 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJose Camacho-Collados
Language Models for Text Classification: Is In-Context Learning Enough?
Mar 26, 2024


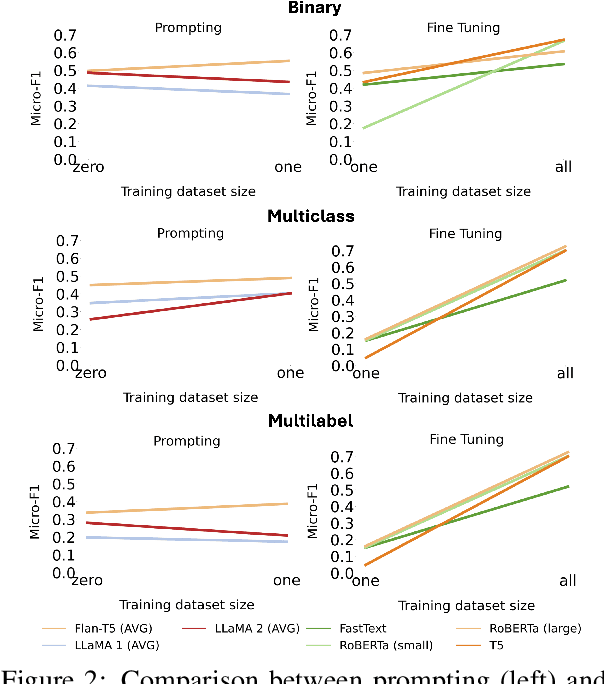
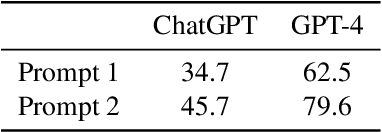
Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
Construction Artifacts in Metaphor Identification Datasets
Nov 15, 2023Metaphor identification aims at understanding whether a given expression is used figuratively in context. However, in this paper we show how existing metaphor identification datasets can be gamed by fully ignoring the potential metaphorical expression or the context in which it occurs. We test this hypothesis in a variety of datasets and settings, and show that metaphor identification systems based on language models without complete information can be competitive with those using the full context. This is due to the construction procedures to build such datasets, which introduce unwanted biases for positive and negative classes. Finally, we test the same hypothesis on datasets that are carefully sampled from natural corpora and where this bias is not present, making these datasets more challenging and reliable.
SuperTweetEval: A Challenging, Unified and Heterogeneous Benchmark for Social Media NLP Research
Oct 23, 2023Despite its relevance, the maturity of NLP for social media pales in comparison with general-purpose models, metrics and benchmarks. This fragmented landscape makes it hard for the community to know, for instance, given a task, which is the best performing model and how it compares with others. To alleviate this issue, we introduce a unified benchmark for NLP evaluation in social media, SuperTweetEval, which includes a heterogeneous set of tasks and datasets combined, adapted and constructed from scratch. We benchmarked the performance of a wide range of models on SuperTweetEval and our results suggest that, despite the recent advances in language modelling, social media remains challenging.
A Predictive Factor Analysis of Social Biases and Task-Performance in Pretrained Masked Language Models
Oct 22, 2023Various types of social biases have been reported with pretrained Masked Language Models (MLMs) in prior work. However, multiple underlying factors are associated with an MLM such as its model size, size of the training data, training objectives, the domain from which pretraining data is sampled, tokenization, and languages present in the pretrained corpora, to name a few. It remains unclear as to which of those factors influence social biases that are learned by MLMs. To study the relationship between model factors and the social biases learned by an MLM, as well as the downstream task performance of the model, we conduct a comprehensive study over 39 pretrained MLMs covering different model sizes, training objectives, tokenization methods, training data domains and languages. Our results shed light on important factors often neglected in prior literature, such as tokenization or model objectives.
