 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJean Kaddour
Text Data Augmentation in Low-Resource Settings via Fine-Tuning of Large Language Models
Oct 02, 2023




The in-context learning ability of large language models (LLMs) enables them to generalize to novel downstream tasks with relatively few labeled examples. However, they require enormous computational resources to be deployed. Alternatively, smaller models can solve specific tasks if fine-tuned with enough labeled examples. These examples, however, are expensive to obtain. In pursuit of the best of both worlds, we study the annotation and generation of fine-tuning training data via fine-tuned teacher LLMs to improve the downstream performance of much smaller models. In four text classification and two text generation tasks, we find that both data generation and annotation dramatically improve the respective downstream model's performance, occasionally necessitating only a minor fraction of the original training dataset.
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models
Jul 26, 2023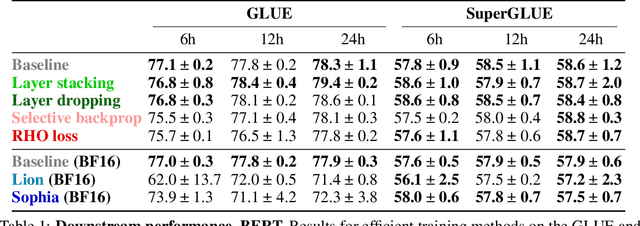
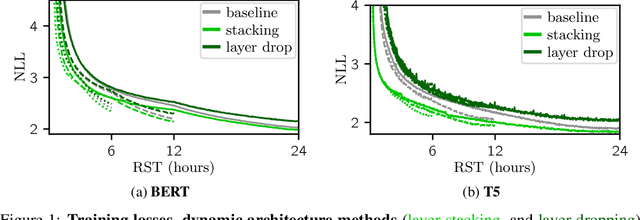
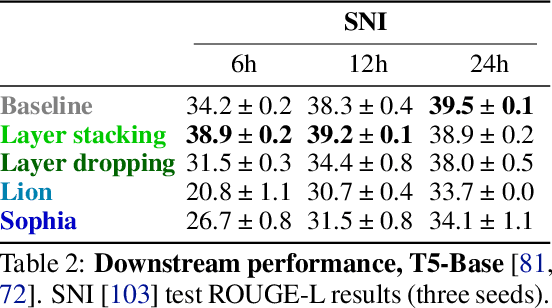
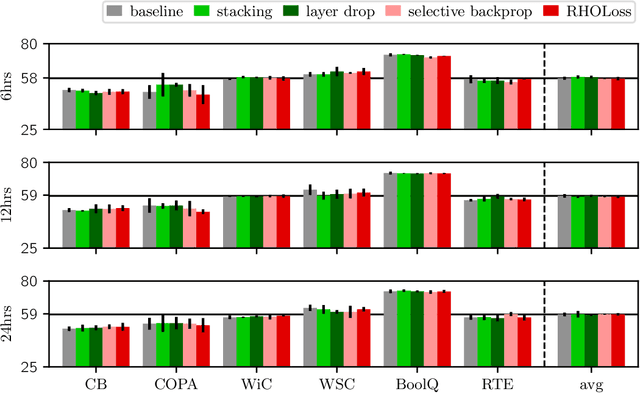
The computation necessary for training Transformer-based language models has skyrocketed in recent years. This trend has motivated research on efficient training algorithms designed to improve training, validation, and downstream performance faster than standard training. In this work, we revisit three categories of such algorithms: dynamic architectures (layer stacking, layer dropping), batch selection (selective backprop, RHO loss), and efficient optimizers (Lion, Sophia). When pre-training BERT and T5 with a fixed computation budget using such methods, we find that their training, validation, and downstream gains vanish compared to a baseline with a fully-decayed learning rate. We define an evaluation protocol that enables computation to be done on arbitrary machines by mapping all computation time to a reference machine which we call reference system time. We discuss the limitations of our proposed protocol and release our code to encourage rigorous research in efficient training procedures: https://github.com/JeanKaddour/NoTrainNoGain.
Challenges and Applications of Large Language Models
Jul 19, 2023Large Language Models (LLMs) went from non-existent to ubiquitous in the machine learning discourse within a few years. Due to the fast pace of the field, it is difficult to identify the remaining challenges and already fruitful application areas. In this paper, we aim to establish a systematic set of open problems and application successes so that ML researchers can comprehend the field's current state more quickly and become productive.
