 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWen-Huang Cheng
Lightweight Deep Learning for Resource-Constrained Environments: A Survey
Apr 12, 2024
Over the past decade, the dominance of deep learning has prevailed across various domains of artificial intelligence, including natural language processing, computer vision, and biomedical signal processing. While there have been remarkable improvements in model accuracy, deploying these models on lightweight devices, such as mobile phones and microcontrollers, is constrained by limited resources. In this survey, we provide comprehensive design guidance tailored for these devices, detailing the meticulous design of lightweight models, compression methods, and hardware acceleration strategies. The principal goal of this work is to explore methods and concepts for getting around hardware constraints without compromising the model's accuracy. Additionally, we explore two notable paths for lightweight deep learning in the future: deployment techniques for TinyML and Large Language Models. Although these paths undoubtedly have potential, they also present significant challenges, encouraging research into unexplored areas.
DQ-DETR: DETR with Dynamic Query for Tiny Object Detection
Apr 11, 2024Despite previous DETR-like methods having performed successfully in generic object detection, tiny object detection is still a challenging task for them since the positional information of object queries is not customized for detecting tiny objects, whose scale is extraordinarily smaller than general objects. Also, DETR-like methods using a fixed number of queries make them unsuitable for aerial datasets, which only contain tiny objects, and the numbers of instances are imbalanced between different images. Thus, we present a simple yet effective model, named DQ-DETR, which consists of three different components: categorical counting module, counting-guided feature enhancement, and dynamic query selection to solve the above-mentioned problems. DQ-DETR uses the prediction and density maps from the categorical counting module to dynamically adjust the number of object queries and improve the positional information of queries. Our model DQ-DETR outperforms previous CNN-based and DETR-like methods, achieving state-of-the-art mAP 30.2% on the AI-TOD-V2 dataset, which mostly consists of tiny objects.
MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
Apr 07, 2024Monocular 3D object detection (Mono3D) is an indispensable research topic in autonomous driving, thanks to the cost-effective monocular camera sensors and its wide range of applications. Since the image perspective has depth ambiguity, the challenges of Mono3D lie in understanding 3D scene geometry and reconstructing 3D object information from a single image. Previous methods attempted to transfer 3D information directly from the LiDAR-based teacher to the camera-based student. However, a considerable gap in feature representation makes direct cross-modal distillation inefficient, resulting in a significant performance deterioration between the LiDAR-based teacher and the camera-based student. To address this issue, we propose the Teaching Assistant Knowledge Distillation (MonoTAKD) to break down the learning objective by integrating intra-modal distillation with cross-modal residual distillation. In particular, we employ a strong camera-based teaching assistant model to distill powerful visual knowledge effectively through intra-modal distillation. Subsequently, we introduce the cross-modal residual distillation to transfer the 3D spatial cues. By acquiring both visual knowledge and 3D spatial cues, the predictions of our approach are rigorously evaluated on the KITTI 3D object detection benchmark and achieve state-of-the-art performance in Mono3D.
MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text
Jul 31, 2023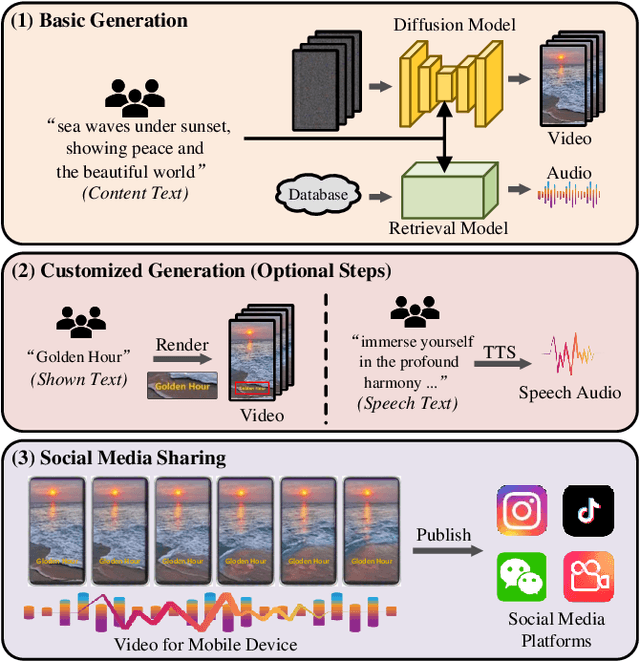

Videos for mobile devices become the most popular access to share and acquire information recently. For the convenience of users' creation, in this paper, we present a system, namely MobileVidFactory, to automatically generate vertical mobile videos where users only need to give simple texts mainly. Our system consists of two parts: basic and customized generation. In the basic generation, we take advantage of the pretrained image diffusion model, and adapt it to a high-quality open-domain vertical video generator for mobile devices. As for the audio, by retrieving from our big database, our system matches a suitable background sound for the video. Additionally to produce customized content, our system allows users to add specified screen texts to the video for enriching visual expression, and specify texts for automatic reading with optional voices as they like.
MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
Jun 12, 2023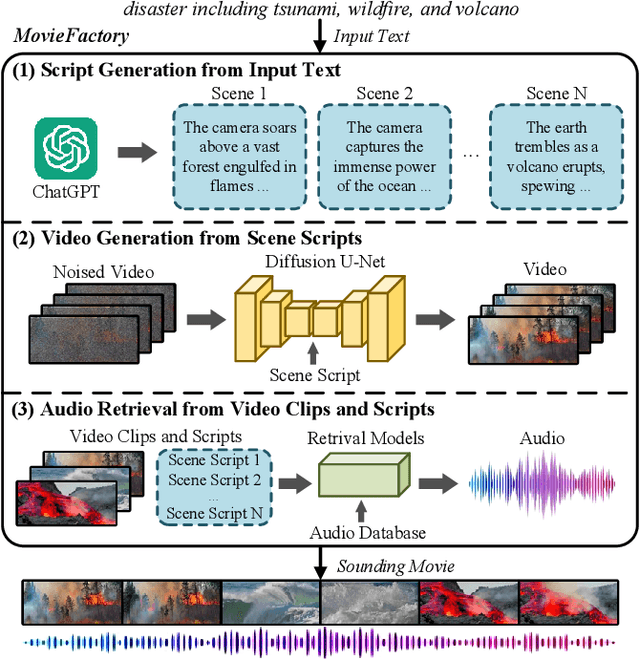

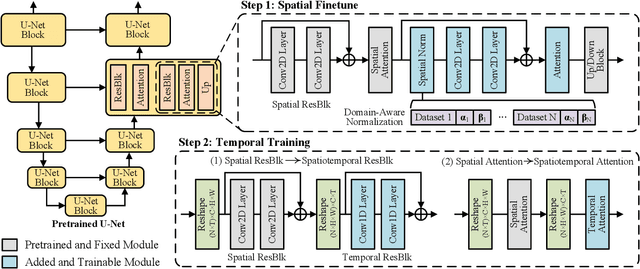
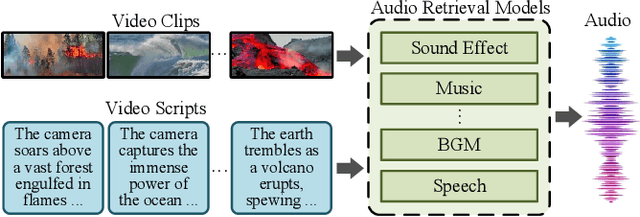
In this paper, we present MovieFactory, a powerful framework to generate cinematic-picture (3072$\times$1280), film-style (multi-scene), and multi-modality (sounding) movies on the demand of natural languages. As the first fully automated movie generation model to the best of our knowledge, our approach empowers users to create captivating movies with smooth transitions using simple text inputs, surpassing existing methods that produce soundless videos limited to a single scene of modest quality. To facilitate this distinctive functionality, we leverage ChatGPT to expand user-provided text into detailed sequential scripts for movie generation. Then we bring scripts to life visually and acoustically through vision generation and audio retrieval. To generate videos, we extend the capabilities of a pretrained text-to-image diffusion model through a two-stage process. Firstly, we employ spatial finetuning to bridge the gap between the pretrained image model and the new video dataset. Subsequently, we introduce temporal learning to capture object motion. In terms of audio, we leverage sophisticated retrieval models to select and align audio elements that correspond to the plot and visual content of the movie. Extensive experiments demonstrate that our MovieFactory produces movies with realistic visuals, diverse scenes, and seamlessly fitting audio, offering users a novel and immersive experience. Generated samples can be found in YouTube or Bilibili (1080P).
