 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibo Sun
Cross-Block Fine-Grained Semantic Cascade for Skeleton-Based Sports Action Recognition
Apr 30, 2024
Human action video recognition has recently attracted more attention in applications such as video security and sports posture correction. Popular solutions, including graph convolutional networks (GCNs) that model the human skeleton as a spatiotemporal graph, have proven very effective. GCNs-based methods with stacked blocks usually utilize top-layer semantics for classification/annotation purposes. Although the global features learned through the procedure are suitable for the general classification, they have difficulty capturing fine-grained action change across adjacent frames -- decisive factors in sports actions. In this paper, we propose a novel ``Cross-block Fine-grained Semantic Cascade (CFSC)'' module to overcome this challenge. In summary, the proposed CFSC progressively integrates shallow visual knowledge into high-level blocks to allow networks to focus on action details. In particular, the CFSC module utilizes the GCN feature maps produced at different levels, as well as aggregated features from proceeding levels to consolidate fine-grained features. In addition, a dedicated temporal convolution is applied at each level to learn short-term temporal features, which will be carried over from shallow to deep layers to maximize the leverage of low-level details. This cross-block feature aggregation methodology, capable of mitigating the loss of fine-grained information, has resulted in improved performance. Last, FD-7, a new action recognition dataset for fencing sports, was collected and will be made publicly available. Experimental results and empirical analysis on public benchmarks (FSD-10) and self-collected (FD-7) demonstrate the advantage of our CFSC module on learning discriminative patterns for action classification over others.
G-NeRF: Geometry-enhanced Novel View Synthesis from Single-View Images
Apr 11, 2024Novel view synthesis aims to generate new view images of a given view image collection. Recent attempts address this problem relying on 3D geometry priors (e.g., shapes, sizes, and positions) learned from multi-view images. However, such methods encounter the following limitations: 1) they require a set of multi-view images as training data for a specific scene (e.g., face, car or chair), which is often unavailable in many real-world scenarios; 2) they fail to extract the geometry priors from single-view images due to the lack of multi-view supervision. In this paper, we propose a Geometry-enhanced NeRF (G-NeRF), which seeks to enhance the geometry priors by a geometry-guided multi-view synthesis approach, followed by a depth-aware training. In the synthesis process, inspired that existing 3D GAN models can unconditionally synthesize high-fidelity multi-view images, we seek to adopt off-the-shelf 3D GAN models, such as EG3D, as a free source to provide geometry priors through synthesizing multi-view data. Simultaneously, to further improve the geometry quality of the synthetic data, we introduce a truncation method to effectively sample latent codes within 3D GAN models. To tackle the absence of multi-view supervision for single-view images, we design the depth-aware training approach, incorporating a depth-aware discriminator to guide geometry priors through depth maps. Experiments demonstrate the effectiveness of our method in terms of both qualitative and quantitative results.
SDR-GAIN: A High Real-Time Occluded Pedestrian Pose Completion Method for Autonomous Driving
Jun 10, 2023



