 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSi Qin
Verco: Learning Coordinated Verbal Communication for Multi-agent Reinforcement Learning
Apr 27, 2024
In recent years, multi-agent reinforcement learning algorithms have made significant advancements in diverse gaming environments, leading to increased interest in the broader application of such techniques. To address the prevalent challenge of partial observability, communication-based algorithms have improved cooperative performance through the sharing of numerical embedding between agents. However, the understanding of the formation of collaborative mechanisms is still very limited, making designing a human-understandable communication mechanism a valuable problem to address. In this paper, we propose a novel multi-agent reinforcement learning algorithm that embeds large language models into agents, endowing them with the ability to generate human-understandable verbal communication. The entire framework has a message module and an action module. The message module is responsible for generating and sending verbal messages to other agents, effectively enhancing information sharing among agents. To further enhance the message module, we employ a teacher model to generate message labels from the global view and update the student model through Supervised Fine-Tuning (SFT). The action module receives messages from other agents and selects actions based on current local observations and received messages. Experiments conducted on the Overcooked game demonstrate our method significantly enhances the learning efficiency and performance of existing methods, while also providing an interpretable tool for humans to understand the process of multi-agent cooperation.
UFO: A UI-Focused Agent for Windows OS Interaction
Feb 23, 2024We introduce UFO, an innovative UI-Focused agent to fulfill user requests tailored to applications on Windows OS, harnessing the capabilities of GPT-Vision. UFO employs a dual-agent framework to meticulously observe and analyze the graphical user interface (GUI) and control information of Windows applications. This enables the agent to seamlessly navigate and operate within individual applications and across them to fulfill user requests, even when spanning multiple applications. The framework incorporates a control interaction module, facilitating action grounding without human intervention and enabling fully automated execution. Consequently, UFO transforms arduous and time-consuming processes into simple tasks achievable solely through natural language commands. We conducted testing of UFO across 9 popular Windows applications, encompassing a variety of scenarios reflective of users' daily usage. The results, derived from both quantitative metrics and real-case studies, underscore the superior effectiveness of UFO in fulfilling user requests. To the best of our knowledge, UFO stands as the first UI agent specifically tailored for task completion within the Windows OS environment. The open-source code for UFO is available on https://github.com/microsoft/UFO.
