 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanushka Bollegala
Improving Diversity of Commonsense Generation by Large Language Models via In-Context Learning
Apr 25, 2024
Generative Commonsense Reasoning (GCR) requires a model to reason about a situation using commonsense knowledge, while generating coherent sentences. Although the quality of the generated sentences is crucial, the diversity of the generation is equally important because it reflects the model's ability to use a range of commonsense knowledge facts. Large Language Models (LLMs) have shown proficiency in enhancing the generation quality across various tasks through in-context learning (ICL) using given examples without the need for any fine-tuning. However, the diversity aspect in LLM outputs has not been systematically studied before. To address this, we propose a simple method that diversifies the LLM generations, while preserving their quality. Experimental results on three benchmark GCR datasets show that our method achieves an ideal balance between the quality and diversity. Moreover, the sentences generated by our proposed method can be used as training data to improve diversity in existing commonsense generators.
Constituents Correspond to Word Sequence Patterns among Sentences with Equivalent Predicate-Argument Structures: Unsupervised Constituency Parsing by Span Matching
Apr 18, 2024Unsupervised constituency parsing is about identifying word sequences that form a syntactic unit (i.e., constituents) in a target sentence. Linguists identify the constituent by evaluating a set of Predicate-Argument Structure (PAS) equivalent sentences where we find the constituent corresponds to frequent word sequences. However, such information is unavailable to previous parsing methods which identify the constituent by observing sentences with diverse PAS. In this study, we empirically verify that \textbf{constituents correspond to word sequence patterns in the PAS-equivalent sentence set}. We propose a frequency-based method \emph{span-overlap}, applying the word sequence pattern to computational unsupervised parsing for the first time. Parsing experiments show that the span-overlap parser outperforms state-of-the-art parsers in eight out of ten languages. Further discrimination analysis confirms that the span-overlap method can non-trivially separate constituents from non-constituents. This result highlights the utility of the word sequence pattern. Additionally, we discover a multilingual phenomenon: \textbf{participant-denoting constituents are more frequent than event-denoting constituents}. The phenomenon indicates a behavioral difference between the two constituent types, laying the foundation for future labeled unsupervised parsing.
Improving Pre-trained Language Model Sensitivity via Mask Specific losses: A case study on Biomedical NER
Mar 28, 2024


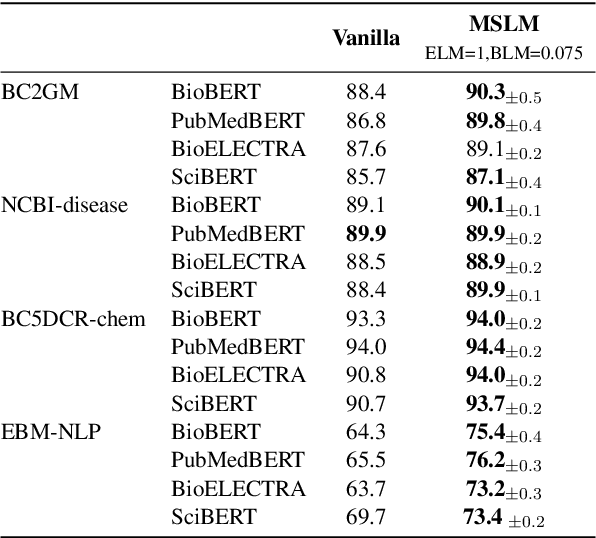
Adapting language models (LMs) to novel domains is often achieved through fine-tuning a pre-trained LM (PLM) on domain-specific data. Fine-tuning introduces new knowledge into an LM, enabling it to comprehend and efficiently perform a target domain task. Fine-tuning can however be inadvertently insensitive if it ignores the wide array of disparities (e.g in word meaning) between source and target domains. For instance, words such as chronic and pressure may be treated lightly in social conversations, however, clinically, these words are usually an expression of concern. To address insensitive fine-tuning, we propose Mask Specific Language Modeling (MSLM), an approach that efficiently acquires target domain knowledge by appropriately weighting the importance of domain-specific terms (DS-terms) during fine-tuning. MSLM jointly masks DS-terms and generic words, then learns mask-specific losses by ensuring LMs incur larger penalties for inaccurately predicting DS-terms compared to generic words. Results of our analysis show that MSLM improves LMs sensitivity and detection of DS-terms. We empirically show that an optimal masking rate not only depends on the LM, but also on the dataset and the length of sequences. Our proposed masking strategy outperforms advanced masking strategies such as span- and PMI-based masking.
