 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbdul Qayyum
A Robust Ensemble Algorithm for Ischemic Stroke Lesion Segmentation: Generalizability and Clinical Utility Beyond the ISLES Challenge
Apr 03, 2024
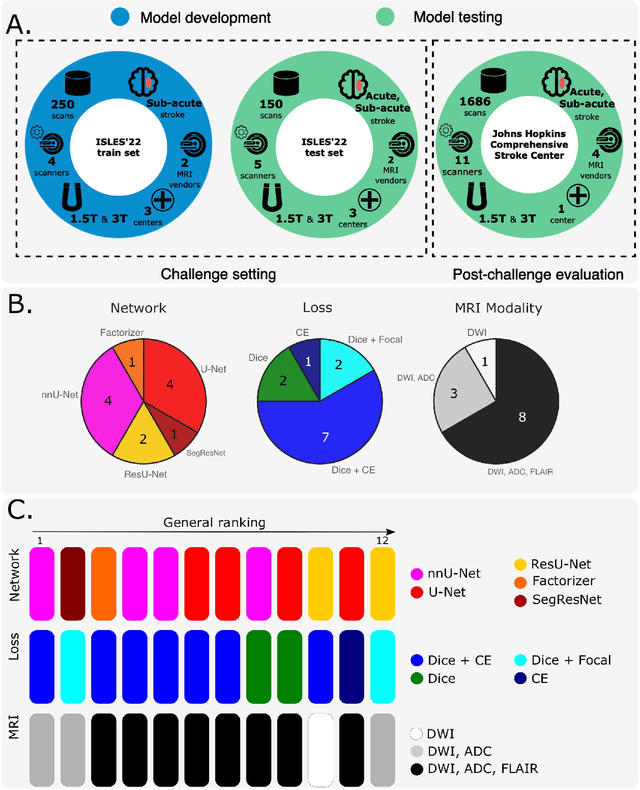
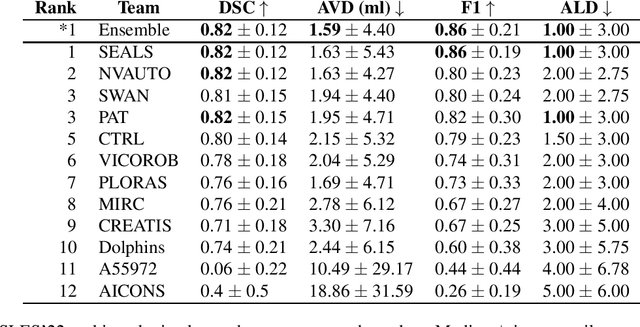
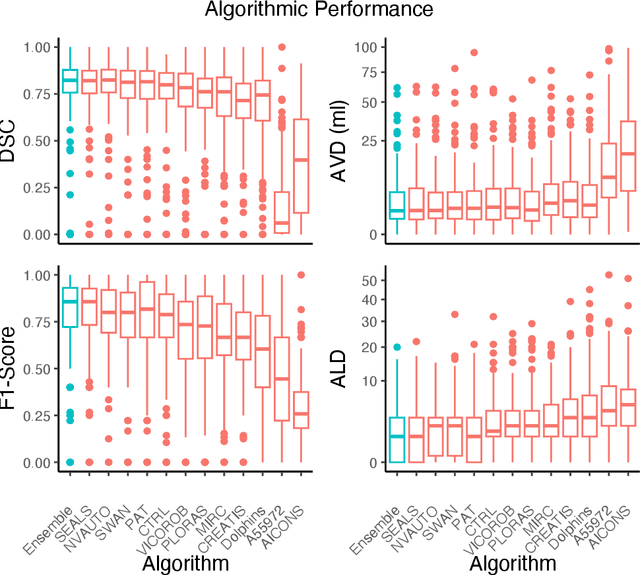
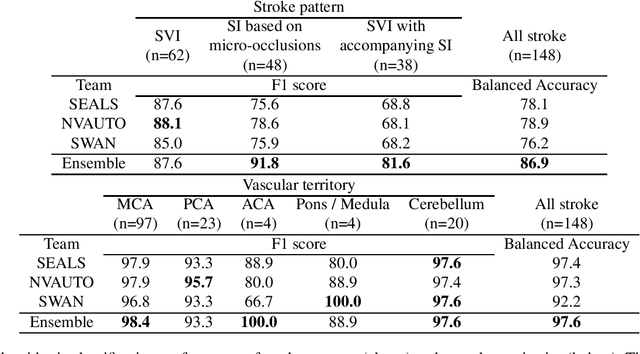
Diffusion-weighted MRI (DWI) is essential for stroke diagnosis, treatment decisions, and prognosis. However, image and disease variability hinder the development of generalizable AI algorithms with clinical value. We address this gap by presenting a novel ensemble algorithm derived from the 2022 Ischemic Stroke Lesion Segmentation (ISLES) challenge. ISLES'22 provided 400 patient scans with ischemic stroke from various medical centers, facilitating the development of a wide range of cutting-edge segmentation algorithms by the research community. Through collaboration with leading teams, we combined top-performing algorithms into an ensemble model that overcomes the limitations of individual solutions. Our ensemble model achieved superior ischemic lesion detection and segmentation accuracy on our internal test set compared to individual algorithms. This accuracy generalized well across diverse image and disease variables. Furthermore, the model excelled in extracting clinical biomarkers. Notably, in a Turing-like test, neuroradiologists consistently preferred the algorithm's segmentations over manual expert efforts, highlighting increased comprehensiveness and precision. Validation using a real-world external dataset (N=1686) confirmed the model's generalizability. The algorithm's outputs also demonstrated strong correlations with clinical scores (admission NIHSS and 90-day mRS) on par with or exceeding expert-derived results, underlining its clinical relevance. This study offers two key findings. First, we present an ensemble algorithm (https://github.com/Tabrisrei/ISLES22_Ensemble) that detects and segments ischemic stroke lesions on DWI across diverse scenarios on par with expert (neuro)radiologists. Second, we show the potential for biomedical challenge outputs to extend beyond the challenge's initial objectives, demonstrating their real-world clinical applicability.