COIN: Chance-Constrained Imitation Learning for Uncertainty-aware Adaptive Resource Oversubscription Policy
Jan 13, 2024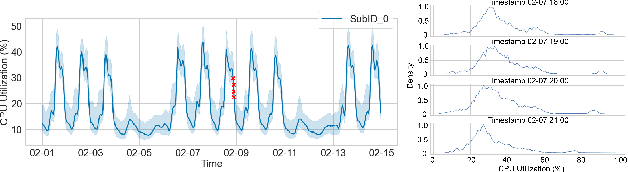
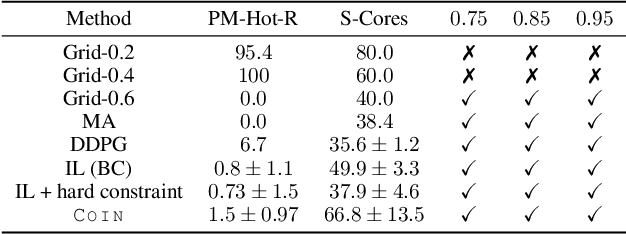
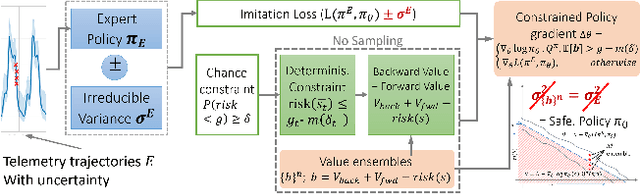
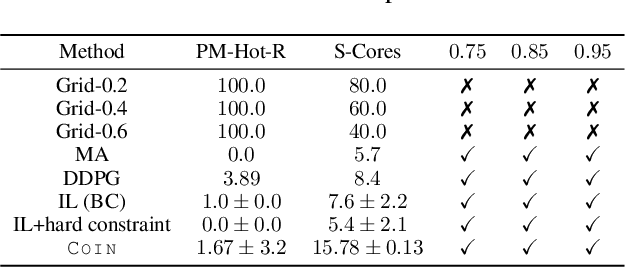
We address the challenge of learning safe and robust decision policies in presence of uncertainty in context of the real scientific problem of adaptive resource oversubscription to enhance resource efficiency while ensuring safety against resource congestion risk. Traditional supervised prediction or forecasting models are ineffective in learning adaptive policies whereas standard online optimization or reinforcement learning is difficult to deploy on real systems. Offline methods such as imitation learning (IL) are ideal since we can directly leverage historical resource usage telemetry. But, the underlying aleatoric uncertainty in such telemetry is a critical bottleneck. We solve this with our proposed novel chance-constrained imitation learning framework, which ensures implicit safety against uncertainty in a principled manner via a combination of stochastic (chance) constraints on resource congestion risk and ensemble value functions. This leads to substantial ($\approx 3-4\times$) improvement in resource efficiency and safety in many oversubscription scenarios, including resource management in cloud services.
Xpert: Empowering Incident Management with Query Recommendations via Large Language Models
Dec 19, 2023Large-scale cloud systems play a pivotal role in modern IT infrastructure. However, incidents occurring within these systems can lead to service disruptions and adversely affect user experience. To swiftly resolve such incidents, on-call engineers depend on crafting domain-specific language (DSL) queries to analyze telemetry data. However, writing these queries can be challenging and time-consuming. This paper presents a thorough empirical study on the utilization of queries of KQL, a DSL employed for incident management in a large-scale cloud management system at Microsoft. The findings obtained underscore the importance and viability of KQL queries recommendation to enhance incident management. Building upon these valuable insights, we introduce Xpert, an end-to-end machine learning framework that automates KQL recommendation process. By leveraging historical incident data and large language models, Xpert generates customized KQL queries tailored to new incidents. Furthermore, Xpert incorporates a novel performance metric called Xcore, enabling a thorough evaluation of query quality from three comprehensive perspectives. We conduct extensive evaluations of Xpert, demonstrating its effectiveness in offline settings. Notably, we deploy Xpert in the real production environment of a large-scale incident management system in Microsoft, validating its efficiency in supporting incident management. To the best of our knowledge, this paper represents the first empirical study of its kind, and Xpert stands as a pioneering DSL query recommendation framework designed for incident management.
