 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiyu Xia
Cross-Block Fine-Grained Semantic Cascade for Skeleton-Based Sports Action Recognition
Apr 30, 2024
Human action video recognition has recently attracted more attention in applications such as video security and sports posture correction. Popular solutions, including graph convolutional networks (GCNs) that model the human skeleton as a spatiotemporal graph, have proven very effective. GCNs-based methods with stacked blocks usually utilize top-layer semantics for classification/annotation purposes. Although the global features learned through the procedure are suitable for the general classification, they have difficulty capturing fine-grained action change across adjacent frames -- decisive factors in sports actions. In this paper, we propose a novel ``Cross-block Fine-grained Semantic Cascade (CFSC)'' module to overcome this challenge. In summary, the proposed CFSC progressively integrates shallow visual knowledge into high-level blocks to allow networks to focus on action details. In particular, the CFSC module utilizes the GCN feature maps produced at different levels, as well as aggregated features from proceeding levels to consolidate fine-grained features. In addition, a dedicated temporal convolution is applied at each level to learn short-term temporal features, which will be carried over from shallow to deep layers to maximize the leverage of low-level details. This cross-block feature aggregation methodology, capable of mitigating the loss of fine-grained information, has resulted in improved performance. Last, FD-7, a new action recognition dataset for fencing sports, was collected and will be made publicly available. Experimental results and empirical analysis on public benchmarks (FSD-10) and self-collected (FD-7) demonstrate the advantage of our CFSC module on learning discriminative patterns for action classification over others.
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Apr 29, 2024Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
Embedded Representation Learning Network for Animating Styled Video Portrait
Apr 29, 2024The talking head generation recently attracted considerable attention due to its widespread application prospects, especially for digital avatars and 3D animation design. Inspired by this practical demand, several works explored Neural Radiance Fields (NeRF) to synthesize the talking heads. However, these methods based on NeRF face two challenges: (1) Difficulty in generating style-controllable talking heads. (2) Displacement artifacts around the neck in rendered images. To overcome these two challenges, we propose a novel generative paradigm \textit{Embedded Representation Learning Network} (ERLNet) with two learning stages. First, the \textit{ audio-driven FLAME} (ADF) module is constructed to produce facial expression and head pose sequences synchronized with content audio and style video. Second, given the sequence deduced by the ADF, one novel \textit{dual-branch fusion NeRF} (DBF-NeRF) explores these contents to render the final images. Extensive empirical studies demonstrate that the collaboration of these two stages effectively facilitates our method to render a more realistic talking head than the existing algorithms.
Sketch3D: Style-Consistent Guidance for Sketch-to-3D Generation
Apr 07, 2024Recently, image-to-3D approaches have achieved significant results with a natural image as input. However, it is not always possible to access these enriched color input samples in practical applications, where only sketches are available. Existing sketch-to-3D researches suffer from limitations in broad applications due to the challenges of lacking color information and multi-view content. To overcome them, this paper proposes a novel generation paradigm Sketch3D to generate realistic 3D assets with shape aligned with the input sketch and color matching the textual description. Concretely, Sketch3D first instantiates the given sketch in the reference image through the shape-preserving generation process. Second, the reference image is leveraged to deduce a coarse 3D Gaussian prior, and multi-view style-consistent guidance images are generated based on the renderings of the 3D Gaussians. Finally, three strategies are designed to optimize 3D Gaussians, i.e., structural optimization via a distribution transfer mechanism, color optimization with a straightforward MSE loss and sketch similarity optimization with a CLIP-based geometric similarity loss. Extensive visual comparisons and quantitative analysis illustrate the advantage of our Sketch3D in generating realistic 3D assets while preserving consistency with the input.
Learning Macroeconomic Policies based on Microfoundations: A Stackelberg Mean Field Game Approach
Mar 14, 2024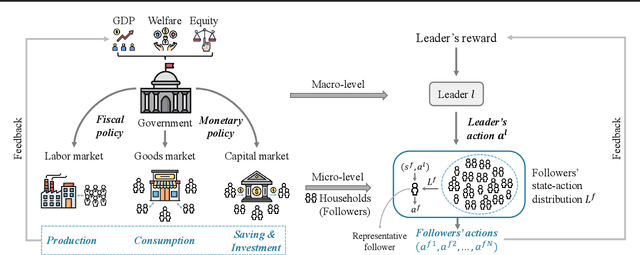