Multi-Center Fetal Brain Tissue Annotation (FeTA) Challenge 2022 Results
Feb 08, 2024Segmentation is a critical step in analyzing the developing human fetal brain. There have been vast improvements in automatic segmentation methods in the past several years, and the Fetal Brain Tissue Annotation (FeTA) Challenge 2021 helped to establish an excellent standard of fetal brain segmentation. However, FeTA 2021 was a single center study, and the generalizability of algorithms across different imaging centers remains unsolved, limiting real-world clinical applicability. The multi-center FeTA Challenge 2022 focuses on advancing the generalizability of fetal brain segmentation algorithms for magnetic resonance imaging (MRI). In FeTA 2022, the training dataset contained images and corresponding manually annotated multi-class labels from two imaging centers, and the testing data contained images from these two imaging centers as well as two additional unseen centers. The data from different centers varied in many aspects, including scanners used, imaging parameters, and fetal brain super-resolution algorithms applied. 16 teams participated in the challenge, and 17 algorithms were evaluated. Here, a detailed overview and analysis of the challenge results are provided, focusing on the generalizability of the submissions. Both in- and out of domain, the white matter and ventricles were segmented with the highest accuracy, while the most challenging structure remains the cerebral cortex due to anatomical complexity. The FeTA Challenge 2022 was able to successfully evaluate and advance generalizability of multi-class fetal brain tissue segmentation algorithms for MRI and it continues to benchmark new algorithms. The resulting new methods contribute to improving the analysis of brain development in utero.