TaskWeaver: A Code-First Agent Framework
Dec 01, 2023
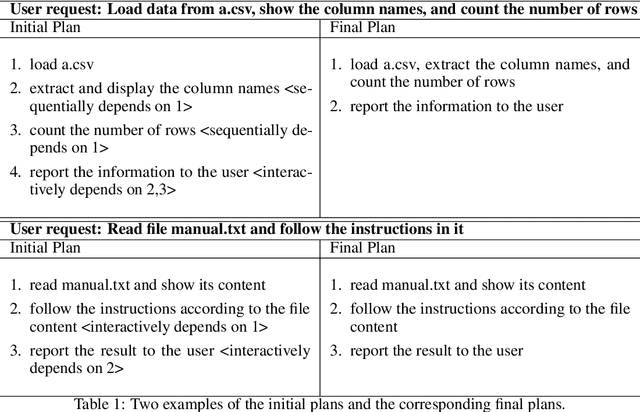
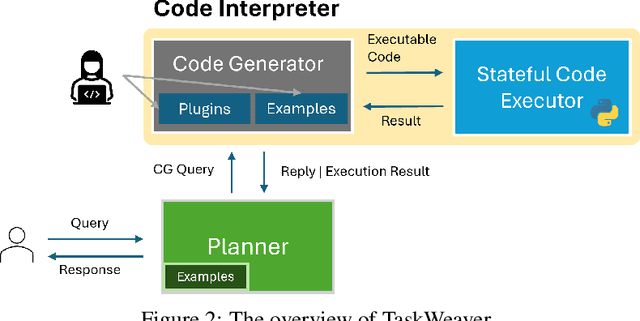
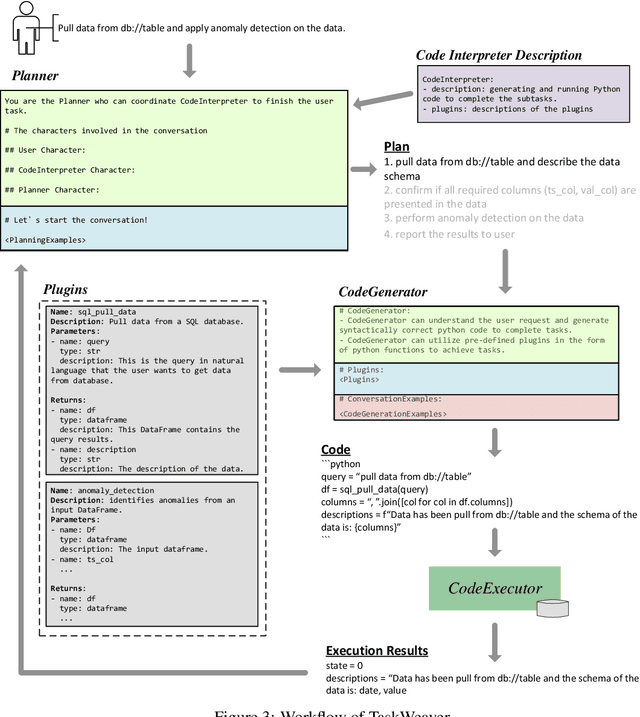
Large Language Models (LLMs) have shown impressive abilities in natural language understanding and generation, leading to their use in applications such as chatbots and virtual assistants. However, existing LLM frameworks face limitations in handling domain-specific data analytics tasks with rich data structures. Moreover, they struggle with flexibility to meet diverse user requirements. To address these issues, TaskWeaver is proposed as a code-first framework for building LLM-powered autonomous agents. It converts user requests into executable code and treats user-defined plugins as callable functions. TaskWeaver provides support for rich data structures, flexible plugin usage, and dynamic plugin selection, and leverages LLM coding capabilities for complex logic. It also incorporates domain-specific knowledge through examples and ensures the secure execution of generated code. TaskWeaver offers a powerful and flexible framework for creating intelligent conversational agents that can handle complex tasks and adapt to domain-specific scenarios. The code is open-sourced at https://github.com/microsoft/TaskWeaver/.
Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
Nov 12, 2023



Recent advancements in Large Language Models (LLMs) have revolutionized decision-making by breaking down complex problems into more manageable language sequences referred to as ``thoughts''. An effective thought design should consider three key perspectives: performance, efficiency, and flexibility. However, existing thought can at most exhibit two of these attributes. To address these limitations, we introduce a novel thought prompting approach called ``Everything of Thoughts'' (XoT) to defy the law of ``Penrose triangle of existing thought paradigms. XoT leverages pretrained reinforcement learning and Monte Carlo Tree Search (MCTS) to incorporate external domain knowledge into thoughts, thereby enhancing LLMs' capabilities and enabling them to generalize to unseen problems efficiently. Through the utilization of the MCTS-LLM collaborative thought revision framework, this approach autonomously produces high-quality comprehensive cognitive mappings with minimal LLM interactions. Additionally, XoT empowers LLMs to engage in unconstrained thinking, allowing for flexible cognitive mappings for problems with multiple solutions. We evaluate XoT on several challenging multi-solution problem-solving tasks, including Game of 24, 8-Puzzle, and Pocket Cube. Our results demonstrate that XoT significantly outperforms existing approaches. Notably, XoT can yield multiple solutions with just one LLM call, showcasing its remarkable proficiency in addressing complex problems across diverse domains.