Dual-branch Cross-Patch Attention Learning for Group Affect Recognition
Dec 14, 2022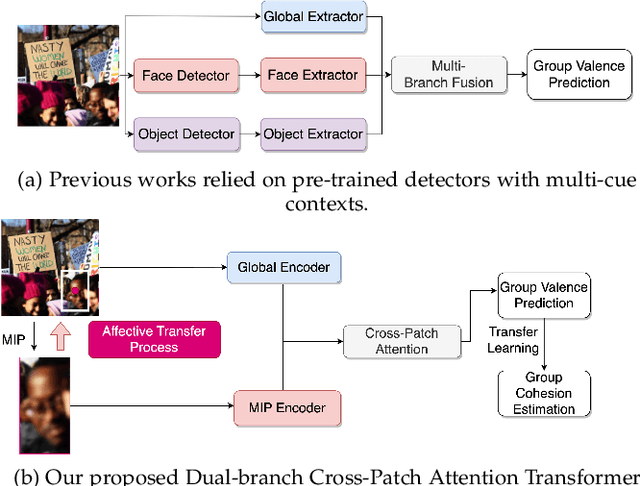
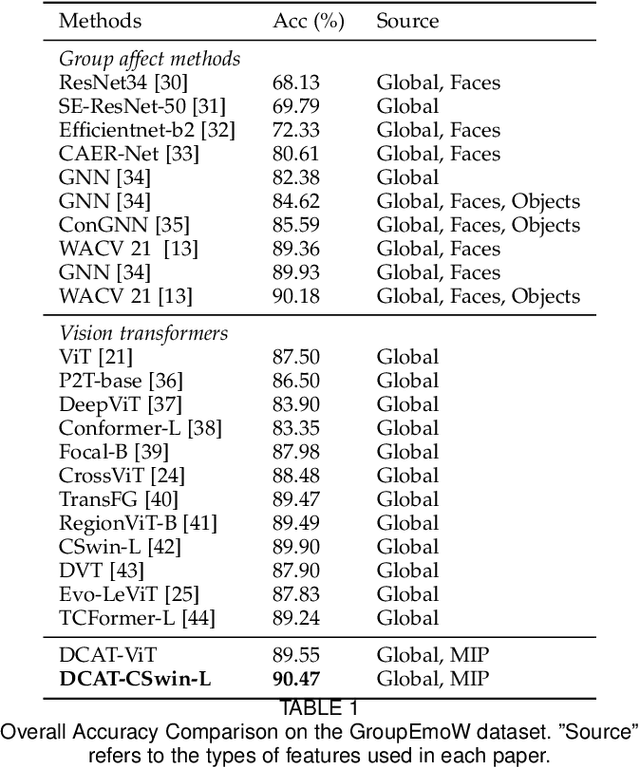

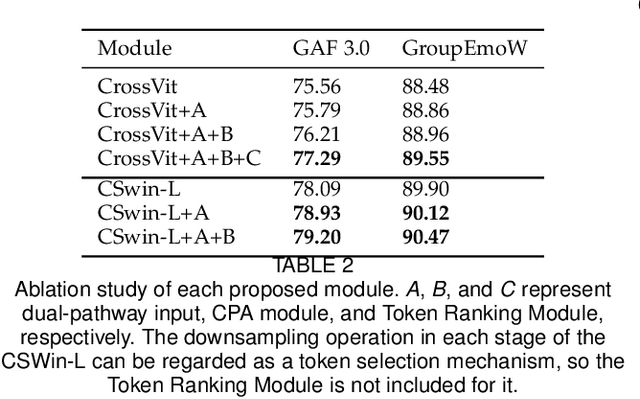
Group affect refers to the subjective emotion that is evoked by an external stimulus in a group, which is an important factor that shapes group behavior and outcomes. Recognizing group affect involves identifying important individuals and salient objects among a crowd that can evoke emotions. Most of the existing methods are proposed to detect faces and objects using pre-trained detectors and summarize the results into group emotions by specific rules. However, such affective region selection mechanisms are heuristic and susceptible to imperfect faces and objects from the pre-trained detectors. Moreover, faces and objects on group-level images are often contextually relevant. There is still an open question about how important faces and objects can be interacted with. In this work, we