RelBERT: Embedding Relations with Language Models
Oct 08, 2023
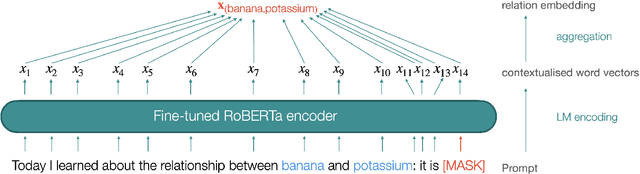
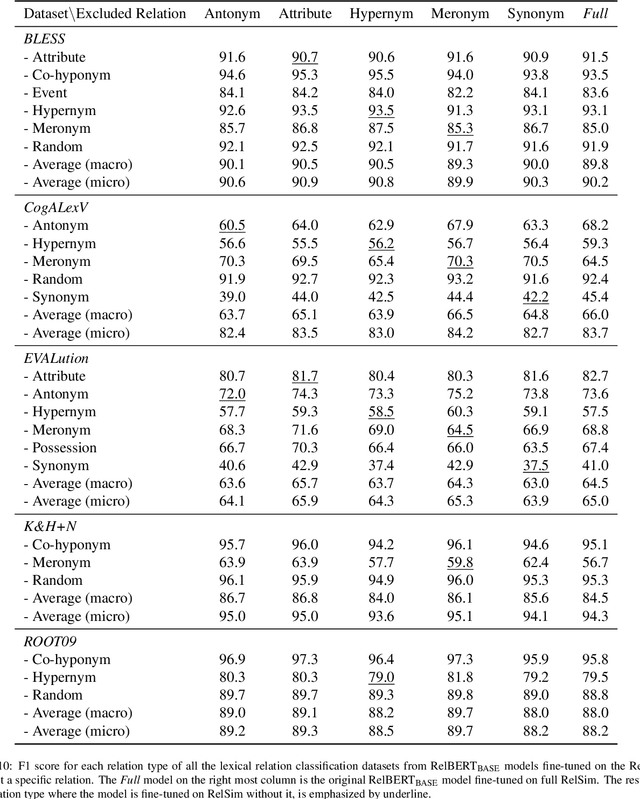
Many applications need access to background knowledge about how different concepts and entities are related. Although Knowledge Graphs (KG) and Large Language Models (LLM) can address this need to some extent, KGs are inevitably incomplete and their relational schema is often too coarse-grained, while LLMs are inefficient and difficult to control. As an alternative, we propose to extract relation embeddings from relatively small language models. In particular, we show that masked language models such as RoBERTa can be straightforwardly fine-tuned for this purpose, using only a small amount of training data. The resulting model, which we call RelBERT, captures relational similarity in a surprisingly fine-grained way, allowing us to set a new state-of-the-art in analogy benchmarks. Crucially, RelBERT is capable of modelling relations that go well beyond what the model has seen during training. For instance, we obtained strong results on relations between named entities with a model that was only trained on lexical relations between concepts, and we observed that RelBERT can recognise morphological analogies despite not being trained on such examples. Overall, we find that RelBERT significantly outperforms strategies based on prompting language models that are several orders of magnitude larger, including recent GPT-based models and open source models.