Counter-Empirical Attacking based on Adversarial Reinforcement Learning for Time-Relevant Scoring System
Nov 09, 2023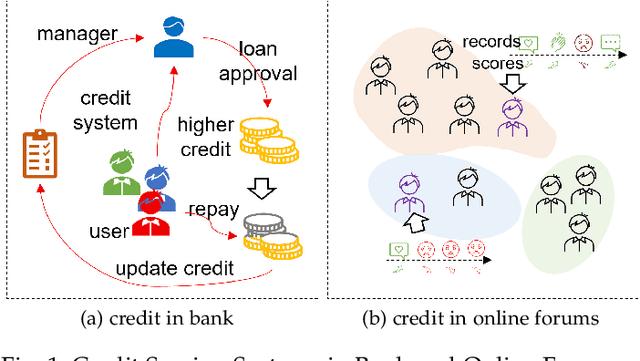
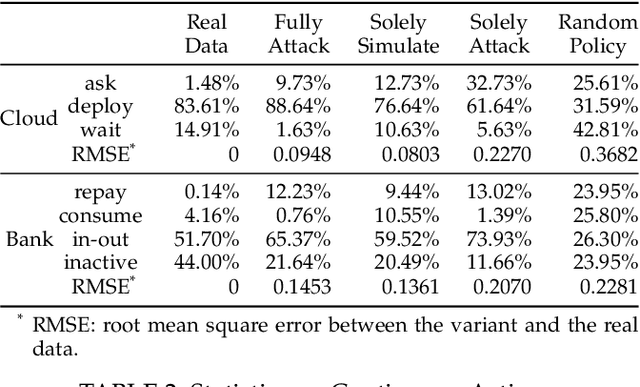
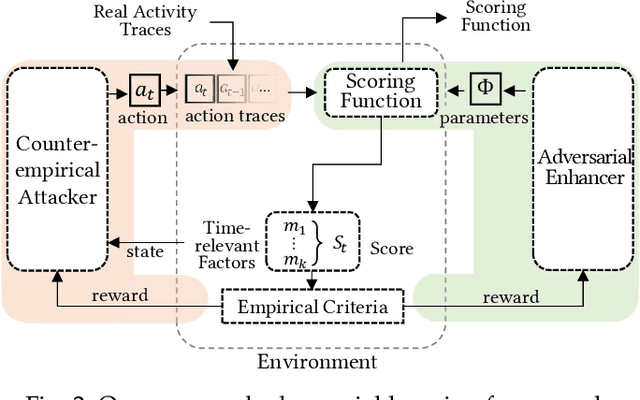
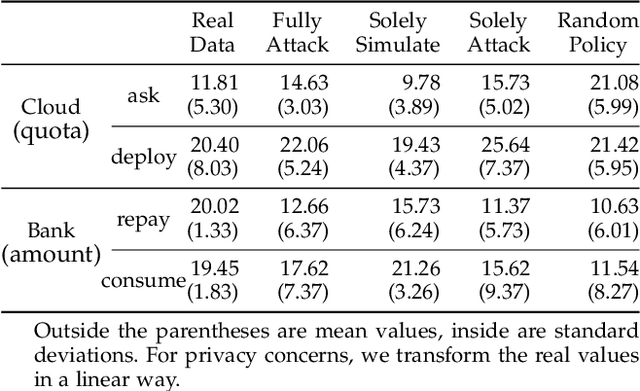
Scoring systems are commonly seen for platforms in the era of big data. From credit scoring systems in financial services to membership scores in E-commerce shopping platforms, platform managers use such systems to guide users towards the encouraged activity pattern, and manage resources more effectively and more efficiently thereby. To establish such scoring systems, several "empirical criteria" are firstly determined, followed by dedicated top-down design for each factor of the score, which usually requires enormous effort to adjust and tune the scoring function in the new application scenario. What's worse, many fresh projects usually have no ground-truth or any experience to evaluate a reasonable scoring system, making the designing even harder. To reduce the effort of manual adjustment of the scoring function in every new scoring system, we innovatively study the scoring system from the preset empirical criteria without any ground truth, and propose a novel framework to improve the system from scratch. In this paper, we propose a "counter-empirical attacking" mechanism that can generate "attacking" behavior traces and try to break the empirical rules of the scoring system. Then an adversarial "enhancer" is applied to evaluate the scoring system and find the improvement strategy. By training the adversarial learning problem, a proper scoring function can be learned to be robust to the attacking activity traces that are trying to violate the empirical criteria. Extensive experiments have been conducted on two scoring systems including a shared computing resource platform and a financial credit system. The experimental results have validated the effectiveness of our proposed framework.
