 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Song
Learning Macroeconomic Policies based on Microfoundations: A Stackelberg Mean Field Game Approach
Mar 14, 2024
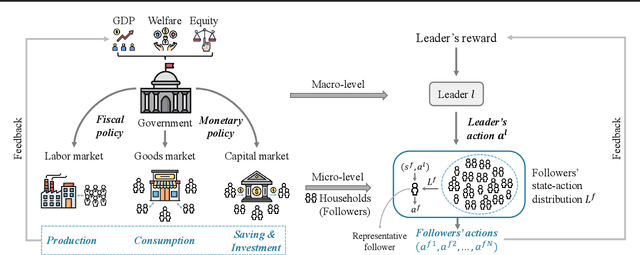

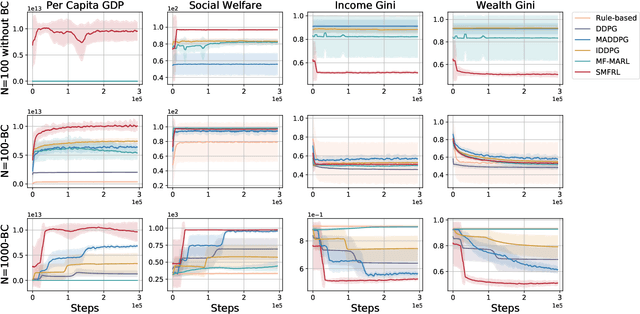

Effective macroeconomic policies play a crucial role in promoting economic growth and social stability. This paper models the optimal macroeconomic policy problem based on the \textit{Stackelberg Mean Field Game} (SMFG), where the government acts as the leader in policy-making, and large-scale households dynamically respond as followers. This modeling method captures the asymmetric dynamic game between the government and large-scale households, and interpretably evaluates the effects of macroeconomic policies based on microfoundations, which is difficult for existing methods to achieve. We also propose a solution for SMFGs, incorporating pre-training on real data and a model-free \textit{Stackelberg mean-field reinforcement learning }(SMFRL) algorithm, which operates independently of prior environmental knowledge and transitions. Our experimental results showcase the superiority of the SMFG method over other economic policies in terms of performance, efficiency-equity tradeoff, and SMFG assumption analysis. This paper significantly contributes to the domain of AI for economics by providing a powerful tool for modeling and solving optimal macroeconomic policies.
Taiyi-Diffusion-XL: Advancing Bilingual Text-to-Image Generation with Large Vision-Language Model Support
Jan 26, 2024Recent advancements in text-to-image models have significantly enhanced image generation capabilities, yet a notable gap of open-source models persists in bilingual or Chinese language support. To address this need, we present Taiyi-Diffusion-XL, a new Chinese and English bilingual text-to-image model which is developed by extending the capabilities of CLIP and Stable-Diffusion-XL through a process of bilingual continuous pre-training. This approach includes the efficient expansion of vocabulary by integrating the most frequently used Chinese characters into CLIP's tokenizer and embedding layers, coupled with an absolute position encoding expansion. Additionally, we enrich text prompts by large vision-language model, leading to better images captions and possess higher visual quality. These enhancements are subsequently applied to downstream text-to-image models. Our empirical results indicate that the developed CLIP model excels in bilingual image-text retrieval.Furthermore, the bilingual image generation capabilities of Taiyi-Diffusion-XL surpass previous models. This research leads to the development and open-sourcing of the Taiyi-Diffusion-XL model, representing a notable advancement in the field of image generation, particularly for Chinese language applications. This contribution is a step forward in addressing the need for more diverse language support in multimodal research. The model and demonstration are made publicly available at \href{https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-XL-3.5B/}{this https URL}, fostering further research and collaboration in this domain.
iDesigner: A High-Resolution and Complex-Prompt Following Text-to-Image Diffusion Model for Interior Design
Dec 19, 2023With the open-sourcing of text-to-image models (T2I) such as stable diffusion (SD) and stable diffusion XL (SD-XL), there is an influx of models fine-tuned in specific domains based on the open-source SD model, such as in anime, character portraits, etc. However, there are few specialized models in certain domains, such as interior design, which is attributed to the complex textual descriptions and detailed visual elements inherent in design, alongside the necessity for adaptable resolution. Therefore, text-to-image models for interior design are required to have outstanding prompt-following capabilities, as well as iterative collaboration with design professionals to achieve the desired outcome. In this paper, we collect and optimize text-image data in the design field and continue training in both English and Chinese on the basis of the open-source CLIP model. We also proposed a fine-tuning strategy with curriculum learning and reinforcement learning from CLIP feedback to enhance the prompt-following capabilities of our approach so as to improve the quality of image generation. The experimental results on the collected dataset demonstrate the effectiveness of the proposed approach, which achieves impressive results and outperforms strong baselines.
Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic-aware Visual Objects
Dec 08, 2023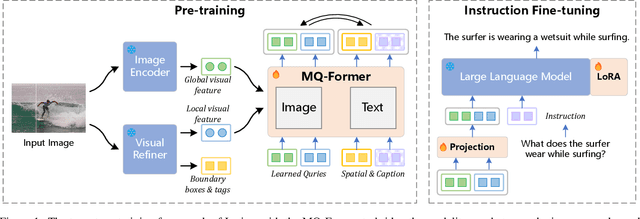

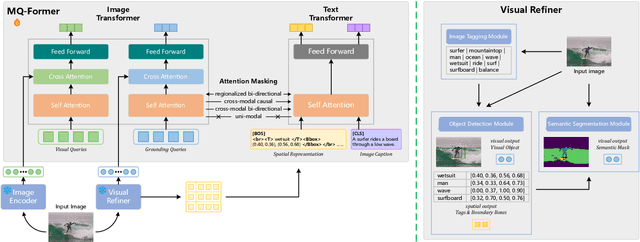
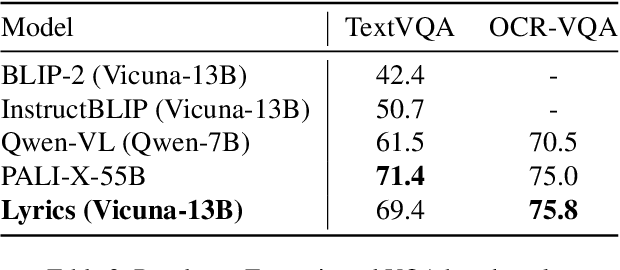
Large Vision Language Models (LVLMs) have demonstrated impressive zero-shot capabilities in various vision-language dialogue scenarios. However, the absence of fine-grained visual object detection hinders the model from understanding the details of images, leading to irreparable visual hallucinations and factual errors. In this paper, we propose Lyrics, a novel multi-modal pre-training and instruction fine-tuning paradigm that bootstraps vision-language alignment from fine-grained cross-modal collaboration. Building on the foundation of BLIP-2, Lyrics infuses local visual features extracted from a visual refiner that includes image tagging, object detection and semantic segmentation modules into the Querying Transformer, while on the text side, the language inputs equip the boundary boxes and tags derived from the visual refiner. We further introduce a two-stage training scheme, in which the pre-training stage bridges the modality gap through explicit and comprehensive vision-language alignment targets. During the instruction fine-tuning stage, we introduce semantic-aware visual feature extraction, a crucial method that enables the model to extract informative features from concrete visual objects. Our approach achieves strong performance on 13 held-out datasets across various vision-language tasks, and demonstrates promising multi-modal understanding and detailed depiction capabilities in real dialogue scenarios.
Improving Image Captioning via Predicting Structured Concepts
Nov 28, 2023Having the difficulty of solving the semantic gap between images and texts for the image captioning task, conventional studies in this area paid some attention to treating semantic concepts as a bridge between the two modalities and improved captioning performance accordingly. Although promising results on concept prediction were obtained, the aforementioned studies normally ignore the relationship among concepts, which relies on not only objects in the image, but also word dependencies in the text, so that offers a considerable potential for improving the process of generating good descriptions. In this paper, we propose a structured concept predictor (SCP) to predict concepts and their structures, then we integrate them into captioning, so as to enhance the contribution of visual signals in this task via concepts and further use their relations to distinguish cross-modal semantics for better description generation. Particularly, we design weighted graph convolutional networks (W-GCN) to depict concept relations driven by word dependencies, and then learns differentiated contributions from these concepts for following decoding process. Therefore, our approach captures potential relations among concepts and discriminatively learns different concepts, so that effectively facilitates image captioning with inherited information across modalities. Extensive experiments and their results demonstrate the effectiveness of our approach as well as each proposed module in this work.