Tweet Insights: A Visualization Platform to Extract Temporal Insights from Twitter
Aug 04, 2023
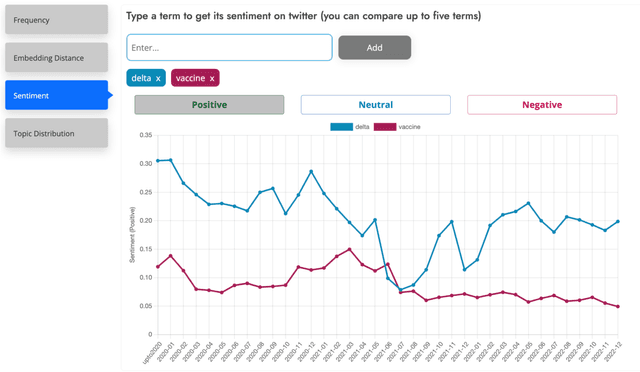
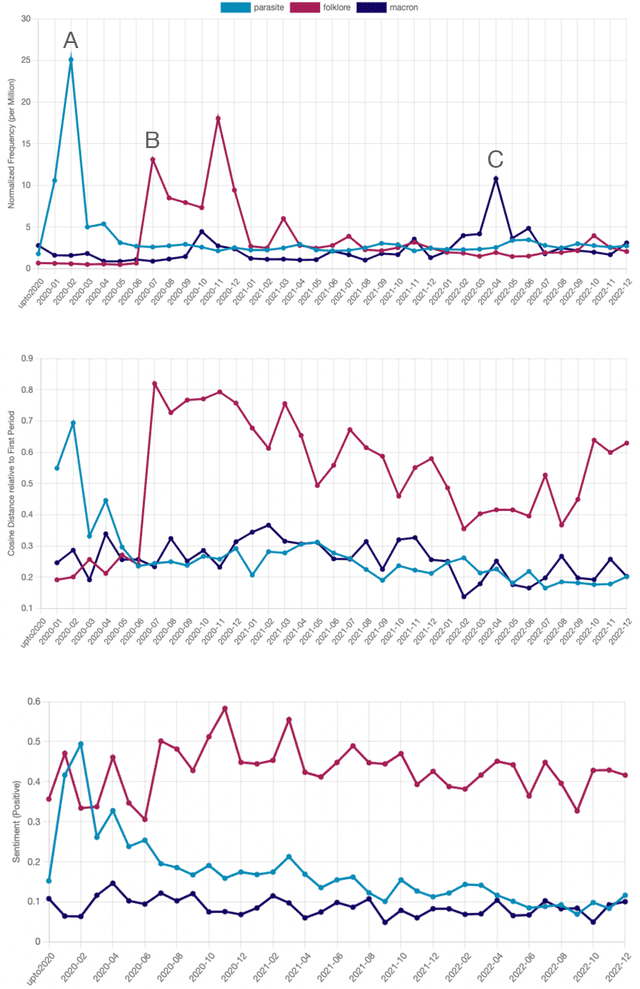

This paper introduces a large collection of time series data derived from Twitter, postprocessed using word embedding techniques, as well as specialized fine-tuned language models. This data comprises the past five years and captures changes in n-gram frequency, similarity, sentiment and topic distribution. The interface built on top of this data enables temporal analysis for detecting and characterizing shifts in meaning, including complementary information to trending metrics, such as sentiment and topic association over time. We release an online demo for easy experimentation, and we share code and the underlying aggregated data for future work. In this paper, we also discuss three case studies unlocked thanks to our platform, showcasing its potential for temporal linguistic analysis.
Robust Hate Speech Detection in Social Media: A Cross-Dataset Empirical Evaluation