Multi-site, Multi-domain Airway Tree Modeling (ATM'22): A Public Benchmark for Pulmonary Airway Segmentation
Mar 10, 2023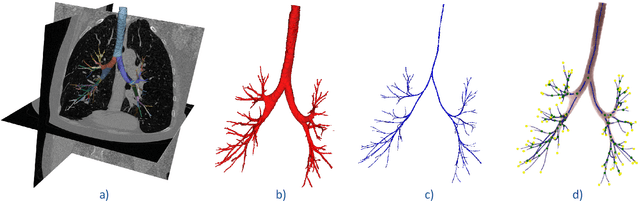

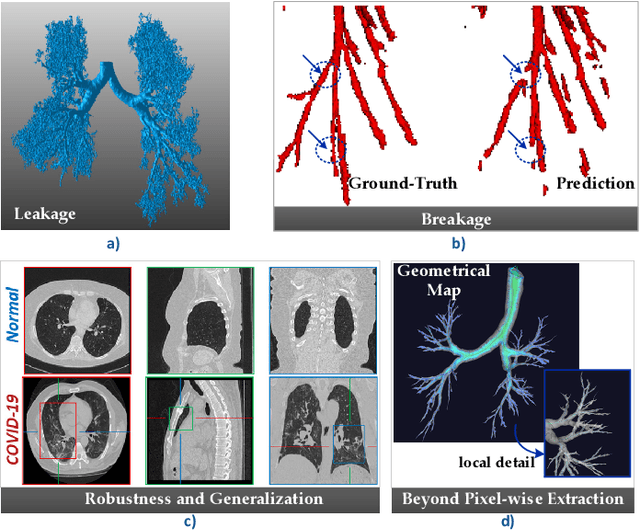

Open international challenges are becoming the de facto standard for assessing computer vision and image analysis algorithms. In recent years, new methods have extended the reach of pulmonary airway segmentation that is closer to the limit of image resolution. Since EXACT'09 pulmonary airway segmentation, limited effort has been directed to quantitative comparison of newly emerged algorithms driven by the maturity of deep learning based approaches and clinical drive for resolving finer details of distal airways for early intervention of pulmonary diseases. Thus far, public annotated datasets are extremely limited, hindering the development of data-driven methods and detailed performance evaluation of new algorithms. To provide a benchmark for the medical imaging community, we organized the Multi-site, Multi-domain Airway Tree Modeling (ATM'22), which was held as an official challenge event during the MICCAI 2022 conference. ATM'22 provides large-scale CT scans with detailed pulmonary airway annotation, including 500 CT scans (300 for training, 50 for validation, and 150 for testing). The dataset was collected from different sites and it further included a portion of noisy COVID-19 CTs with ground-glass opacity and consolidation. Twenty-three teams participated in the entire phase of the challenge and the algorithms for the top ten teams are reviewed in this paper. Quantitative and qualitative results revealed that deep learning models embedded with the topological continuity enhancement achieved superior performance in general. ATM'22 challenge holds as an open-call design, the training data and the gold standard evaluation are available upon successful registration via its homepage.
AIROGS: Artificial Intelligence for RObust Glaucoma Screening Challenge
Feb 10, 2023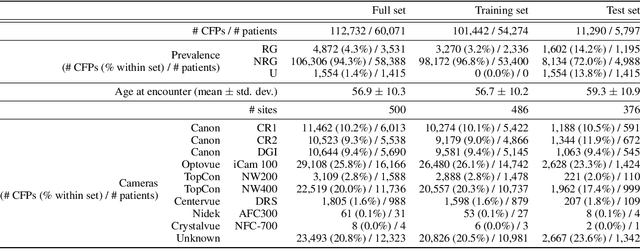
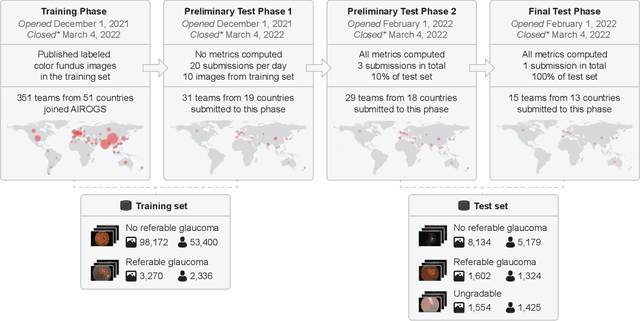
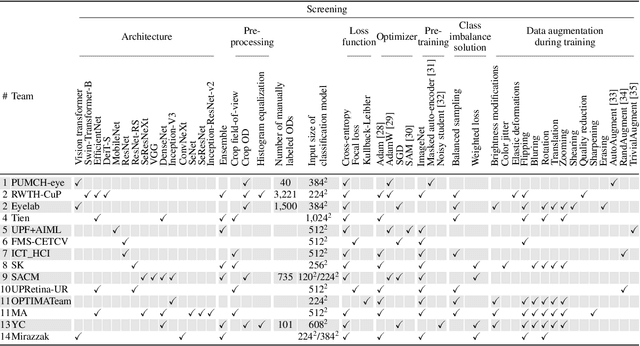
