the random selection of tasks may not be helpful, and can even be harmful to performance. Therefore, new strategies for task selection and assignment in MTL need to be explored. This paper studies the multi-modal, multi-task dialogue act classification task, and proposes a method for selecting and assigning tasks based on non-stationary multi-armed bandits (MAB) with discounted Thompson Sampling (TS) using Gaussian priors. Our experimental results show that in different training stages, different tasks have different utility. Our proposed method can effectively identify the task utility, actively avoid useless or harmful tasks, and realise the task assignment during training. Our proposed method is significantly superior in terms of UAR and F1 to the single-task and multi-task baselines with p-values < 0.05. Further analysis of experiments indicates that for the dataset with the data imbalance problem, our proposed method has significantly higher stability and can obtain consistent and decent performance for minority classes. Our proposed method is superior to the current state-of-the-art model.
How to Evaluate Semantic Communications for Images with ViTScore Metric?
Sep 09, 2023


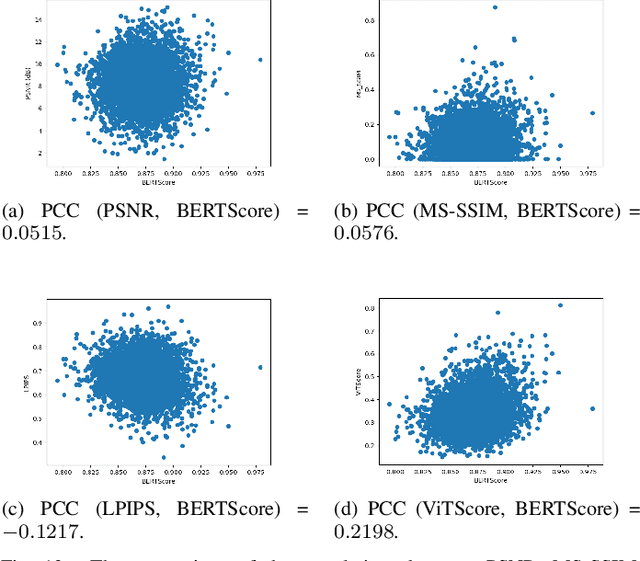
Semantic communications (SC) have been expected to be a new paradigm shifting to catalyze the next generation communication, whose main concerns shift from accurate bit transmission to effective semantic information exchange in communications. However, the previous and widely-used metrics for images are not applicable to evaluate the image semantic similarity in SC. Classical metrics to measure the similarity between two images usually rely on the pixel level or the structural level, such as the PSNR and the MS-SSIM. Straightforwardly using some tailored metrics based on deep-learning methods in CV community, such as the LPIPS, is infeasible for SC. To tackle this, inspired by BERTScore in NLP community, we propose a novel metric for evaluating image semantic similarity, named Vision Transformer Score (ViTScore). We prove theoretically that ViTScore has 3 important properties, including symmetry, boundedness, and normalization, which make ViTScore convenient and intuitive for image measurement. To evaluate the performance of ViTScore, we compare ViTScore with 3 typical metrics (PSNR, MS-SSIM, and LPIPS) through 5 classes of experiments. Experimental results demonstrate that ViTScore can better evaluate the image semantic similarity than the other 3 typical metrics, which indicates that ViTScore is an effective performance metric when deployed in SC scenarios.
Try with Simpler -- An Evaluation of Improved Principal Component Analysis in Log-based Anomaly Detection
Aug 24, 2023


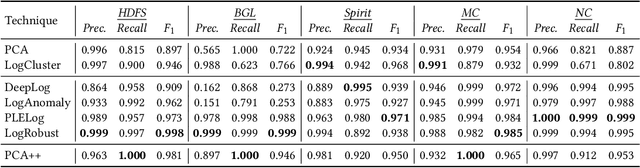
The rapid growth of deep learning (DL) has spurred interest in enhancing log-based anomaly detection. This approach aims to extract meaning from log events (log message templates) and develop advanced DL models for anomaly detection. However, these DL methods face challenges like heavy reliance on training data, labels, and computational resources due to model complexity. In contrast, traditional machine learning and data mining techniques are less data-dependent and more efficient but less effective than DL. To make log-based anomaly detection more practical, the goal is to enhance traditional techniques to match DL's effectiveness. Previous research in a different domain (linking questions on Stack Overflow) suggests that optimized traditional techniques can rival state-of-the-art DL methods. Drawing inspiration from this concept, we conducted an empirical study. We optimized the unsupervised PCA (Principal Component Analysis), a traditional technique, by incorporating lightweight semantic-based log representation. This addresses the issue of unseen log events in training data, enhancing log representation. Our study compared seven log-based anomaly detection methods, including four DL-based, two traditional, and the optimized PCA technique, using public and industrial datasets. Results indicate that the optimized unsupervised PCA technique achieves similar effectiveness to advanced supervised/semi-supervised DL methods while being more stable with limited training data and resource-efficient. This demonstrates the adaptability and strength of traditional techniques through small yet impactful adaptations.