A Systematic Review of Deep Learning-based Research on Radiology Report Generation
Nov 23, 2023Radiology report generation (RRG) aims to automatically generate free-text descriptions from clinical radiographs, e.g., chest X-Ray images. RRG plays an essential role in promoting clinical automation and presents significant help to provide practical assistance for inexperienced doctors and alleviate radiologists' workloads. Therefore, consider these meaningful potentials, research on RRG is experiencing explosive growth in the past half-decade, especially with the rapid development of deep learning approaches. Existing studies perform RRG from the perspective of enhancing different modalities, provide insights on optimizing the report generation process with elaborated features from both visual and textual information, and further facilitate RRG with the cross-modal interactions among them. In this paper, we present a comprehensive review of deep learning-based RRG from various perspectives. Specifically, we firstly cover pivotal RRG approaches based on the task-specific features of radiographs, reports, and the cross-modal relations between them, and then illustrate the benchmark datasets conventionally used for this task with evaluation metrics, subsequently analyze the performance of different approaches and finally offer our summary on the challenges and the trends in future directions. Overall, the goal of this paper is to serve as a tool for understanding existing literature and inspiring potential valuable research in the field of RRG.
ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
Nov 23, 2023
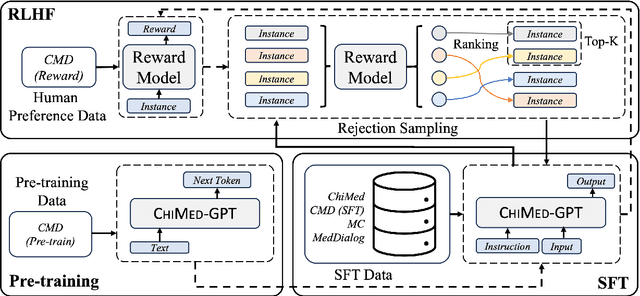
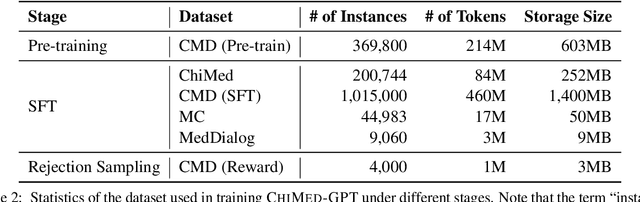
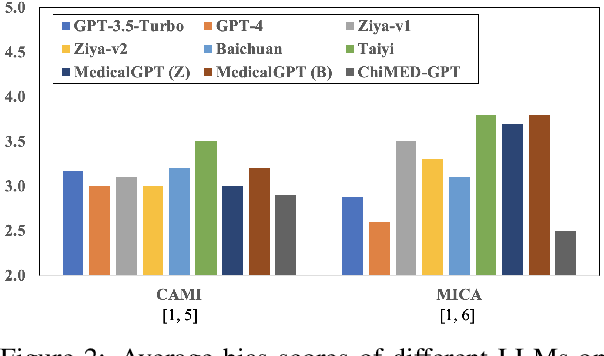
Recently, the increasing demand for superior medical services has highlighted the discrepancies in the medical infrastructure. With big data, especially texts, forming the foundation of medical services, there is an exigent need for effective natural language processing (NLP) solutions tailored to the healthcare domain. Conventional approaches leveraging pre-trained models present promising results in this domain and current large language models (LLMs) offer advanced foundation for medical text processing. However, most medical LLMs are trained only with supervised fine-tuning (SFT), even though it efficiently empowers LLMs to understand and respond to medical instructions but is ineffective in learning domain knowledge and aligning with human preference. Another engineering barrier that prevents current medical LLM from better text processing ability is their restricted context length (e.g., 2,048 tokens), making it hard for the LLMs to process long context, which is frequently required in the medical domain. In this work, we propose ChiMed-GPT, a new benchmark LLM designed explicitly for Chinese medical domain, with enlarged context length to 4,096 tokens and undergoes a comprehensive training regime with pre-training, SFT, and RLHF. Evaluations on real-world tasks including information extraction, question answering, and dialogue generation demonstrate ChiMed-GPT's superior performance over general domain LLMs. Furthermore, we analyze possible biases through prompting ChiMed-GPT to perform attitude scales regarding discrimination of patients, so as to contribute to further responsible development of LLMs in the medical domain. The code and model are released at https://github.com/synlp/ChiMed-GPT.