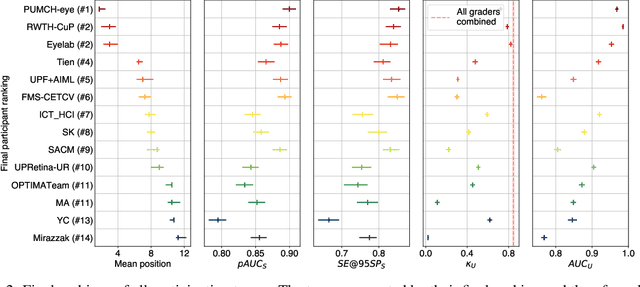
The early detection of glaucoma is essential in preventing visual impairment. Artificial intelligence (AI) can be used to analyze color fundus photographs (CFPs) in a cost-effective manner, making glaucoma screening more accessible. While AI models for glaucoma screening from CFPs have shown promising results in laboratory settings, their performance decreases significantly in real-world scenarios due to the presence of out-of-distribution and low-quality images. To address this issue, we propose the Artificial Intelligence for Robust Glaucoma Screening (AIROGS) challenge. This challenge includes a large dataset of around 113,000 images from about 60,000 patients and 500 different screening centers, and encourages the development of algorithms that are robust to ungradable and unexpected input data. We evaluated solutions from 14 teams in this paper, and found that the best teams performed similarly to a set of 20 expert ophthalmologists and optometrists. The highest-scoring team achieved an area under the receiver operating characteristic curve of 0.99 (95% CI: 0.98-0.99) for detecting ungradable images on-the-fly. Additionally, many of the algorithms showed robust performance when tested on three other publicly available datasets. These results demonstrate the feasibility of robust AI-enabled glaucoma screening.
The state-of-the-art 3D anisotropic intracranial hemorrhage segmentation on non-contrast head CT: The INSTANCE challenge
Jan 12, 2023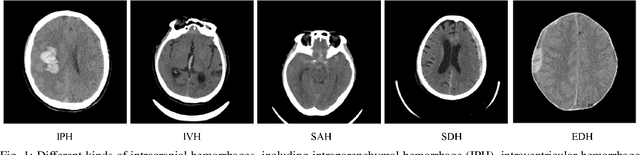

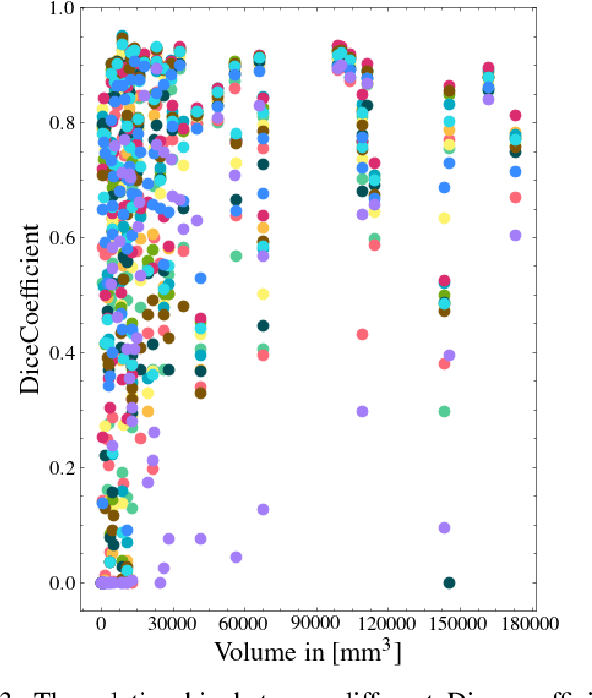
Automatic intracranial hemorrhage segmentation in 3D non-contrast head CT (NCCT) scans is significant in clinical practice. Existing hemorrhage segmentation methods usually ignores the anisotropic nature of the NCCT, and are evaluated on different in-house datasets with distinct metrics, making it highly challenging to improve segmentation performance and perform objective comparisons among different methods. The INSTANCE 2022 was a grand challenge held in conjunction with the 2022 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). It is