Jul 04, 2023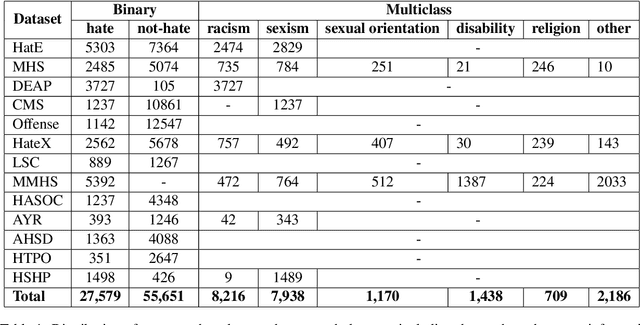
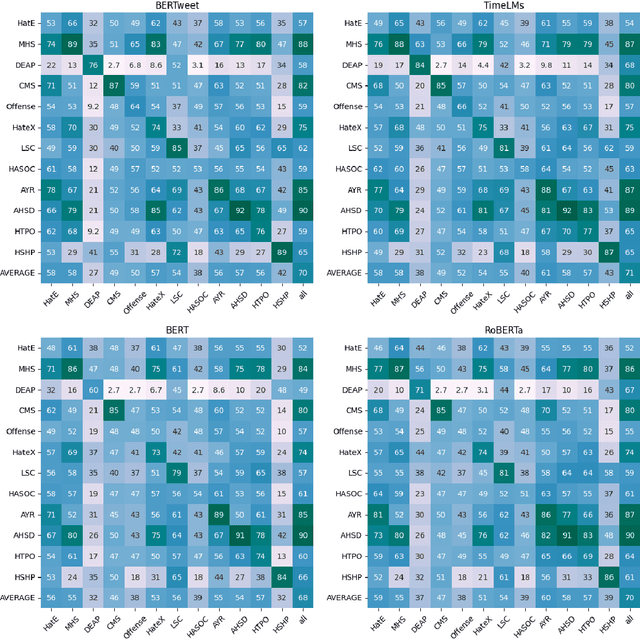
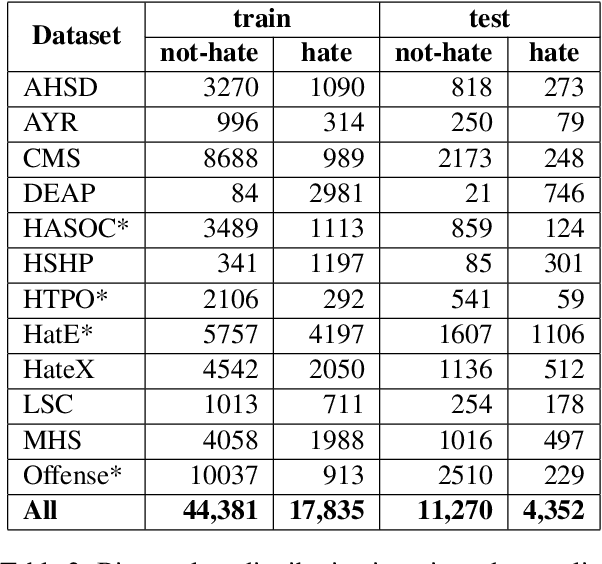
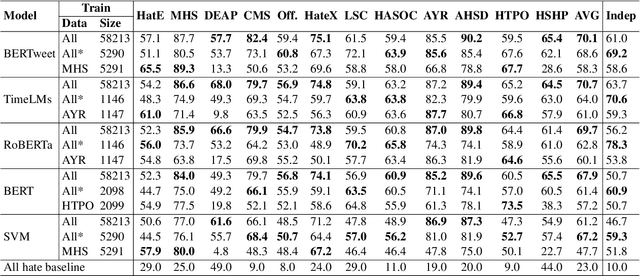
The automatic detection of hate speech online is an active research area in NLP. Most of the studies to date are based on social media datasets that contribute to the creation of hate speech detection models trained on them. However, data creation processes contain their own biases, and models inherently learn from these dataset-specific biases. In this paper, we perform a large-scale cross-dataset comparison where we fine-tune language models on different hate speech detection datasets. This analysis shows how some datasets are more generalisable than others when used as training data. Crucially, our experiments show how combining hate speech detection datasets can contribute to the development of robust hate speech detection models. This robustness holds even when controlling by data size and compared with the best individual datasets.