incorporate the psychological concept called Most Important Person (MIP). It represents the most noteworthy face in the crowd and has an affective semantic meaning. We propose the Dual-branch Cross-Patch Attention Transformer (DCAT) which uses global image and MIP together as inputs. Specifically, we first learn the informative facial regions produced by the MIP and the global context separately. Then, the Cross-Patch Attention module is proposed to fuse the features of MIP and global context together to complement each other. With parameters less than 10x, the proposed DCAT outperforms state-of-the-art methods on two datasets of group valence prediction, GAF 3.0 and GroupEmoW datasets. Moreover, our proposed model can be transferred to another group affect task, group cohesion, and shows comparable results.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
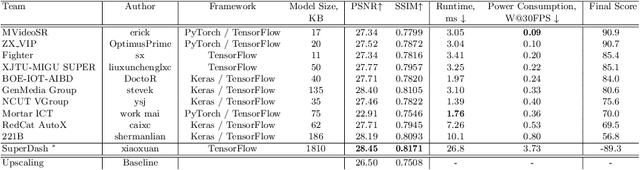
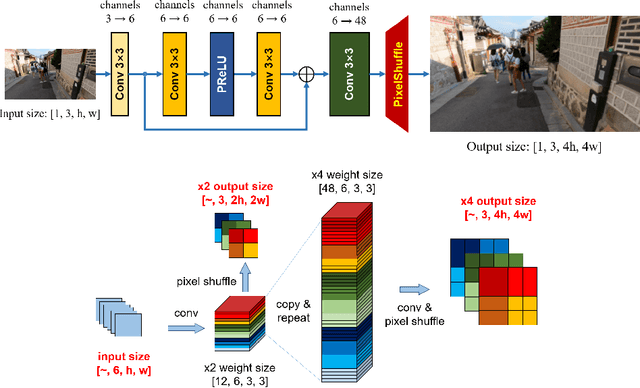
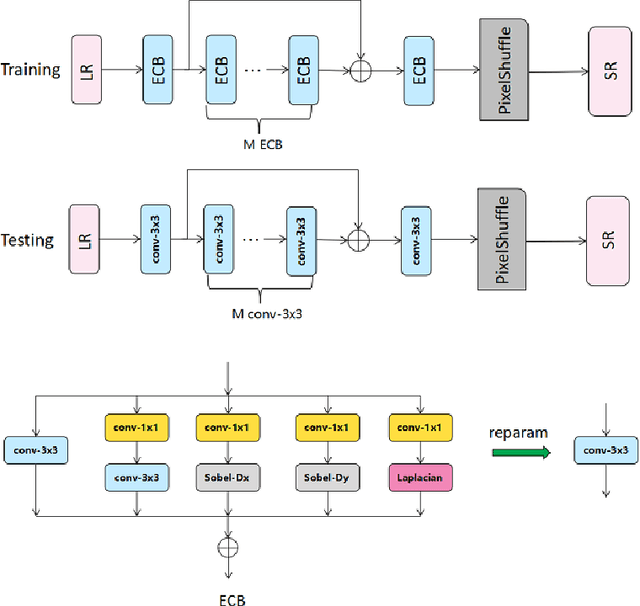
Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Fast Vehicle Detection and Tracking on Fisheye Traffic Monitoring Video using CNN and Bounding Box Propagation
Jul 13, 2022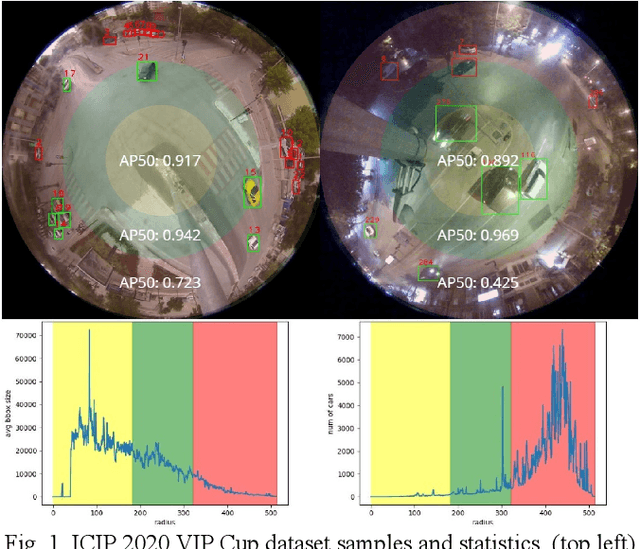

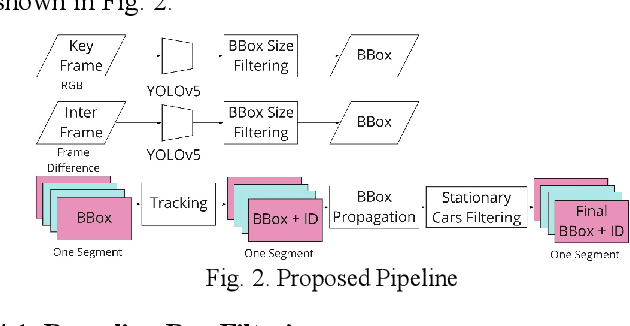
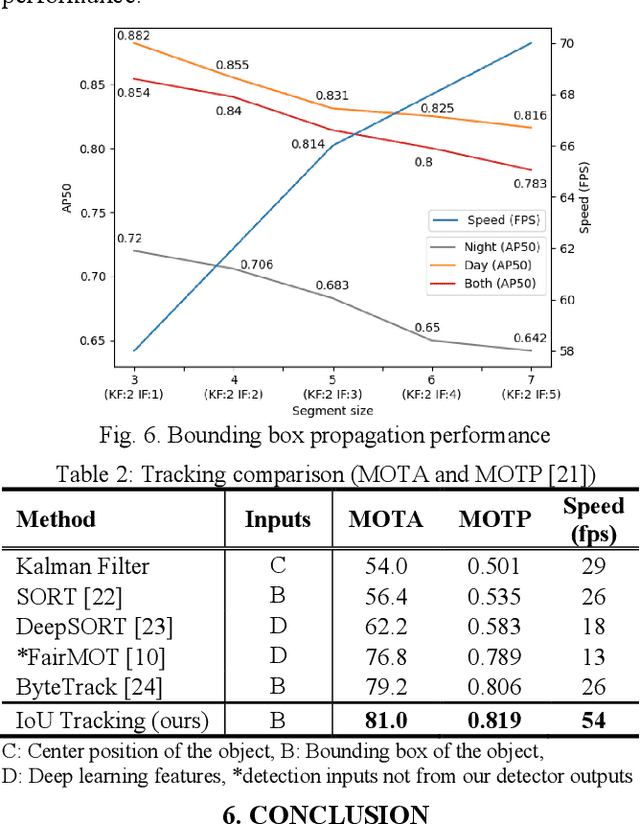
We design a fast car detection and tracking algorithm for traffic monitoring fisheye video mounted on crossroads. We use ICIP 2020 VIP Cup dataset and adopt YOLOv5 as the object detection base model. The nighttime video of this dataset is very challenging, and the detection accuracy (AP50) of the base model is about 54%. We design a reliable car detection and tracking algorithm based on the concept of bounding box propagation among frames, which provides 17.9 percentage points (pp) and 6.2 pp. accuracy improvement over the base model for the nighttime and daytime videos, respectively. To speed up, the grayscale frame difference is used for the intermediate frames in a segment, which can double the processing speed.