Evaluating Unsupervised Dimensionality Reduction Methods for Pretrained Sentence Embeddings
Mar 20, 2024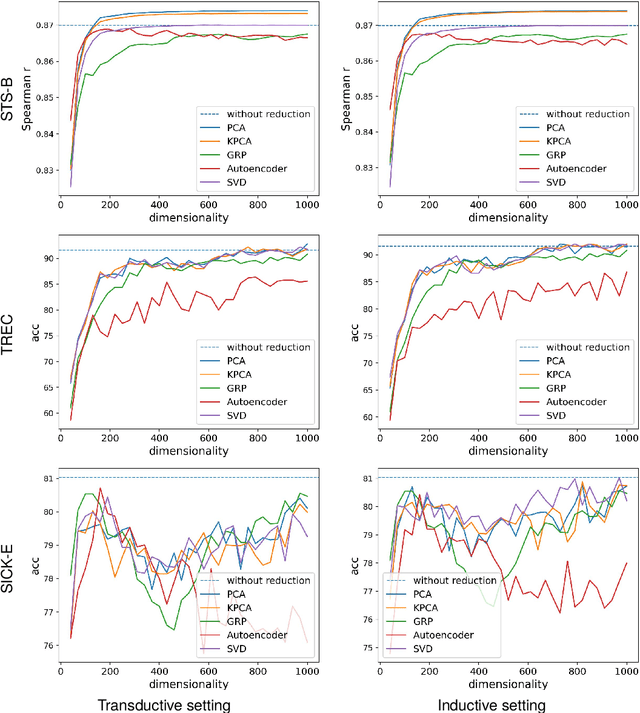
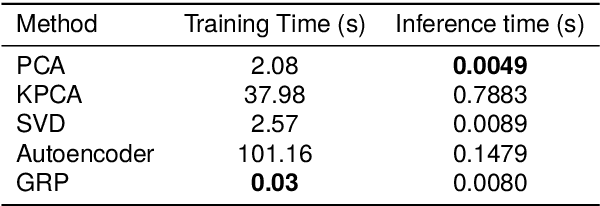
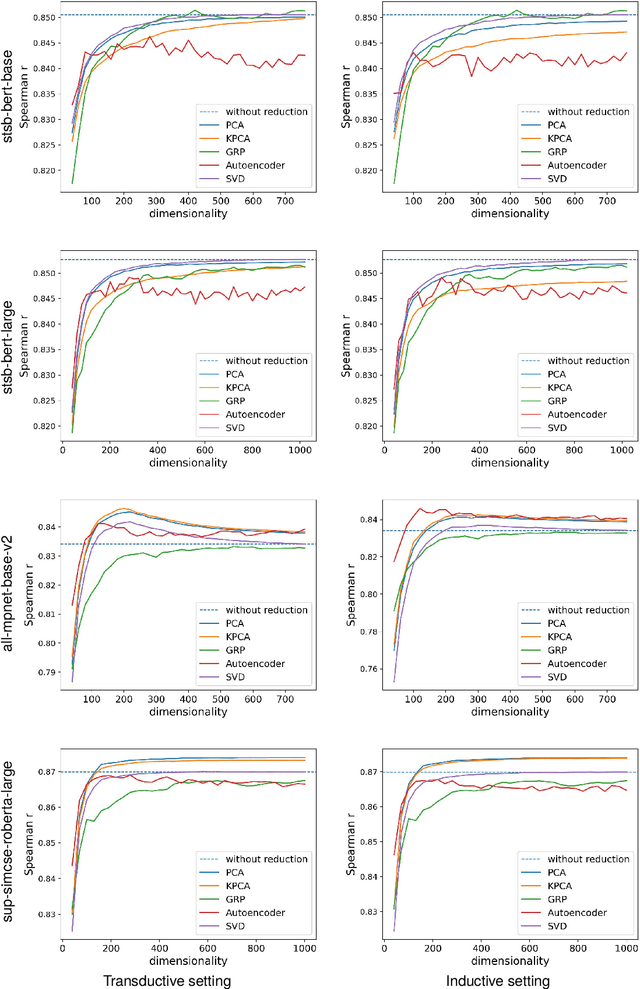
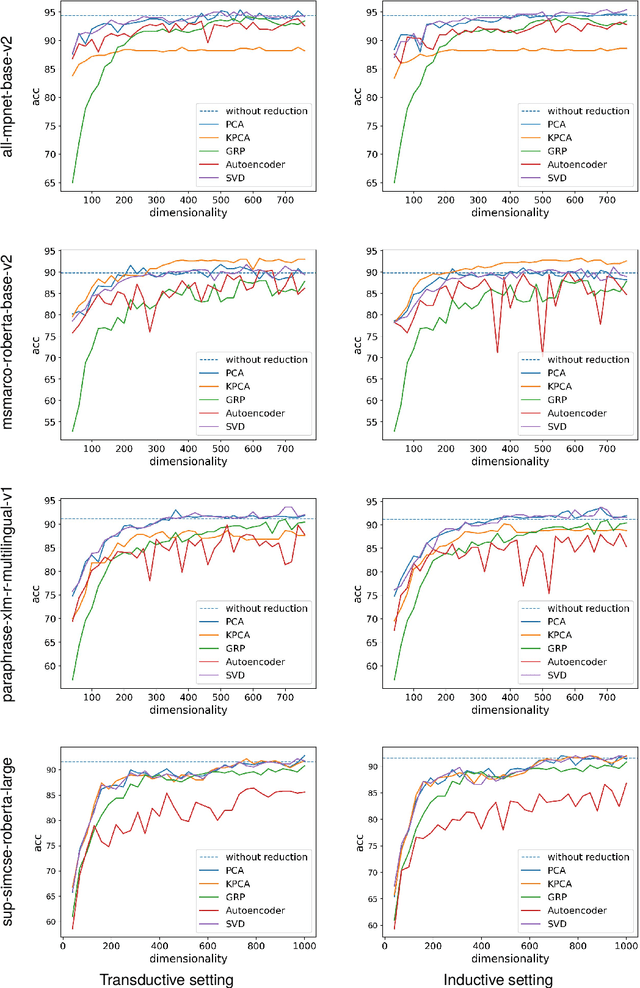
Sentence embeddings produced by Pretrained Language Models (PLMs) have received wide attention from the NLP community due to their superior performance when representing texts in numerous downstream applications. However, the high dimensionality of the sentence embeddings produced by PLMs is problematic when representing large numbers of sentences in memory- or compute-constrained devices. As a solution, we evaluate unsupervised dimensionality reduction methods to reduce the dimensionality of sentence embeddings produced by PLMs. Our experimental results show that simple methods such as Principal Component Analysis (PCA) can reduce the dimensionality of sentence embeddings by almost $50\%$, without incurring a significant loss in performance in multiple downstream tasks. Surprisingly, reducing the dimensionality further improves performance over the original high-dimensional versions for the sentence embeddings produced by some PLMs in some tasks.