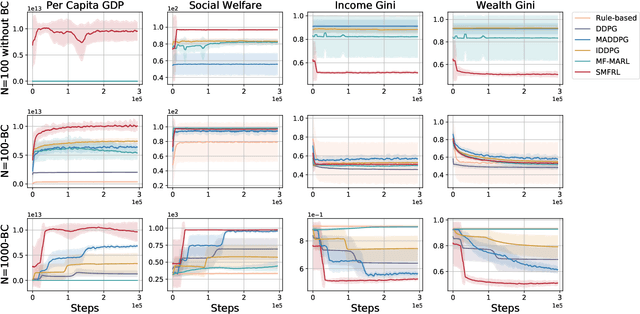

Effective macroeconomic policies play a crucial role in promoting economic growth and social stability. This paper models the optimal macroeconomic policy problem based on the \textit{Stackelberg Mean Field Game} (SMFG), where the government acts as the leader in policy-making, and large-scale households dynamically respond as followers. This modeling method captures the asymmetric dynamic game between the government and large-scale households, and interpretably evaluates the effects of macroeconomic policies based on microfoundations, which is difficult for existing methods to achieve. We also propose a solution for SMFGs, incorporating pre-training on real data and a model-free \textit{Stackelberg mean-field reinforcement learning }(SMFRL) algorithm, which operates independently of prior environmental knowledge and transitions. Our experimental results showcase the superiority of the SMFG method over other economic policies in terms of performance, efficiency-equity tradeoff, and SMFG assumption analysis. This paper significantly contributes to the domain of AI for economics by providing a powerful tool for modeling and solving optimal macroeconomic policies.
Few-shot Shape Recognition by Learning Deep Shape-aware Features
Dec 03, 2023Traditional shape descriptors have been gradually replaced by convolutional neural networks due to their superior performance in feature extraction and classification. The state-of-the-art methods recognize object shapes via image reconstruction or pixel classification. However , these methods are biased toward texture information and overlook the essential shape descriptions, thus, they fail to generalize to unseen shapes. We are the first to propose a fewshot shape descriptor (FSSD) to recognize object shapes given only one or a few samples. We employ an embedding module for FSSD to extract transformation-invariant shape features. Secondly, we develop a dual attention mechanism to decompose and reconstruct the shape features via learnable shape primitives. In this way, any shape can be formed through a finite set basis, and the learned representation model is highly interpretable and extendable to unseen shapes. Thirdly, we propose a decoding module to include the supervision of shape masks and edges and align the original and reconstructed shape features, enforcing the learned features to be more shape-aware. Lastly, all the proposed modules are assembled into a few-shot shape recognition scheme. Experiments on five datasets show that our FSSD significantly improves the shape classification compared to the state-of-the-art under the few-shot setting.
Unsupervised Visual Defect Detection with Score-Based Generative Model
Nov 29, 2022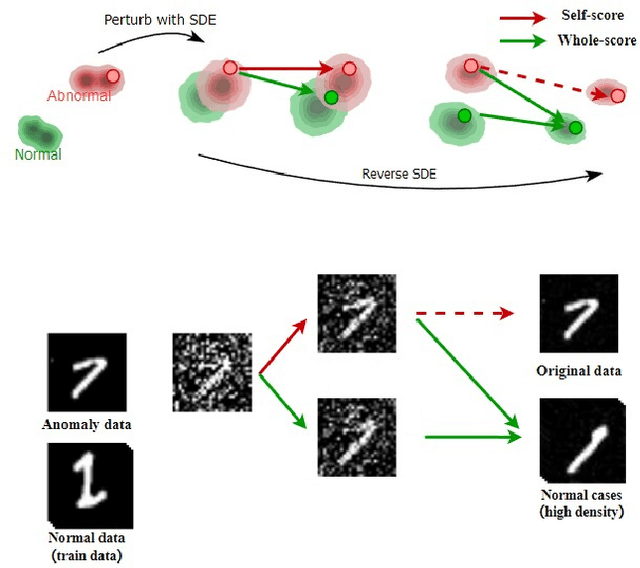
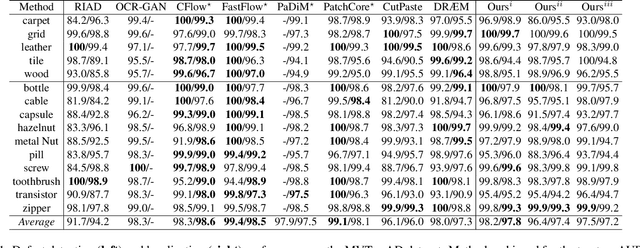

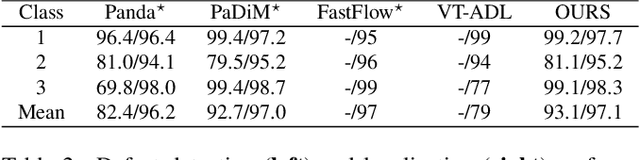
Anomaly Detection (AD), as a critical problem, has been widely discussed. In this paper, we specialize in one specific problem, Visual Defect Detection (VDD), in many industrial applications. And in practice, defect image samples are very rare and difficult to collect. Thus, we focus on the unsupervised visual defect detection and localization tasks and propose a novel framework based on the recent score-based generative models, which synthesize the real image by iterative denoising through stochastic differential equations (SDEs). Our work is inspired by the fact that with noise injected into the original image, the defects may be changed into normal cases in the denoising process (i.e., reconstruction). First, based on the assumption that the anomalous data lie in the low probability density region of the normal data distribution, we explain a common phenomenon that occurs when reconstruction-based approaches are applied to VDD: normal pixels also change during the reconstruction process. Second, due to the differences in normal pixels between the reconstructed and original images, a time-dependent gradient value (i.e., score) of normal data distribution is utilized as a metric, rather than reconstruction loss, to gauge the defects. Third, a novel $T$ scales approach is developed to dramatically reduce the required number of iterations, accelerating the inference process. These practices allow our model to generalize VDD in an unsupervised manner while maintaining reasonably good performance. We evaluate our method on several datasets to demonstrate its effectiveness.
Music2Dance: DanceNet for Music-driven Dance Generation
Mar 10, 2020