To mitigate the challenges arising from partial occlusion in human pose keypoint based pedestrian detection methods , we present a novel pedestrian pose keypoint completion method called the separation and dimensionality reduction-based generative adversarial imputation networks (SDR-GAIN). Firstly, we utilize OpenPose to estimate pedestrian poses in images. Then, we isolate the head and torso keypoints of pedestrians with incomplete keypoints due to occlusion or other factors and perform dimensionality reduction to enhance features and further unify feature distribution. Finally, we introduce two generative models based on the generative adversarial networks (GAN) framework, which incorporate Huber loss, residual structure, and L1 regularization to generate missing parts of the incomplete head and torso pose keypoints of partially occluded pedestrians, resulting in pose completion. Our experiments on MS COCO and JAAD datasets demonstrate that SDR-GAIN outperforms basic GAIN framework, interpolation methods PCHIP and MAkima, machine learning methods k-NN and MissForest in terms of pose completion task. Furthermore, the SDR-GAIN algorithm exhibits a remarkably short running time of approximately 0.4ms and boasts exceptional real-time performance. As such, it holds significant practical value in the domain of autonomous driving, wherein high system response speeds are of paramount importance. Specifically, it excels at rapidly and precisely capturing human pose key points, thus enabling an expanded range of applications for pedestrian detection tasks based on pose key points, including but not limited to pedestrian behavior recognition and prediction.
SC-DepthV3: Robust Self-supervised Monocular Depth Estimation for Dynamic Scenes
Nov 07, 2022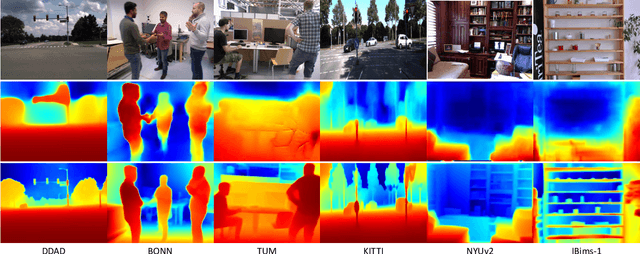
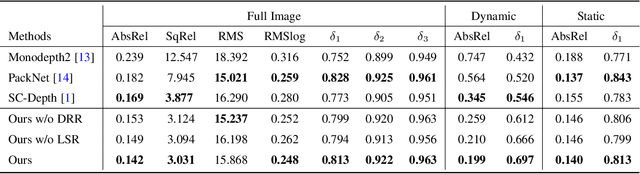
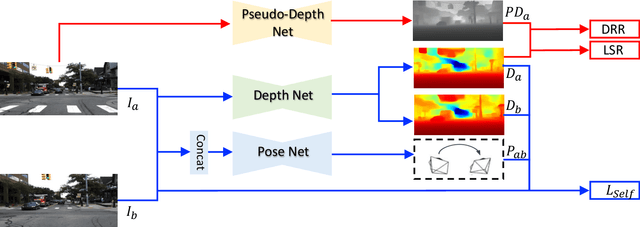
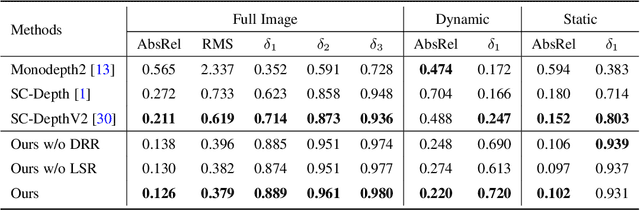
Self-supervised monocular depth estimation has shown impressive results in static scenes. It relies on the multi-view consistency assumption for training networks, however, that is violated in dynamic object regions and occlusions. Consequently, existing methods show poor accuracy in dynamic scenes, and the estimated depth map is blurred at object boundaries because they are usually occluded in other training views. In this paper, we propose SC-DepthV3 for addressing the challenges. Specifically, we introduce an external pretrained monocular depth estimation model for generating single-image depth prior, namely pseudo-depth, based on which we propose novel losses to boost self-supervised training. As a result, our model can predict sharp and accurate depth maps, even when training from monocular videos of highly-dynamic scenes. We demonstrate the significantly superior performance of our method over previous methods on six challenging datasets, and we provide detailed ablation studies for the proposed terms. Source code and data will be released at https://github.com/JiawangBian/sc_depth_pl
Improving Monocular Visual Odometry Using Learned Depth
Apr 04, 2022



Monocular visual odometry (VO) is an important task in robotics and computer vision. Thus far, how to build accurate and robust monocular VO systems that can work well in diverse scenarios remains largely unsolved. In this paper, we propose a framework to exploit monocular depth estimation for improving VO. The core of our framework is a monocular depth estimation module with a strong generalization capability for diverse scenes. It consists of two separate working modes to assist the localization and mapping. With a single monocular image input, the depth estimation module predicts a relative depth to help the localization module on improving the accuracy. With a sparse depth map and an RGB image input, the depth estimation module can generate accurate scale-consistent depth for dense mapping. Compared with current learning-based VO methods, our method demonstrates a stronger generalization ability to diverse scenes. More significantly, our framework is able to boost the performances of existing geometry-based VO methods by a large margin.
Pseudo-LiDAR Based Road Detection
Jul 28, 2021



Road detection is a critically important task for self-driving cars. By employing LiDAR data, recent works have significantly improved the accuracy of road detection. Relying on LiDAR sensors limits the wide application of those methods when only cameras are available. In this paper, we propose a novel road detection approach with RGB being the only input during inference. Specifically, we exploit pseudo-LiDAR using depth estimation, and propose a feature fusion network where RGB and learned depth information are fused for improved road detection. To further optimize the network structure and improve the efficiency of the network. we search for the network structure of the feature fusion module using NAS techniques. Finally, be aware of that generating pseudo-LiDAR from RGB via depth estimation introduces extra computational costs and relies on depth estimation networks, we design a modality distillation strategy and leverage it to further free our network from these extra computational cost and dependencies during inference. The proposed method achieves state-of-the-art performance on two challenging benchmarks, KITTI and R2D.
Shedding some light on Light Up with Artificial Intelligence
Jul 22, 2021



The Light-Up puzzle, also known as the AKARI puzzle, has never been solved using modern artificial intelligence (AI) methods. Currently, the most widely used computational technique to autonomously develop solutions involve evolution theory algorithms. This project is an effort to apply new AI techniques for solving the Light-up puzzle faster and more computationally efficient. The algorithms explored for producing optimal solutions include hill climbing, simulated annealing, feed-forward neural network (FNN), and convolutional neural network (CNN). Two algorithms were developed for hill climbing and simulated annealing using 2 actions (add and remove light bulb) versus 3 actions(add, remove, or move light-bulb to a different cell). Both hill climbing and simulated annealing algorithms showed a higher accuracy for the case of 3 actions. The simulated annealing showed to significantly outperform hill climbing, FNN, CNN, and an evolutionary theory algorithm achieving 100% accuracy in 30 unique board configurations. Lastly, while FNN and CNN algorithms showed low accuracies, computational times were significantly faster compared to the remaining algorithms. The GitHub repository for this project can be found at https://github.com/rperera12/AKARI-LightUp-GameSolver-with-DeepNeuralNetworks-and-HillClimb-or-SimulatedAnnealing.