A Practical Toolkit for Multilingual Question and Answer Generation
May 27, 2023
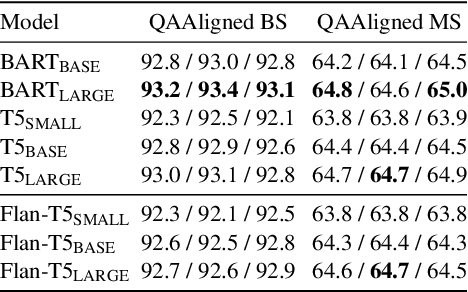
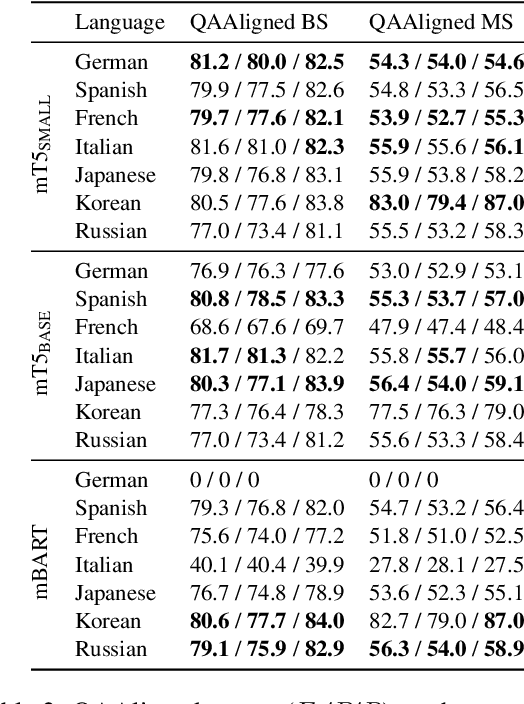
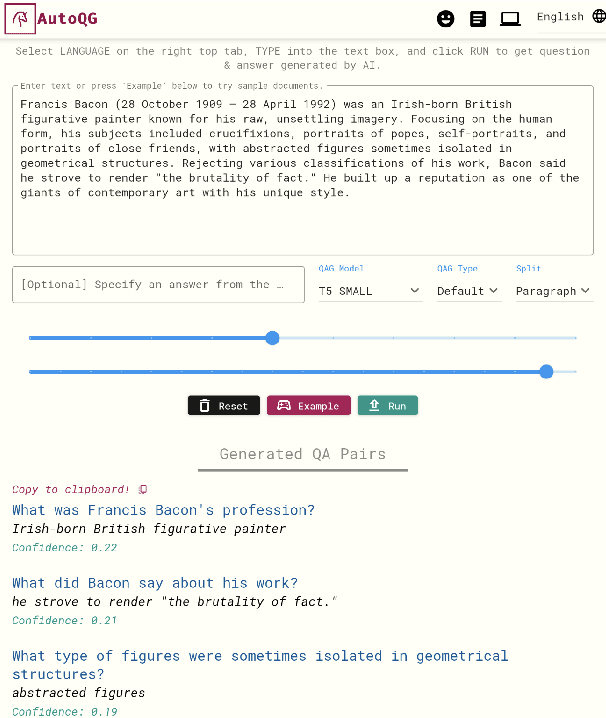
Generating questions along with associated answers from a text has applications in several domains, such as creating reading comprehension tests for students, or improving document search by providing auxiliary questions and answers based on the query. Training models for question and answer generation (QAG) is not straightforward due to the expected structured output (i.e. a list of question and answer pairs), as it requires more than generating a single sentence. This results in a small number of publicly accessible QAG models. In this paper, we introduce AutoQG, an online service for multilingual QAG, along with lmqg, an all-in-one Python package for model fine-tuning, generation, and evaluation. We also release QAG models in eight languages fine-tuned on a few variants of pre-trained encoder-decoder language models, which can be used online via AutoQG or locally via lmqg. With these resources, practitioners of any level can benefit from a toolkit that includes a web interface for end users, and easy-to-use code for developers who require custom models or fine-grained controls for generation.