Introspective Tips: Large Language Model for In-Context Decision Making
May 19, 2023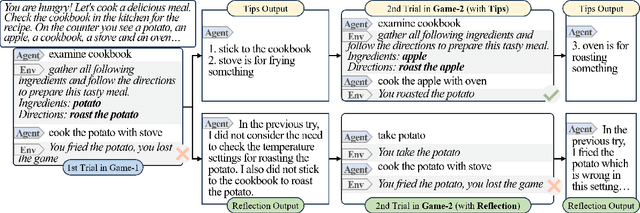

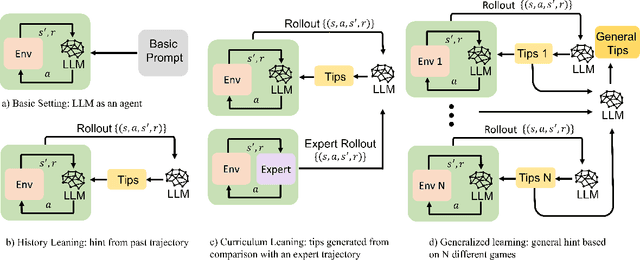

The emergence of large language models (LLMs) has substantially influenced natural language processing, demonstrating exceptional results across various tasks. In this study, we employ ``Introspective Tips" to facilitate LLMs in self-optimizing their decision-making. By introspectively examining trajectories, LLM refines its policy by generating succinct and valuable tips. Our method enhances the agent's performance in both few-shot and zero-shot learning situations by considering three essential scenarios: learning from the agent's past experiences, integrating expert demonstrations, and generalizing across diverse games. Importantly, we accomplish these improvements without fine-tuning the LLM parameters; rather, we adjust the prompt to generalize insights from the three aforementioned situations. Our framework not only supports but also emphasizes the advantage of employing LLM in in-contxt decision-making. Experiments involving over 100 games in TextWorld illustrate the superior performance of our approach.