Understanding the Effectiveness of Early Weight Averaging for Training Large Language Models
Jun 05, 2023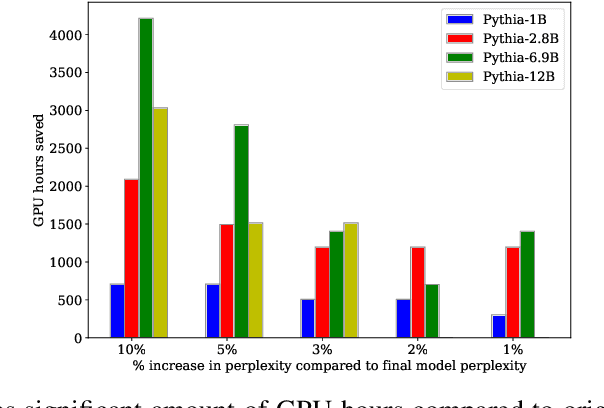
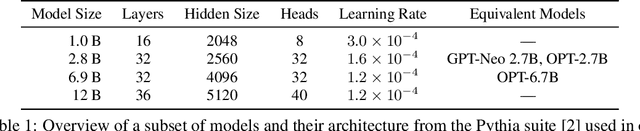
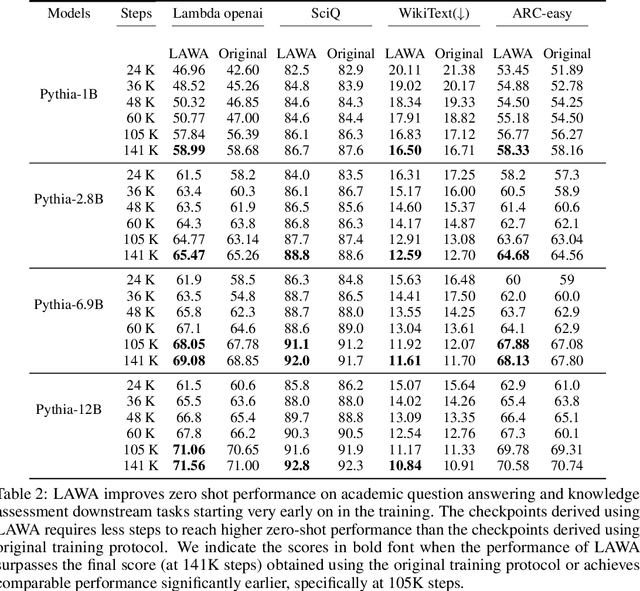
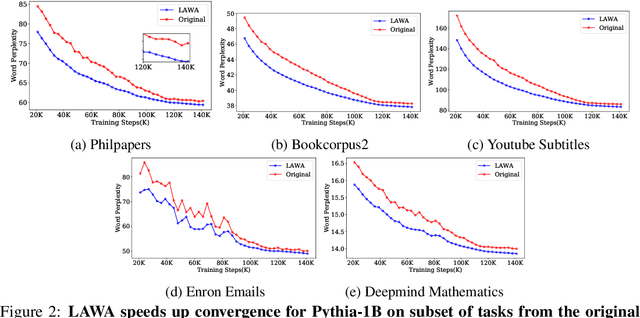
Training LLMs is expensive, and recent evidence indicates training all the way to convergence is inefficient. In this paper, we investigate the ability of a simple idea, checkpoint averaging along the trajectory of a training run to improve the quality of models before they have converged. This approach incurs no extra cost during training or inference. Specifically, we analyze the training trajectories of Pythia LLMs with 1 to 12 billion parameters and demonstrate that, particularly during the early to mid stages of training, this idea accelerates convergence and improves both test and zero-shot generalization. Loss spikes are a well recognized problem in LLM training; in our analysis we encountered two instances of this in the underlying trajectories, and both instances were mitigated by our averaging. For a 6.9B parameter LLM, for example, our early weight averaging recipe can save upto 4200 hours of GPU time, which corresponds to significant savings in cloud compute costs.
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023



Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
The MiniPile Challenge for Data-Efficient Language Models
Apr 17, 2023



The ever-growing diversity of pre-training text corpora has equipped language models with generalization capabilities across various downstream tasks. However, such diverse datasets are often too large for academic budgets; hence, most research on Transformer architectures, training procedures, optimizers, etc. gets conducted on smaller, homogeneous datasets. To this end, we present The MiniPile Challenge, where one pre-trains a language model on a diverse text corpus containing at most 1M documents. MiniPile is a 6GB subset of the deduplicated 825GB The Pile corpus. To curate MiniPile, we perform a simple, three-step data filtering process: we (1) infer embeddings for all documents of the Pile, (2) cluster the embedding space using $k$-means, and (3) filter out low-quality clusters. To verify MiniPile's suitability for language model pre-training, we use it to pre-train a BERT and T5 model, yielding a performance drop of only $1.9\%$/$2.5\%$ on the GLUE and SNI benchmarks compared to the original pre-trained checkpoints trained on $2.6$x/$745$x the amount of data. MiniPile is available at https://huggingface.co/datasets/JeanKaddour/minipile.