Ziya2: Data-centric Learning is All LLMs Need
Nov 06, 2023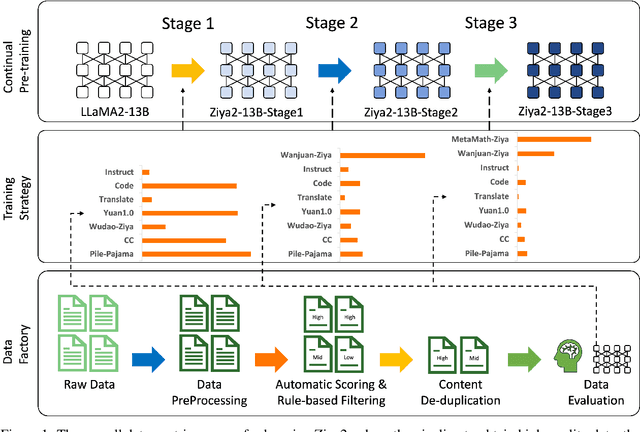
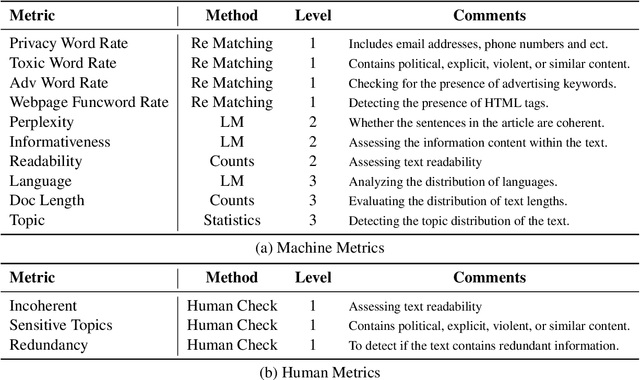
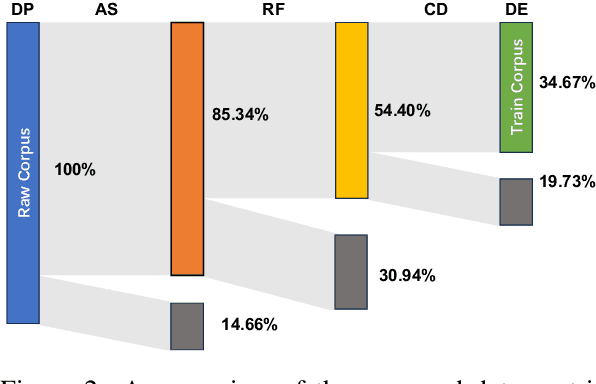
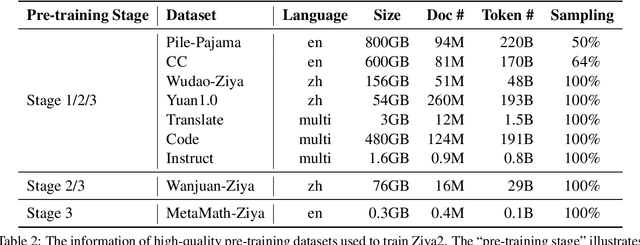
Various large language models (LLMs) have been proposed in recent years, including closed- and open-source ones, continually setting new records on multiple benchmarks. However, the development of LLMs still faces several issues, such as high cost of training models from scratch, and continual pre-training leading to catastrophic forgetting, etc. Although many such issues are addressed along the line of research on LLMs, an important yet practical limitation is that many studies overly pursue enlarging model sizes without comprehensively analyzing and optimizing the use of pre-training data in their learning process, as well as appropriate organization and leveraging of such data in training LLMs under cost-effective settings. In this work, we propose Ziya2, a model with 13 billion parameters adopting LLaMA2 as the foundation model, and further pre-trained on 700 billion tokens, where we focus on pre-training techniques and use data-centric optimization to enhance the learning process of Ziya2 on different stages. Experiments show that Ziya2 significantly outperforms other models in multiple benchmarks especially with promising results compared to representative open-source ones. Ziya2 (Base) is released at https://huggingface.co/IDEA-CCNL/Ziya2-13B-Base and https://modelscope.cn/models/Fengshenbang/Ziya2-13B-Base/summary.