Learning Cooperative Oversubscription for Cloud by Chance-Constrained Multi-Agent Reinforcement Learning
Nov 21, 2022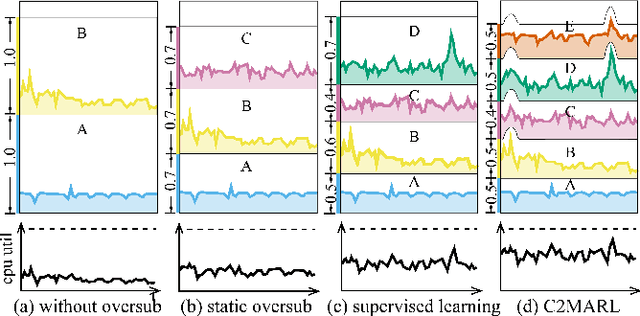
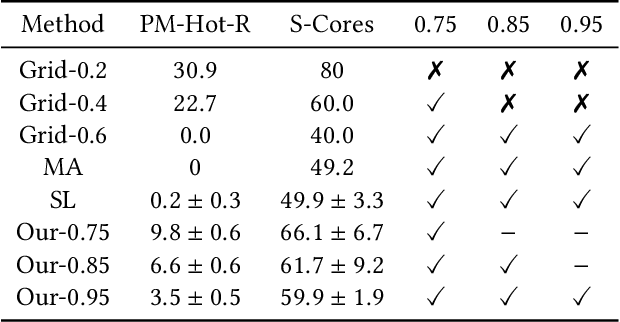
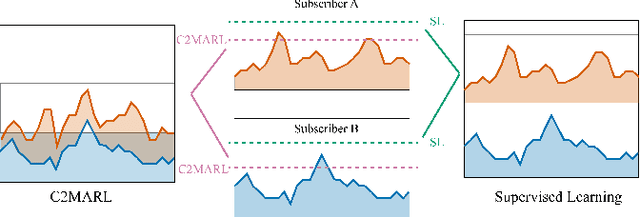
Oversubscription is a common practice for improving cloud resource utilization. It allows the cloud service provider to sell more resources than the physical limit, assuming not all users would fully utilize the resources simultaneously. However, how to design an oversubscription policy that improves utilization while satisfying the some safety constraints remains an open problem. Existing methods and industrial practices are over-conservative, ignoring the coordination of diverse resource usage patterns and probabilistic constraints. To address these two limitations, this paper formulates the oversubscription for cloud as a chance-constrained optimization problem and propose an effective Chance Constrained Multi-Agent Reinforcement Learning (C2MARL) method to solve this problem. Specifically, C2MARL reduces the number of constraints by considering their upper bounds and leverages a multi-agent reinforcement learning paradigm to learn a safe and optimal coordination policy. We evaluate our C2MARL on an internal cloud platform and public cloud datasets. Experiments show that our C2MARL outperforms existing methods in improving utilization ($20\%\sim 86\%$) under different levels of safety constraints.
Solving the Batch Stochastic Bin Packing Problem in Cloud: A Chance-constrained Optimization Approach
Jul 20, 2022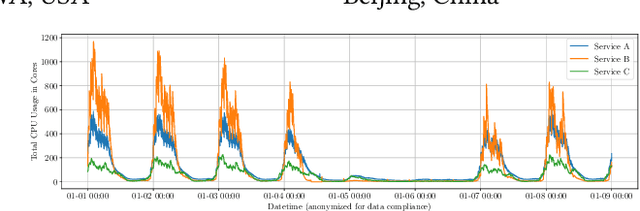
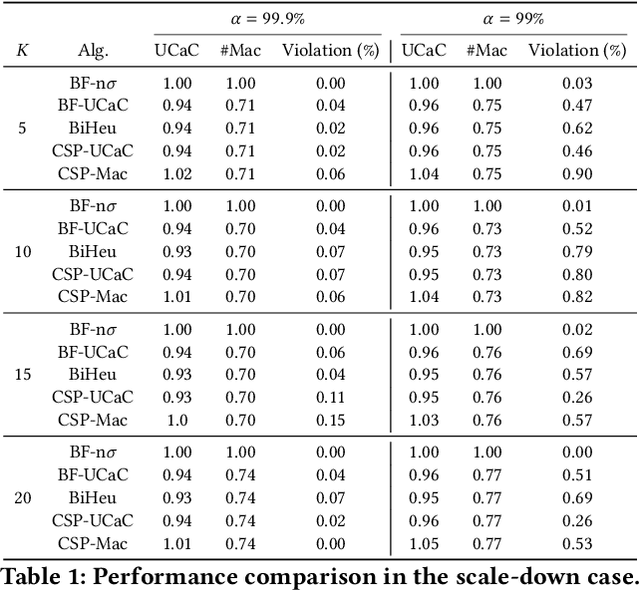