Vision Transformers: State of the Art and Research Challenges
Jul 07, 2022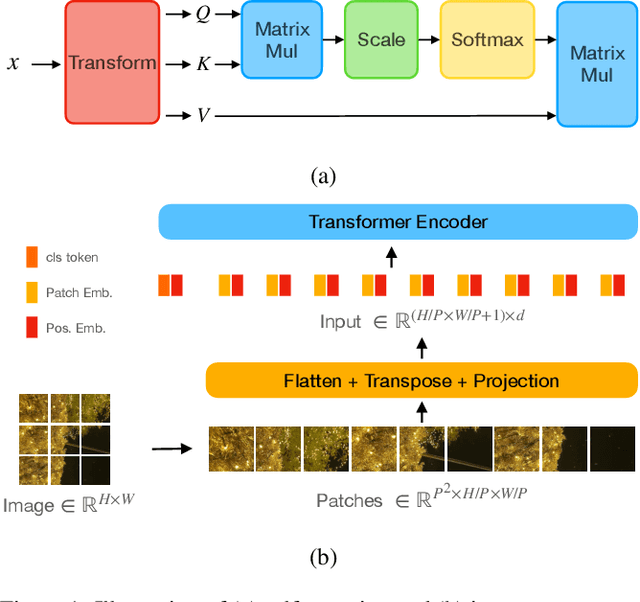
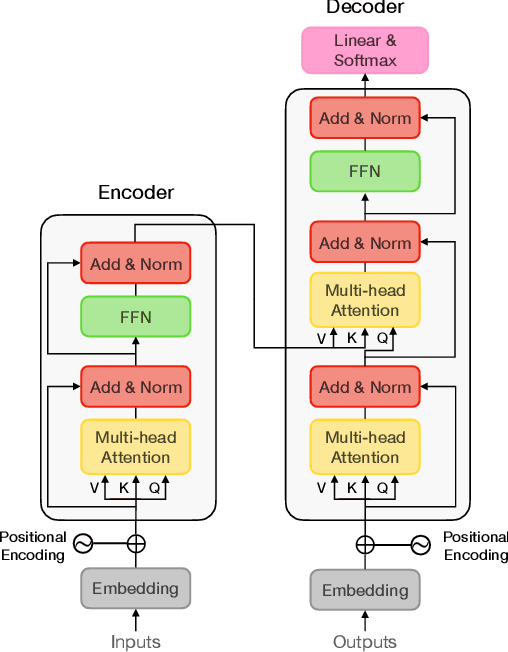
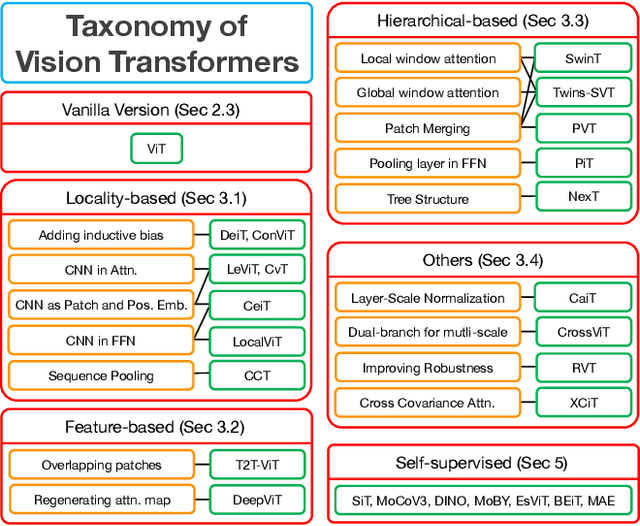
Transformers have achieved great success in natural language processing. Due to the powerful capability of self-attention mechanism in transformers, researchers develop the vision transformers for a variety of computer vision tasks, such as image recognition, object detection, image segmentation, pose estimation, and 3D reconstruction. This paper presents a comprehensive overview of the literature on different architecture designs and training tricks (including self-supervised learning) for vision transformers. Our goal is to provide a systematic review with the open research opportunities.