A Semantic Distance Metric Learning approach for Lexical Semantic Change Detection
Mar 01, 2024
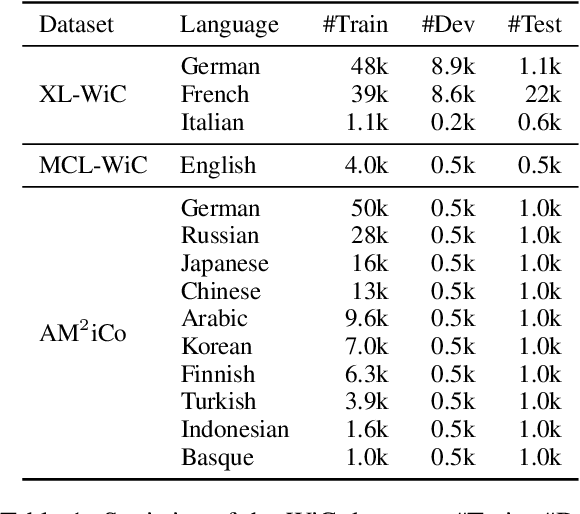
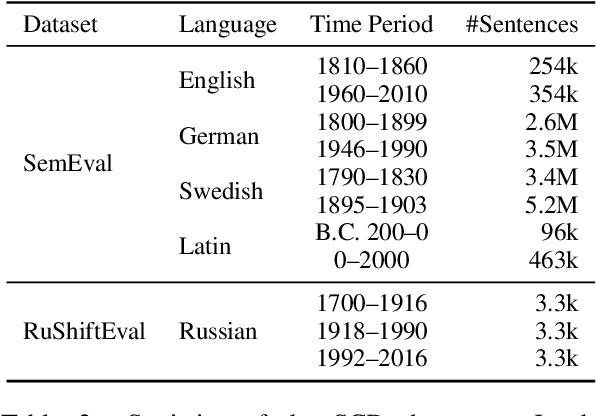
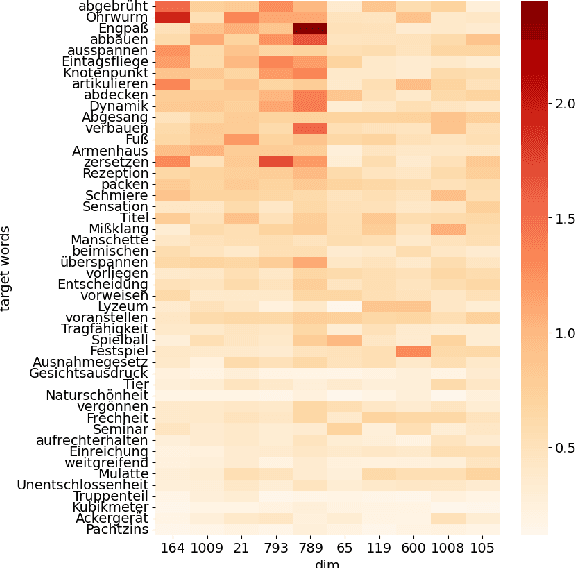
Detecting temporal semantic changes of words is an important task for various NLP applications that must make time-sensitive predictions. Lexical Semantic Change Detection (SCD) task considers the problem of predicting whether a given target word, $w$, changes its meaning between two different text corpora, $C_1$ and $C_2$. For this purpose, we propose a supervised two-staged SCD method that uses existing Word-in-Context (WiC) datasets. In the first stage, for a target word $w$, we learn two sense-aware encoder that represents the meaning of $w$ in a given sentence selected from a corpus. Next, in the second stage, we learn a sense-aware distance metric that compares the semantic representations of a target word across all of its occurrences in $C_1$ and $C_2$. Experimental results on multiple benchmark datasets for SCD show that our proposed method consistently outperforms all previously proposed SCD methods for multiple languages, establishing a novel state-of-the-art for SCD. Interestingly, our findings imply that there are specialised dimensions that carry information related to semantic changes of words in the sense-aware embedding space. Source code is available at https://github.com/a1da4/svp-sdml .
Eagle: Ethical Dataset Given from Real Interactions
Feb 22, 2024Recent studies have demonstrated that large language models (LLMs) have ethical-related problems such as social biases, lack of moral reasoning, and generation of offensive content. The existing evaluation metrics and methods to address these ethical challenges use datasets intentionally created by instructing humans to create instances including ethical problems. Therefore, the data does not reflect prompts that users actually provide when utilizing LLM services in everyday contexts. This may not lead to the development of safe LLMs that can address ethical challenges arising in real-world applications. In this paper, we create Eagle datasets extracted from real interactions between ChatGPT and users that exhibit social biases, toxicity, and immoral problems. Our experiments show that Eagle captures complementary aspects, not covered by existing datasets proposed for evaluation and mitigation of such ethical challenges. Our code is publicly available at https://huggingface.co/datasets/MasahiroKaneko/eagle.