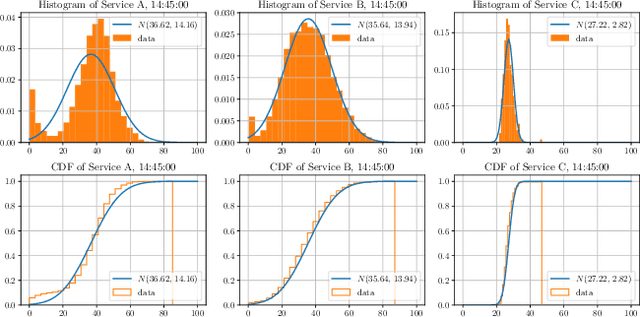
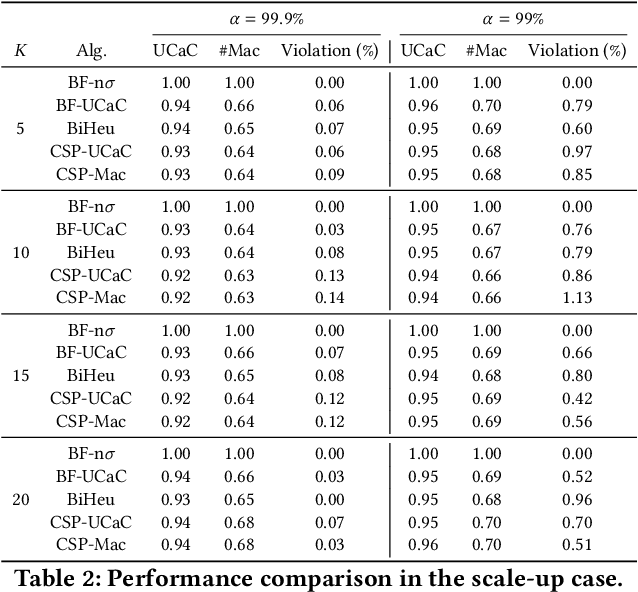
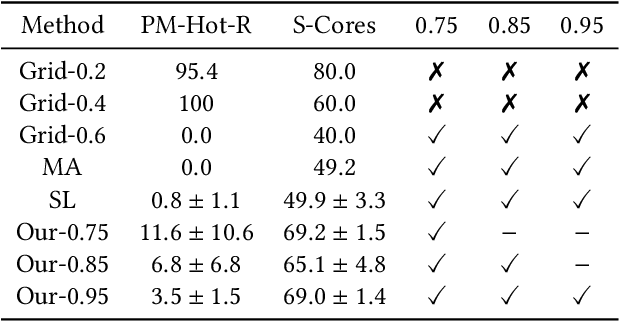
This paper investigates a critical resource allocation problem in the first party cloud: scheduling containers to machines. There are tens of services and each service runs a set of homogeneous containers with dynamic resource usage; containers of a service are scheduled daily in a batch fashion. This problem can be naturally formulated as Stochastic Bin Packing Problem (SBPP). However, traditional SBPP research often focuses on cases of empty machines, whose objective, i.e., to minimize the number of used machines, is not well-defined for the more common reality with nonempty machines. This paper aims to close this gap. First, we define a new objective metric, Used Capacity at Confidence (UCaC), which measures the maximum used resources at a probability and is proved to be consistent for both empty and nonempty machines, and reformulate the SBPP under chance constraints. Second, by modeling the container resource usage distribution in a generative approach, we reveal that UCaC can be approximated with Gaussian, which is verified by trace data of real-world applications. Third, we propose an exact solver by solving the equivalent cutting stock variant as well as two heuristics-based solvers -- UCaC best fit, bi-level heuristics. We experimentally evaluate these solvers on both synthetic datasets and real application traces, demonstrating our methodology's advantage over traditional SBPP optimal solver minimizing the number of used machines, with a low rate of resource violations.