intended to resolve the above-mentioned problems and promote the development of both intracranial hemorrhage segmentation and anisotropic data processing. The INSTANCE released a training set of 100 cases with ground-truth and a validation set with 30 cases without ground-truth labels that were available to the participants. A held-out testing set with 70 cases is utilized for the final evaluation and ranking. The methods from different participants are ranked based on four metrics, including Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), Relative Volume Difference (RVD) and Normalized Surface Dice (NSD). A total of 13 teams submitted distinct solutions to resolve the challenges, making several baseline models, pre-processing strategies and anisotropic data processing techniques available to future researchers. The winner method achieved an average DSC of 0.6925, demonstrating a significant growth over our proposed baseline method. To the best of our knowledge, the proposed INSTANCE challenge releases the first intracranial hemorrhage segmentation benchmark, and is also the first challenge that intended to resolve the anisotropic problem in 3D medical image segmentation, which provides new alternatives in these research fields.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy
Jun 30, 2022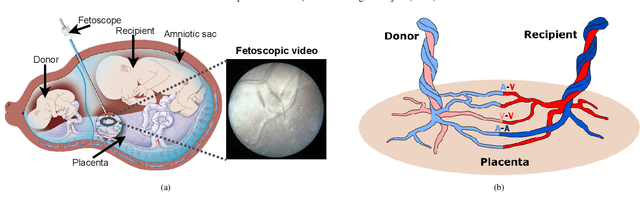
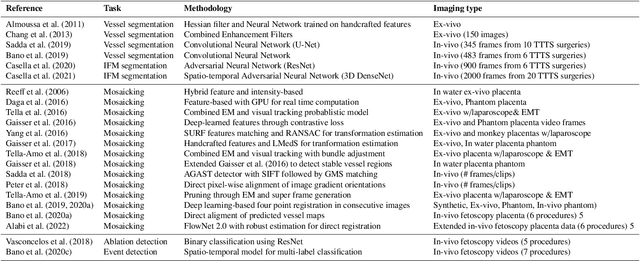
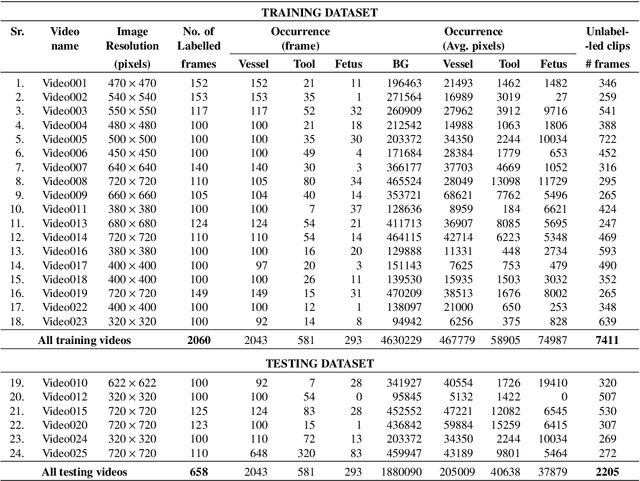
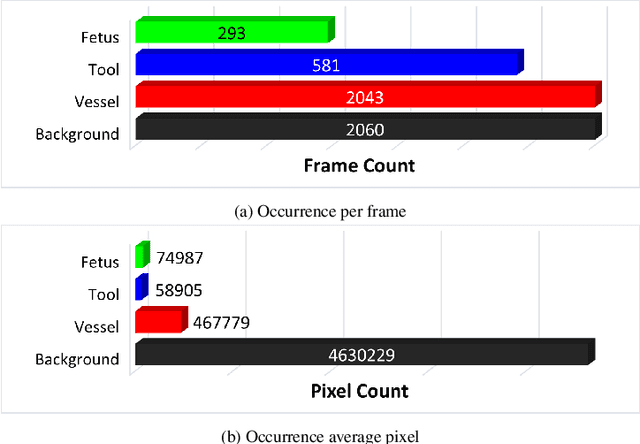
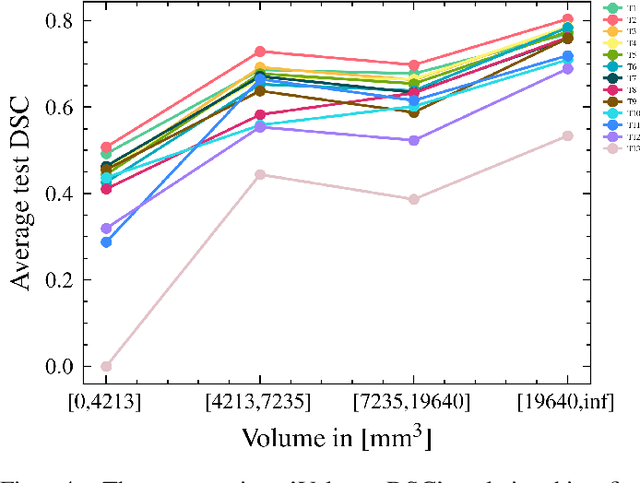
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to regulate blood exchange among twins. The procedure is particularly challenging due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation. Computer-assisted intervention (CAI) can provide surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision challenge, we released the first largescale multicentre TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. The challenge provided an opportunity for creating generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-centre fetoscopic data, we provide a benchmark for future research in this field.