Spawrious: A Benchmark for Fine Control of Spurious Correlation Biases
Mar 09, 2023



The problem of spurious correlations (SCs) arises when a classifier relies on non-predictive features that happen to be correlated with the labels in the training data. For example, a classifier may misclassify dog breeds based on the background of dog images. This happens when the backgrounds are correlated with other breeds in the training data, leading to misclassifications during test time. Previous SC benchmark datasets suffer from varying issues, e.g., over-saturation or only containing one-to-one (O2O) SCs, but no many-to-many (M2M) SCs arising between groups of spurious attributes and classes. In this paper, we present Spawrious-{O2O, M2M}-{Easy, Medium, Hard}, an image classification benchmark suite containing spurious correlations among different dog breeds and background locations. To create this dataset, we employ a text-to-image model to generate photo-realistic images, and an image captioning model to filter out unsuitable ones. The resulting dataset is of high quality, containing approximately 152,000 images. Our experimental results demonstrate that state-of-the-art group robustness methods struggle with Spawrious, most notably on the Hard-splits with $<60\%$ accuracy. By examining model misclassifications, we detect reliances on spurious backgrounds, demonstrating that our dataset provides a significant challenge to drive future research.
DAG Learning on the Permutahedron
Feb 10, 2023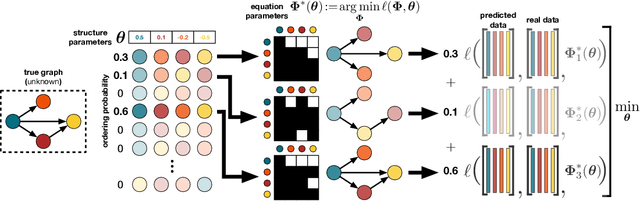
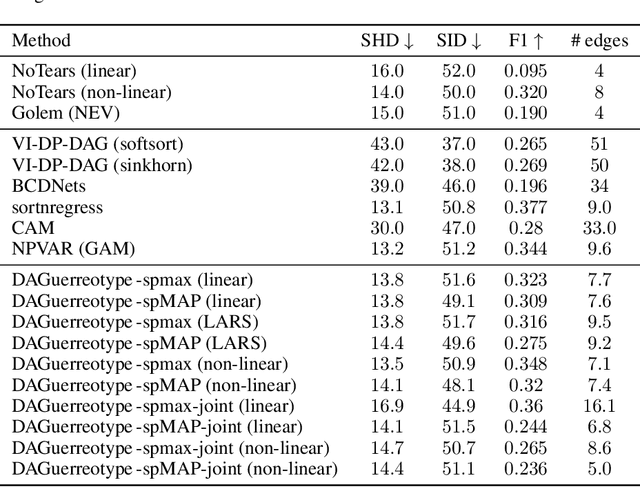
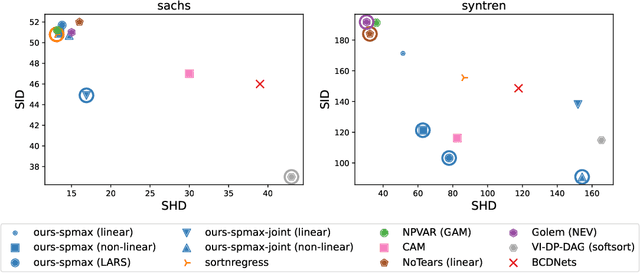
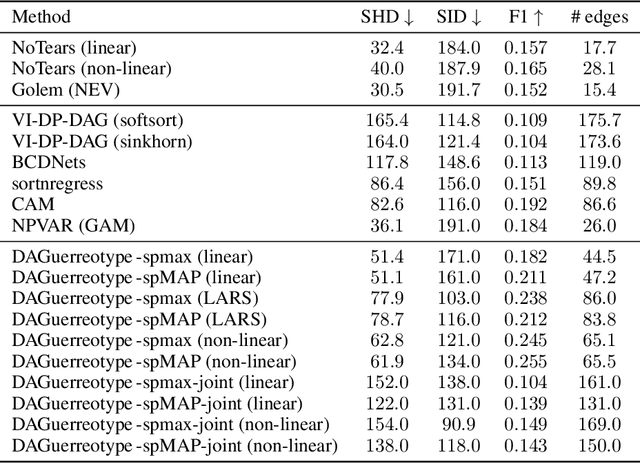
We propose a continuous optimization framework for discovering a latent directed acyclic graph (DAG) from observational data. Our approach optimizes over the polytope of permutation vectors, the so-called Permutahedron, to learn a topological ordering. Edges can be optimized jointly, or learned conditional on the ordering via a non-differentiable subroutine. Compared to existing continuous optimization approaches our formulation has a number of advantages including: 1. validity: optimizes over exact DAGs as opposed to other relaxations optimizing approximate DAGs; 2. modularity: accommodates any edge-optimization procedure, edge structural parameterization, and optimization loss; 3. end-to-end: either alternately iterates between node-ordering and edge-optimization, or optimizes them jointly. We demonstrate, on real-world data problems in protein-signaling and transcriptional network discovery, that our approach lies on the Pareto frontier of two key metrics, the SID and SHD.