Synthesize human motions from music, i.e., music to dance, is appealing and attracts lots of research interests in recent years. It is challenging due to not only the requirement of realistic and complex human motions for dance, but more importantly, the synthesized motions should be consistent with the style, rhythm and melody of the music. In this paper, we propose a novel autoregressive generative model, DanceNet, to take the style, rhythm and melody of music as the control signals to generate 3D dance motions with high realism and diversity. To boost the performance of our proposed model, we capture several synchronized music-dance pairs by professional dancers, and build a high-quality music-dance pair dataset. Experiments have demonstrated that the proposed method can achieve the state-of-the-art results.
Recognizing Families In the Wild (RFIW): The 4th Edition
Mar 09, 2020

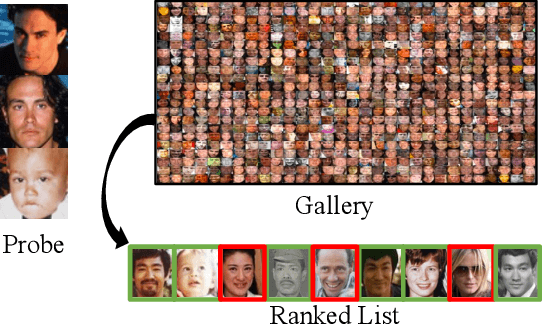

Recognizing Families In the Wild (RFIW): an annual large-scale, multi-track automatic kinship recognition evaluation that supports various visual kin-based problems on scales much higher than ever before. Organized in conjunction with the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG) as a Challenge, RFIW provides a platform for publishing original work and the gathering of experts for a discussion of the next steps. This paper summarizes the supported tasks (i.e., kinship verification, tri-subject verification, and search & retrieval of missing children) in the evaluation protocols, which include the practical motivation, technical background, data splits, metrics, and benchmark results. Furthermore, top submissions (i.e., leader-board stats) are listed and reviewed as a high-level analysis on the state of the problem. In the end, the purpose of this paper is to describe the 2020 RFIW challenge, end-to-end, along with forecasts in promising future directions.
What Will Your Child Look Like? DNA-Net: Age and Gender Aware Kin Face Synthesizer
Nov 16, 2019
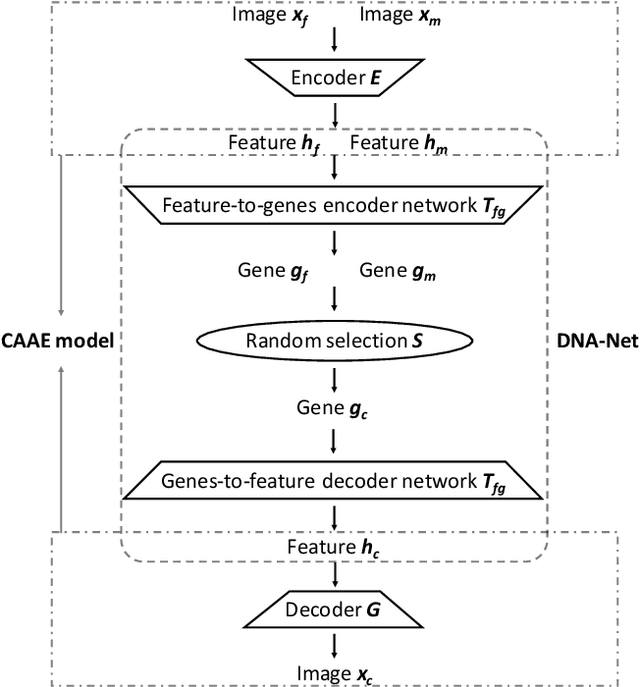


Visual kinship recognition aims to identify blood relatives from facial images. Its practical application-- like in law-enforcement, video surveillance, automatic family album management, and more-- has motivated many researchers to put forth effort on the topic as of recent. In this paper, we focus on a new view of visual kinship technology: kin-based face generation. Specifically, we propose a two-stage kin-face generation model to predict the appearance of a child given a pair of parents. The first stage includes a deep generative adversarial autoencoder conditioned on ages and genders to map between facial appearance and high-level features. The second stage is our proposed DNA-Net, which serves as a transformation between the deep and genetic features based on a random selection process to fuse genes of a parent pair to form the genes of a child. We demonstrate the effectiveness of the proposed method quantitatively and qualitatively: quantitatively, pre-trained models and human subjects perform kinship verification on the generated images of children; qualitatively, we show photo-realistic face images of children that closely resemble the given pair of parents. In the end, experiments validate that the proposed model synthesizes convincing kin-faces using both subjective and objective standards.