Scene-aware Human Pose Generation using Transformer
Aug 04, 2023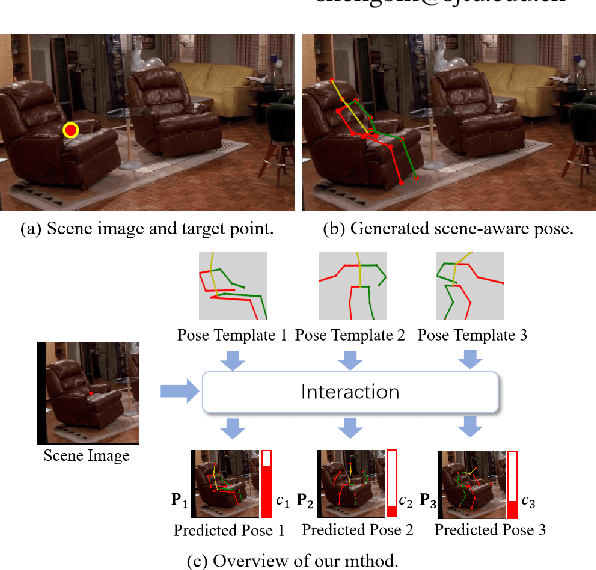
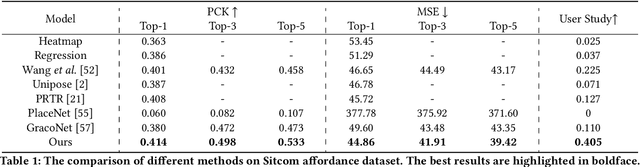

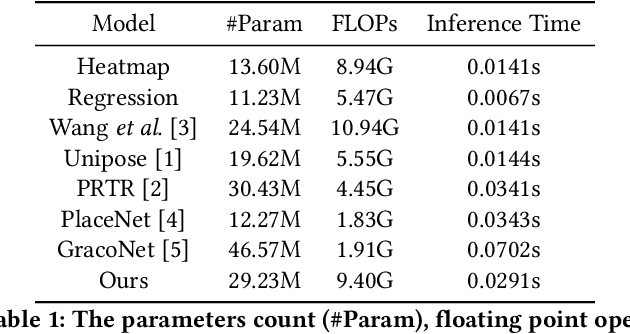
Affordance learning considers the interaction opportunities for an actor in the scene and thus has wide application in scene understanding and intelligent robotics. In this paper, we focus on contextual affordance learning, i.e., using affordance as context to generate a reasonable human pose in a scene. Existing scene-aware human pose generation methods could be divided into two categories depending on whether using pose templates. Our proposed method belongs to the template-based category, which benefits from the representative pose templates. Moreover, inspired by recent transformer-based methods, we associate each query embedding with a pose template, and use the interaction between query embeddings and scene feature map to effectively predict the scale and offsets for each pose template. In addition, we employ knowledge distillation to facilitate the offset learning given the predicted scale. Comprehensive experiments on Sitcom dataset demonstrate the effectiveness of our method.
Residual Spatial Fusion Network for RGB-Thermal Semantic Segmentation
Jun 17, 2023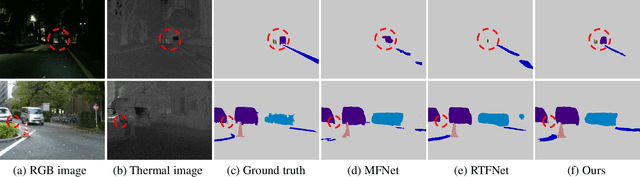
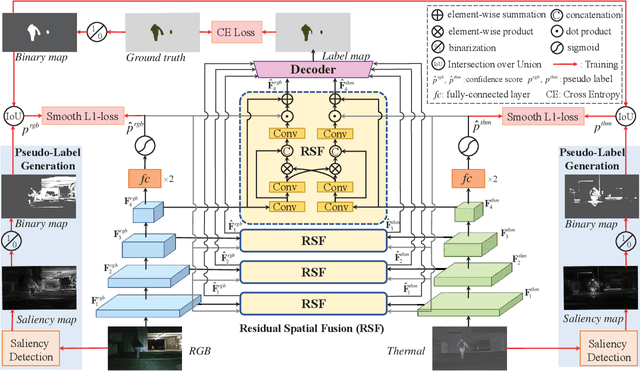
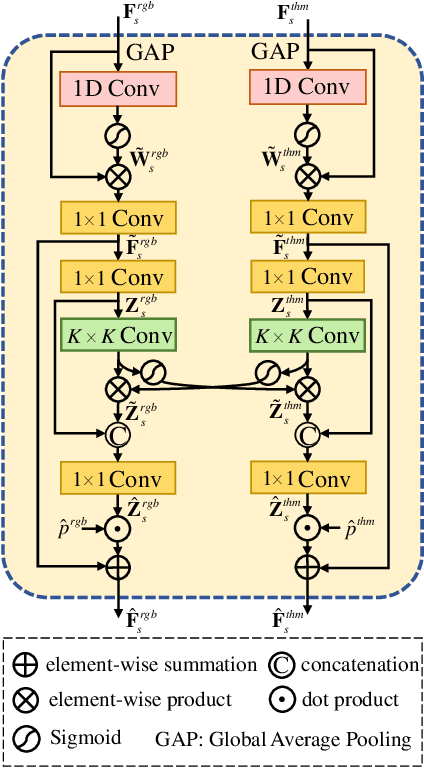
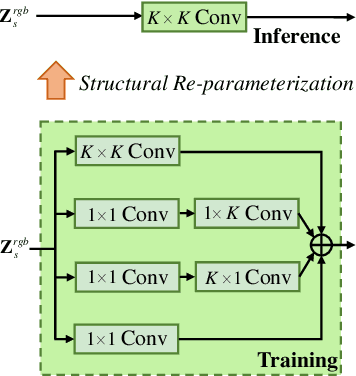
Semantic segmentation plays an important role in widespread applications such as autonomous driving and robotic sensing. Traditional methods mostly use RGB images which are heavily affected by lighting conditions, \eg, darkness. Recent studies show thermal images are robust to the night scenario as a compensating modality for segmentation. However, existing works either simply fuse RGB-Thermal (RGB-T) images or adopt the encoder with the same structure for both the RGB stream and the thermal stream, which neglects the modality difference in segmentation under varying lighting conditions. Therefore, this work proposes a Residual Spatial Fusion Network (RSFNet) for RGB-T semantic segmentation. Specifically, we employ an asymmetric encoder to learn the compensating