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022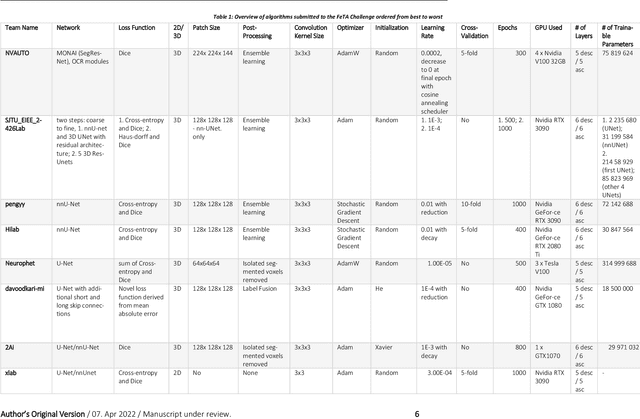
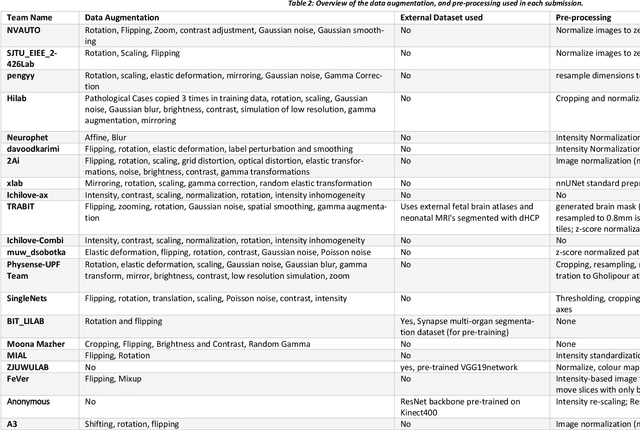
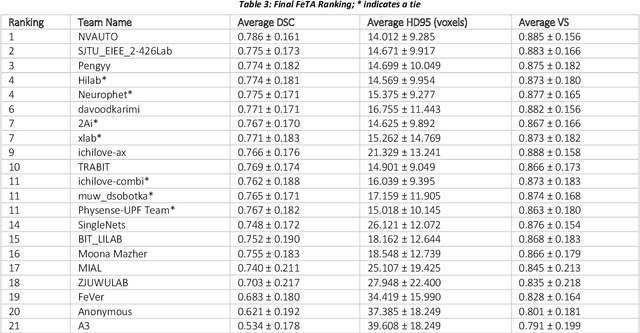
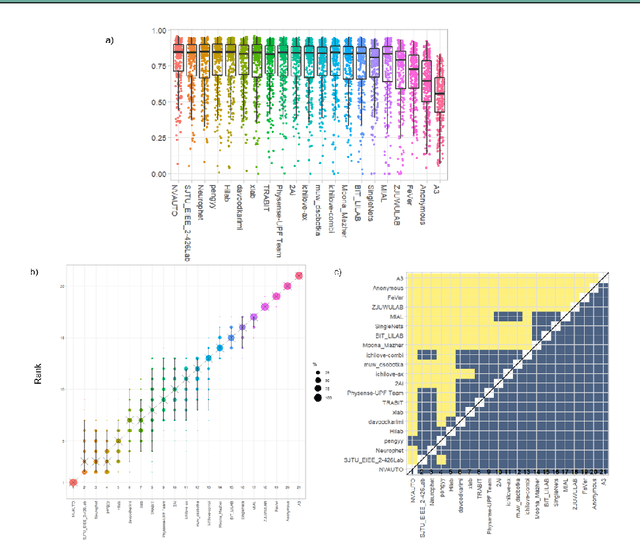
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.