Stop Wasting My Time! Saving Days of ImageNet and BERT Training with Latest Weight Averaging
Oct 06, 2022



Training vision or language models on large datasets can take days, if not weeks. We show that averaging the weights of the k latest checkpoints, each collected at the end of an epoch, can speed up the training progression in terms of loss and accuracy by dozens of epochs, corresponding to time savings up to ~68 and ~30 GPU hours when training a ResNet50 on ImageNet and RoBERTa-Base model on WikiText-103, respectively. We also provide the code and model checkpoint trajectory to reproduce the results and facilitate research on reusing historical weights for faster convergence.
Causal Machine Learning: A Survey and Open Problems
Jun 30, 2022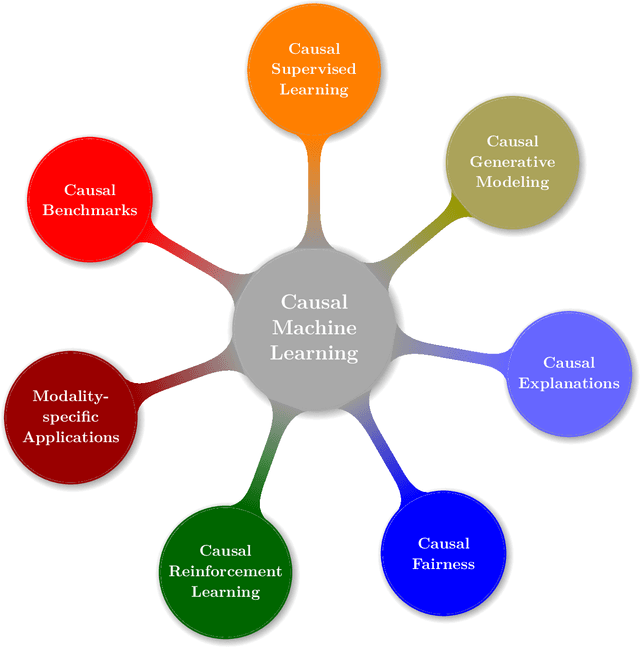
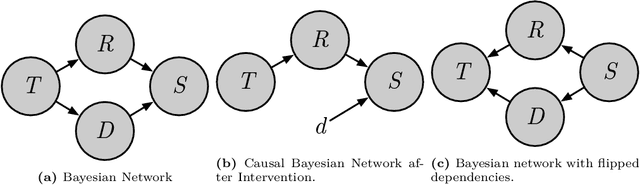

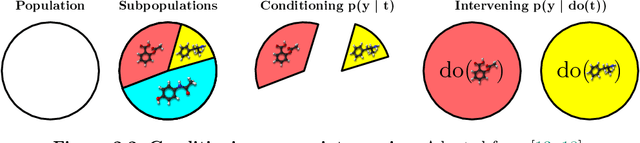
Causal Machine Learning (CausalML) is an umbrella term for machine learning methods that formalize the data-generation process as a structural causal model (SCM). This allows one to reason about the effects of changes to this process (i.e., interventions) and what would have happened in hindsight (i.e., counterfactuals). We categorize work in \causalml into five groups according to the problems they tackle: (1) causal supervised learning, (2) causal generative modeling, (3) causal explanations, (4) causal fairness, (5) causal reinforcement learning. For each category, we systematically compare its methods and point out open problems. Further, we review modality-specific applications in computer vision, natural language processing, and graph representation learning. Finally, we provide an overview of causal benchmarks and a critical discussion of the state of this nascent field, including recommendations for future work.