features of the RGB and the thermal images. To effectively fuse the dual-modality features, we generate the pseudo-labels by saliency detection to supervise the feature learning, and develop the Residual Spatial Fusion (RSF) module with structural re-parameterization to learn more promising features by spatially fusing the cross-modality features. RSF employs a hierarchical feature fusion to aggregate multi-level features, and applies the spatial weights with the residual connection to adaptively control the multi-spectral feature fusion by the confidence gate. Extensive experiments were carried out on two benchmarks, \ie, MFNet database and PST900 database. The results have shown the state-of-the-art segmentation performance of our method, which achieves a good balance between accuracy and speed.
Generic and Robust Root Cause Localization for Multi-Dimensional Data in Online Service Systems
May 05, 2023
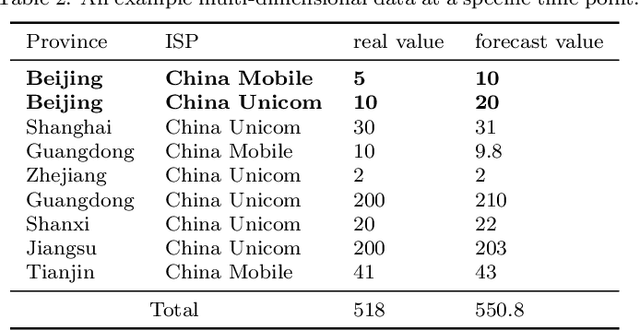

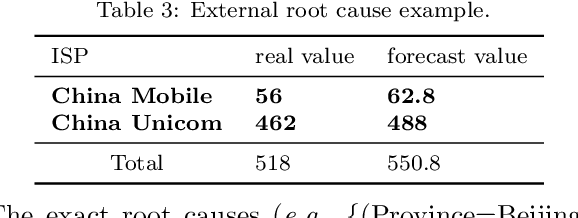
Localizing root causes for multi-dimensional data is critical to ensure online service systems' reliability. When a fault occurs, only the measure values within specific attribute combinations are abnormal. Such attribute combinations are substantial clues to the underlying root causes and thus are called root causes of multidimensional data. This paper proposes a generic and robust root cause localization approach for multi-dimensional data, PSqueeze. We propose a generic property of root cause for multi-dimensional data, generalized ripple effect (GRE). Based on it, we propose a novel probabilistic cluster method and a robust heuristic search method. Moreover, we identify the importance of determining external root causes and propose an effective method for the first time in literature. Our experiments on two real-world datasets with 5400 faults show that the F1-score of PSqueeze outperforms baselines by 32.89%, while the localization time is around 10 seconds across all cases. The F1-score in determining external root causes of PSqueeze achieves 0.90. Furthermore, case studies in several production systems demonstrate that PSqueeze is helpful to fault diagnosis in the real world.