Ziya-Visual: Bilingual Large Vision-Language Model via Multi-Task Instruction Tuning
Oct 29, 2023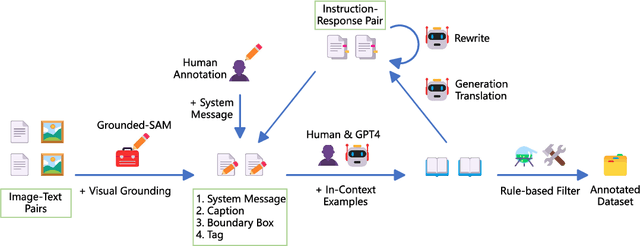
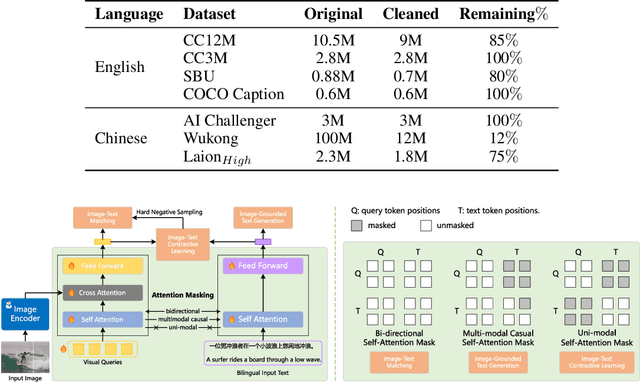

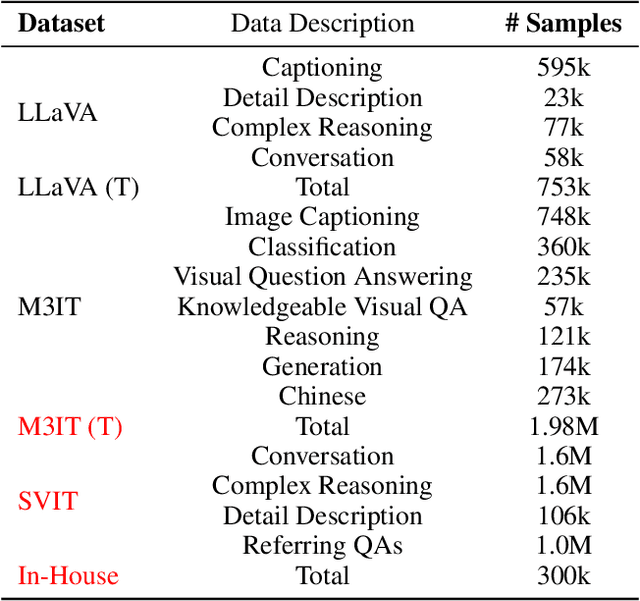
Recent advancements enlarge the capabilities of large language models (LLMs) in zero-shot image-to-text generation and understanding by integrating multi-modal inputs. However, such success is typically limited to English scenarios due to the lack of large-scale and high-quality non-English multi-modal resources, making it extremely difficult to establish competitive counterparts in other languages. In this paper, we introduce the Ziya-Visual series, a set of bilingual large-scale vision-language models (LVLMs) designed to incorporate visual semantics into LLM for multi-modal dialogue. Composed of Ziya-Visual-Base and Ziya-Visual-Chat, our models adopt the Querying Transformer from BLIP-2, further exploring the assistance of optimization schemes such as instruction tuning, multi-stage training and low-rank adaptation module for visual-language alignment. In addition, we stimulate the understanding ability of GPT-4 in multi-modal scenarios, translating our gathered English image-text datasets into Chinese and generating instruction-response through the in-context learning method. The experiment results demonstrate that compared to the existing LVLMs, Ziya-Visual achieves competitive performance across a wide range of English-only tasks including zero-shot image-text retrieval, image captioning, and visual question answering. The evaluation leaderboard accessed by GPT-4 also indicates that our models possess satisfactory image-text understanding and generation capabilities in Chinese multi-modal scenario dialogues. Code, demo and models are available at ~\url{https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1}.
Ask more, know better: Reinforce-Learned Prompt Questions for Decision Making with Large Language Models
Oct 27, 2023Large language models (LLMs) demonstrate their promise in tackling complicated practical challenges by combining action-based policies with chain of thought (CoT) reasoning. Having high-quality prompts on hand, however, is vital to the framework's effectiveness. Currently, these prompts are handcrafted utilizing extensive human labor, resulting in CoT policies that frequently fail to generalize. Human intervention is also required in order to develop grounding functions that ensure low-level controllers appropriately process CoT reasoning. In this paper, we take the first step towards a fully integrated end-to-end framework for task-solving in real settings employing complicated reasoning. To that purpose, we offer a new leader-follower bilevel framework capable of learning to ask relevant questions (prompts) and subsequently undertaking reasoning to guide the learning of actions to be performed in an environment. A good prompt should make introspective revisions based on historical findings, leading the CoT to consider the anticipated goals. A prompt-generator policy has its own aim in our system, allowing it to adapt to the action policy and automatically root the CoT process towards outputs that lead to decisive, high-performing actions. Meanwhile, the action policy is learning how to use the CoT outputs to take specific actions. Our empirical data reveal that our system outperforms leading methods in agent learning benchmarks such as Overcooked and FourRoom.