 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSunny Sanyal
Pre-training Small Base LMs with Fewer Tokens
Apr 12, 2024
We study the effectiveness of a simple approach to develop a small base language model (LM) starting from an existing large base LM: first inherit a few transformer blocks from the larger LM, and then train this smaller model on a very small subset (0.1\%) of the raw pretraining data of the larger model. We call our simple recipe Inheritune and first demonstrate it for building a small base LM with 1.5B parameters using 1B tokens (and a starting few layers of larger LM of 3B parameters); we do this using a single A6000 GPU for less than half a day. Across 9 diverse evaluation datasets as well as the MMLU benchmark, the resulting model compares favorably to publicly available base models of 1B-2B size, some of which have been trained using 50-1000 times more tokens. We investigate Inheritune in a slightly different setting where we train small LMs utilizing larger LMs and their full pre-training dataset. Here we show that smaller LMs trained utilizing some of the layers of GPT2-medium (355M) and GPT-2-large (770M) can effectively match the val loss of their bigger counterparts when trained from scratch for the same number of training steps on OpenWebText dataset with 9B tokens. We analyze our recipe with extensive experiments and demonstrate it efficacy on diverse settings. Our code is available at https://github.com/sanyalsunny111/LLM-Inheritune.
Understanding the Effectiveness of Early Weight Averaging for Training Large Language Models
Jun 05, 2023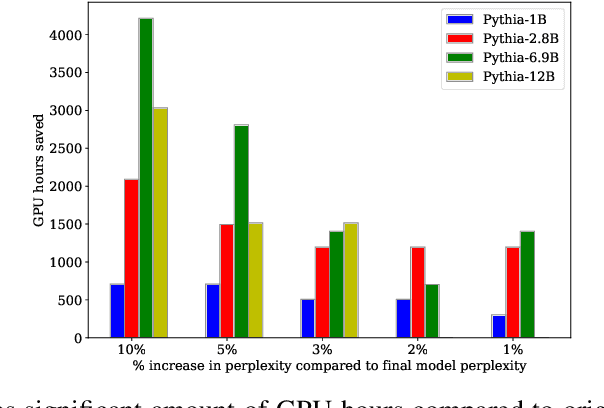
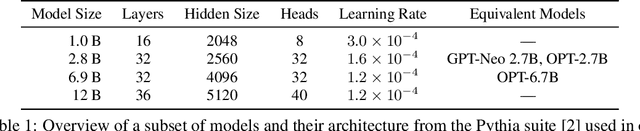
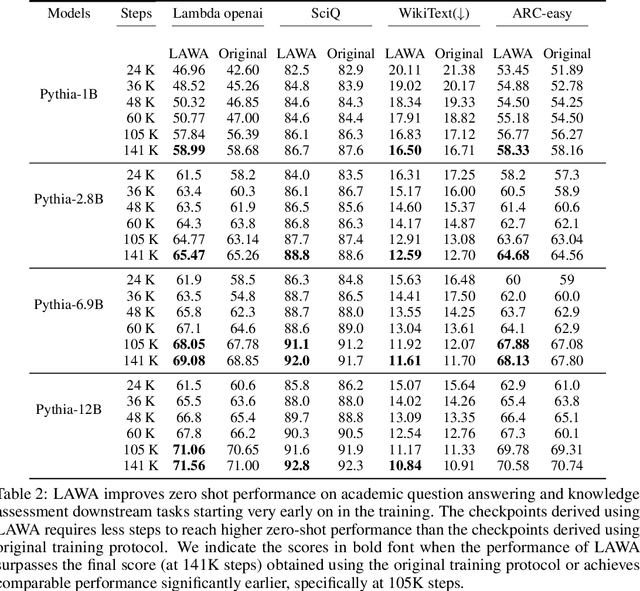
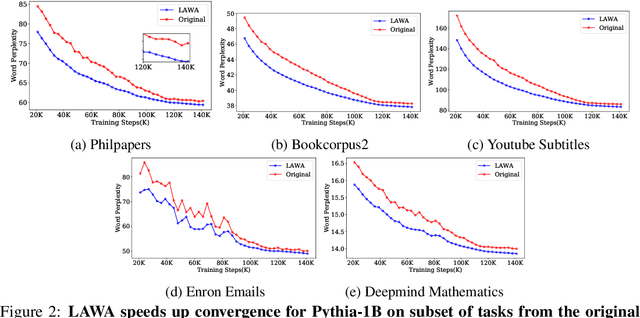
Training LLMs is expensive, and recent evidence indicates training all the way to convergence is inefficient. In this paper, we investigate the ability of a simple idea, checkpoint averaging along the trajectory of a training run to improve the quality of models before they have converged. This approach incurs no extra cost during training or inference. Specifically, we analyze the training trajectories of Pythia LLMs with 1 to 12 billion parameters and demonstrate that, particularly during the early to mid stages of training, this idea accelerates convergence and improves both test and zero-shot generalization. Loss spikes are a well recognized problem in LLM training; in our analysis we encountered two instances of this in the underlying trajectories, and both instances were mitigated by our averaging. For a 6.9B parameter LLM, for example, our early weight averaging recipe can save upto 4200 hours of GPU time, which corresponds to significant savings in cloud compute costs.
Data Aggregation Techniques for Internet of Things
Jul 24, 2019


The goal of this dissertation is to design efficient data aggregation frameworks for massive IoT networks in different scenarios to support the proper functioning of IoT analytics layer. This dissertation includes modern algorithmic frameworks such as non convex optimization, machine learning, stochastic matrix perturbation theory and federated filtering along with modern computing infrastructure such as fog computing and cloud computing. The development of such an ambitious design involves many open challenges, this proposal envisions three major open challenges for IoT data aggregation: first, severe resource constraints of IoT nodes due to limited power and computational ability, second, the highly uncertain (unreliable) raw IoT data is not fit for decisionmaking and third, network latency and privacy issue for critical applications. This dissertation presents three independent novel approaches for distinct scenarios to solve one or more aforementioned open challenges. The first approach focuses on energy efficient routing; discusses a clustering protocol based on device to device communication for both stationary and mobile IoT nodes. The second approach focuses on processing uncertain raw IoT data; presents an IoT data aggregation scheme to improve the quality of raw IoT data. Finally, the third approach focuses on power loss due to communication overhead and privacy issues for medical IoT devices (IoMT); describes a prediction based data aggregation framework for massive IoMT devices.