Evaluating Gender Bias in Large Language Models via Chain-of-Thought Prompting
Jan 28, 2024There exist both scalable tasks, like reading comprehension and fact-checking, where model performance improves with model size, and unscalable tasks, like arithmetic reasoning and symbolic reasoning, where model performance does not necessarily improve with model size. Large language models (LLMs) equipped with Chain-of-Thought (CoT) prompting are able to make accurate incremental predictions even on unscalable tasks. Unfortunately, despite their exceptional reasoning abilities, LLMs tend to internalize and reproduce discriminatory societal biases. Whether CoT can provide discriminatory or egalitarian rationalizations for the implicit information in unscalable tasks remains an open question. In this study, we examine the impact of LLMs' step-by-step predictions on gender bias in unscalable tasks. For this purpose, we construct a benchmark for an unscalable task where the LLM is given a list of words comprising feminine, masculine, and gendered occupational words, and is required to count the number of feminine and masculine words. In our CoT prompts, we require the LLM to explicitly indicate whether each word in the word list is a feminine or masculine before making the final predictions. With counting and handling the meaning of words, this benchmark has characteristics of both arithmetic reasoning and symbolic reasoning. Experimental results in English show that without step-by-step prediction, most LLMs make socially biased predictions, despite the task being as simple as counting words. Interestingly, CoT prompting reduces this unconscious social bias in LLMs and encourages fair predictions.
The Gaps between Pre-train and Downstream Settings in Bias Evaluation and Debiasing
Jan 16, 2024The output tendencies of Pre-trained Language Models (PLM) vary markedly before and after Fine-Tuning (FT) due to the updates to the model parameters. These divergences in output tendencies result in a gap in the social biases of PLMs. For example, there exits a low correlation between intrinsic bias scores of a PLM and its extrinsic bias scores under FT-based debiasing methods. Additionally, applying FT-based debiasing methods to a PLM leads to a decline in performance in downstream tasks. On the other hand, PLMs trained on large datasets can learn without parameter updates via In-Context Learning (ICL) using prompts. ICL induces smaller changes to PLMs compared to FT-based debiasing methods. Therefore, we hypothesize that the gap observed in pre-trained and FT models does not hold true for debiasing methods that use ICL. In this study, we demonstrate that ICL-based debiasing methods show a higher correlation between intrinsic and extrinsic bias scores compared to FT-based methods. Moreover, the performance degradation due to debiasing is also lower in the ICL case compared to that in the FT case.
A Predictive Factor Analysis of Social Biases and Task-Performance in Pretrained Masked Language Models
Oct 22, 2023Various types of social biases have been reported with pretrained Masked Language Models (MLMs) in prior work. However, multiple underlying factors are associated with an MLM such as its model size, size of the training data, training objectives, the domain from which pretraining data is sampled, tokenization, and languages present in the pretrained corpora, to name a few. It remains unclear as to which of those factors influence social biases that are learned by MLMs. To study the relationship between model factors and the social biases learned by an MLM, as well as the downstream task performance of the model, we conduct a comprehensive study over 39 pretrained MLMs covering different model sizes, training objectives, tokenization methods, training data domains and languages. Our results shed light on important factors often neglected in prior literature, such as tokenization or model objectives.
$\textit{Swap and Predict}$ -- Predicting the Semantic Changes in Words across Corpora by Context Swapping
Oct 16, 2023Meanings of words change over time and across domains. Detecting the semantic changes of words is an important task for various NLP applications that must make time-sensitive predictions. We consider the problem of predicting whether a given target word, $w$, changes its meaning between two different text corpora, $\mathcal{C}_1$ and $\mathcal{C}_2$. For this purpose, we propose $\textit{Swapping-based Semantic Change Detection}$ (SSCD), an unsupervised method that randomly swaps contexts between $\mathcal{C}_1$ and $\mathcal{C}_2$ where $w$ occurs. We then look at the distribution of contextualised word embeddings of $w$, obtained from a pretrained masked language model (MLM), representing the meaning of $w$ in its occurrence contexts in $\mathcal{C}_1$ and $\mathcal{C}_2$. Intuitively, if the meaning of $w$ does not change between $\mathcal{C}_1$ and $\mathcal{C}_2$, we would expect the distributions of contextualised word embeddings of $w$ to remain the same before and after this random swapping process. Despite its simplicity, we demonstrate that even by using pretrained MLMs without any fine-tuning, our proposed context swapping method accurately predicts the semantic changes of words in four languages (English, German, Swedish, and Latin) and across different time spans (over 50 years and about five years). Moreover, our method achieves significant performance improvements compared to strong baselines for the English semantic change prediction task. Source code is available at https://github.com/a1da4/svp-swap .