An Empirical Comparison of LM-based Question and Answer Generation Methods
May 26, 2023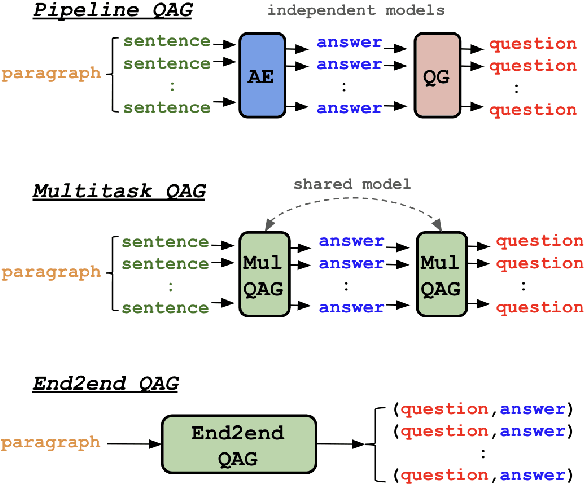
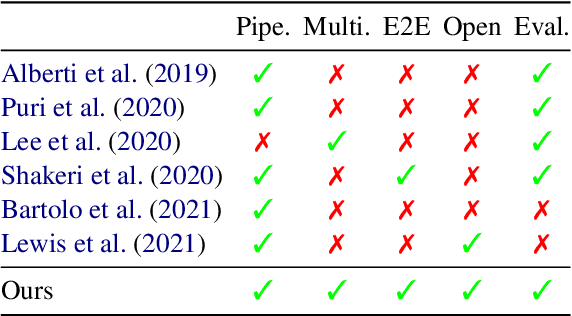
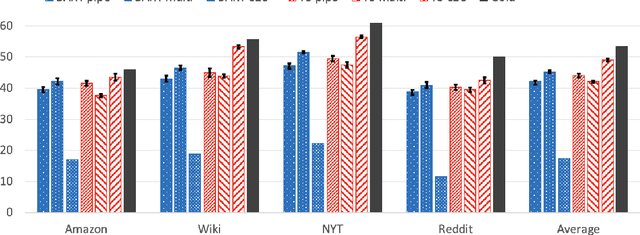
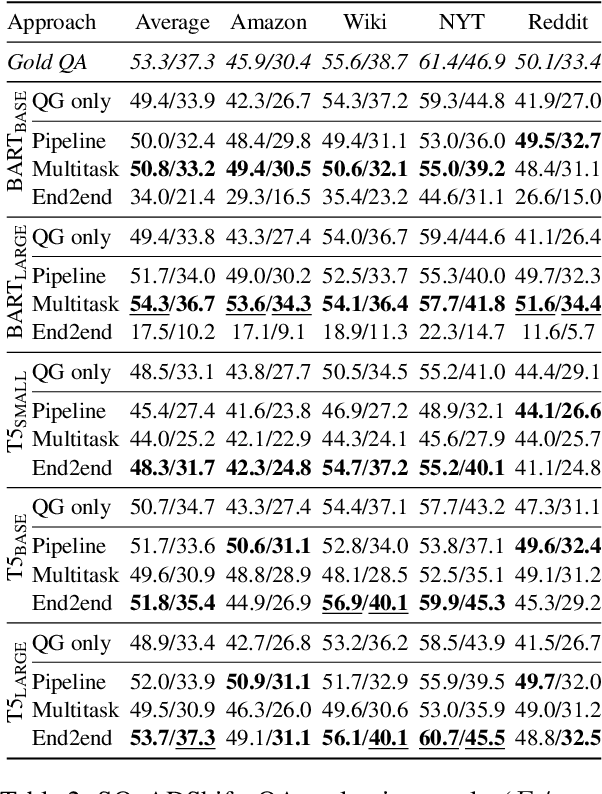
Question and answer generation (QAG) consists of generating a set of question-answer pairs given a context (e.g. a paragraph). This task has a variety of applications, such as data augmentation for question answering (QA) models, information retrieval and education. In this paper, we establish baselines with three different QAG methodologies that leverage sequence-to-sequence language model (LM) fine-tuning. Experiments show that an end-to-end QAG model, which is computationally light at both training and inference times, is generally robust and outperforms other more convoluted approaches. However, there are differences depending on the underlying generative LM. Finally, our analysis shows that QA models fine-tuned solely on generated question-answer pairs can be competitive when compared to supervised QA models trained on human-labeled data.