Deep Learning methods for automatic evaluation of delayed enhancement-MRI. The results of the EMIDEC challenge
Aug 10, 2021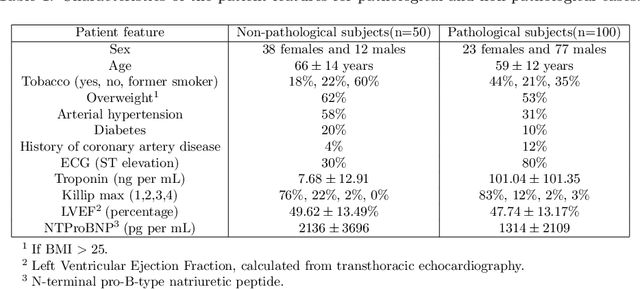
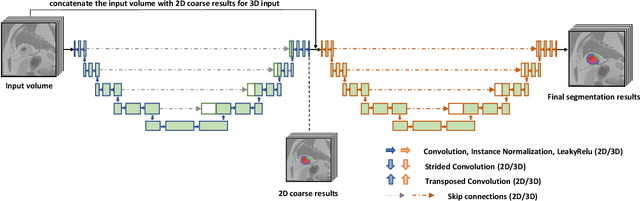

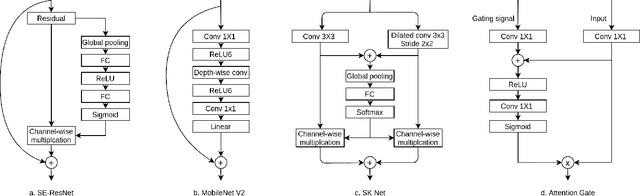
A key factor for assessing the state of the heart after myocardial infarction (MI) is to measure whether the myocardium segment is viable after reperfusion or revascularization therapy. Delayed enhancement-MRI or DE-MRI, which is performed several minutes after injection of the contrast agent, provides high contrast between viable and nonviable myocardium and is therefore a method of choice to evaluate the extent of MI. To automatically assess myocardial status, the results of the EMIDEC challenge that focused on this task are presented in this paper. The challenge's main objectives were twofold. First, to evaluate if deep learning methods can distinguish between normal and pathological cases. Second, to automatically calculate the extent of myocardial infarction. The publicly available database consists of 150 exams divided into 50 cases with normal MRI after injection of a contrast agent and 100 cases with myocardial infarction (and then with a hyperenhanced area on DE-MRI), whatever their inclusion in the cardiac emergency department. Along with MRI, clinical characteristics are also provided. The obtained results issued from several works show that the automatic classification of an exam is a reachable task (the best method providing an accuracy of 0.92), and the automatic segmentation of the myocardium is possible. However, the segmentation of the diseased area needs to be improved, mainly due to the small size of these areas and the lack of contrast with the surrounding structures.
Segmentation of the Myocardium on Late-Gadolinium Enhanced MRI based on 2.5 D Residual Squeeze and Excitation Deep Learning Model
May 27, 2020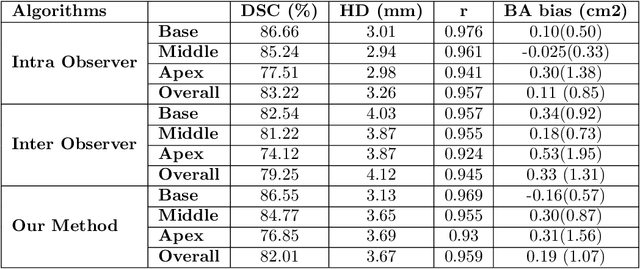
Cardiac left ventricular (LV) segmentation from short-axis MRI acquired 10 minutes after the injection of a contrast agent (LGE-MRI) is a necessary step in the processing allowing the identification and diagnosis of cardiac diseases such as myocardial infarction. However, this segmentation is challenging due to high variability across subjects and the potential lack of contrast between structures. Then, the main objective of this work is to develop an accurate automatic segmentation method based on deep learning models for the myocardial borders on LGE-MRI. To this end, 2.5 D residual neural network integrated with a squeeze and excitation blocks in encoder side with specialized convolutional has been proposed. Late fusion has been used to merge the output of the best trained proposed models from a different set of hyperparameters. A total number of 320 exams (with a mean number of 6 slices per exam) were used for training and 28 exams used for testing. The performance analysis of the proposed ensemble model in the basal and middle slices was similar as compared to intra-observer study and slightly lower at apical slices. The overall Dice score was 82.01% by our proposed method as compared to Dice score of 83.22% obtained from the intra observer study. The proposed model could be used for the automatic segmentation of myocardial border that is a very important step for accurate quantification of no-reflow, myocardial infarction, myocarditis, and hypertrophic cardiomyopathy, among others.