An Efficient Multilingual Language Model Compression through Vocabulary Trimming
May 24, 2023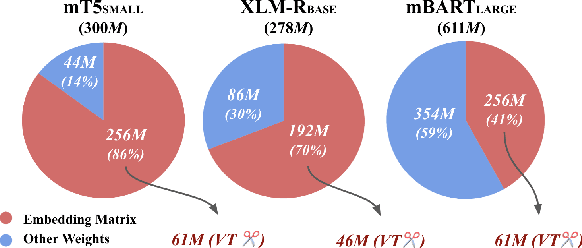
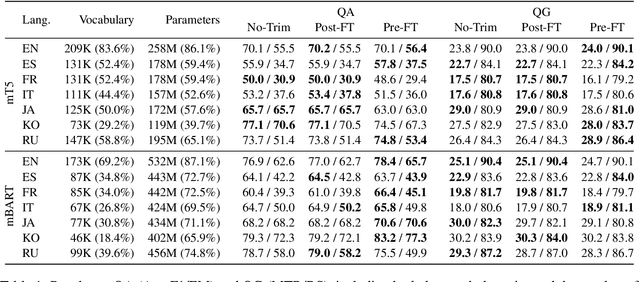
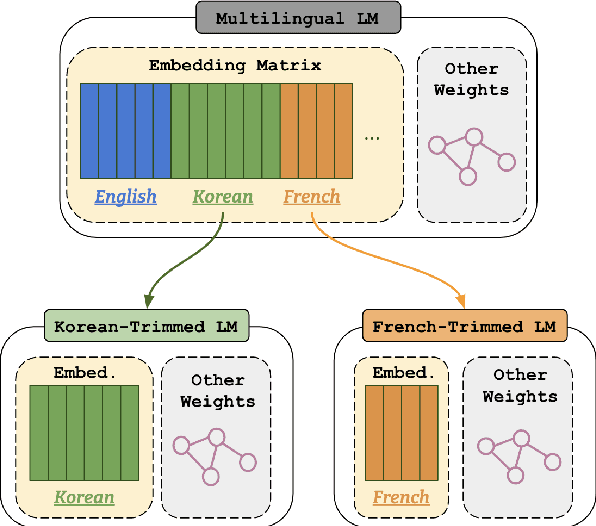
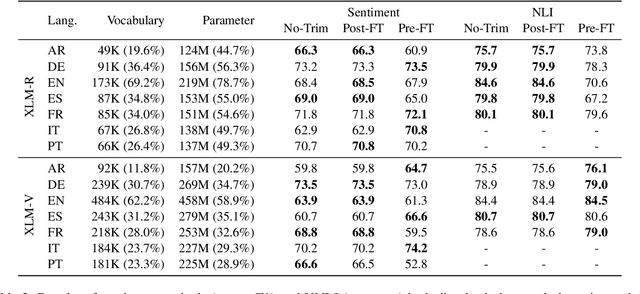
Multilingual language model (LM) have become a powerful tool in NLP especially for non-English languages. Nevertheless, model parameters of multilingual LMs remain large due to the larger embedding matrix of the vocabulary covering tokens in different languages. On the contrary, monolingual LMs can be trained in a target language with the language-specific vocabulary only, but this requires a large budget and availability of reliable corpora to achieve a high-quality LM from scratch. In this paper, we propose vocabulary-trimming (VT), a method to reduce a multilingual LM vocabulary to a target language by deleting irrelevant tokens from its vocabulary. In theory, VT can compress any existing multilingual LM to build monolingual LMs in any language covered by the multilingual LM. In our experiments, we show that VT can retain the original performance of the multilingual LM, while being smaller in size (in general around 50% of the original vocabulary size is enough) than the original multilingual LM. The evaluation is performed over four NLP tasks (two generative and two classification tasks) among four widely used multilingual LMs in seven languages. Finally, we show that this methodology can keep the best of both monolingual and multilingual worlds by keeping a small size as monolingual models without the need for specifically retraining them, and even limiting potentially harmful social biases.