 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenhao Zhang
ExcluIR: Exclusionary Neural Information Retrieval
Apr 26, 2024
Exclusion is an important and universal linguistic skill that humans use to express what they do not want. However, in information retrieval community, there is little research on exclusionary retrieval, where users express what they do not want in their queries. In this work, we investigate the scenario of exclusionary retrieval in document retrieval for the first time. We present ExcluIR, a set of resources for exclusionary retrieval, consisting of an evaluation benchmark and a training set for helping retrieval models to comprehend exclusionary queries. The evaluation benchmark includes 3,452 high-quality exclusionary queries, each of which has been manually annotated. The training set contains 70,293 exclusionary queries, each paired with a positive document and a negative document. We conduct detailed experiments and analyses, obtaining three main observations: (1) Existing retrieval models with different architectures struggle to effectively comprehend exclusionary queries; (2) Although integrating our training data can improve the performance of retrieval models on exclusionary retrieval, there still exists a gap compared to human performance; (3) Generative retrieval models have a natural advantage in handling exclusionary queries. To facilitate future research on exclusionary retrieval, we share the benchmark and evaluation scripts on \url{https://github.com/zwh-sdu/ExcluIR}.
MTGA: Multi-view Temporal Granularity aligned Aggregation for Event-based Lip-reading
Apr 18, 2024Lip-reading is to utilize the visual information of the speaker's lip movements to recognize words and sentences. Existing event-based lip-reading solutions integrate different frame rate branches to learn spatio-temporal features of varying granularities. However, aggregating events into event frames inevitably leads to the loss of fine-grained temporal information within frames. To remedy this drawback, we propose a novel framework termed Multi-view Temporal Granularity aligned Aggregation (MTGA). Specifically, we first present a novel event representation method, namely time-segmented voxel graph list, where the most significant local voxels are temporally connected into a graph list. Then we design a spatio-temporal fusion module based on temporal granularity alignment, where the global spatial features extracted from event frames, together with the local relative spatial and temporal features contained in voxel graph list are effectively aligned and integrated. Finally, we design a temporal aggregation module that incorporates positional encoding, which enables the capture of local absolute spatial and global temporal information. Experiments demonstrate that our method outperforms both the event-based and video-based lip-reading counterparts. Our code will be publicly available.
Aligning Individual and Collective Objectives in Multi-Agent Cooperation
Feb 19, 2024In the field of multi-agent learning, the challenge of mixed-motive cooperation is pronounced, given the inherent contradictions between individual and collective goals. Current research in this domain primarily focuses on incorporating domain knowledge into rewards or introducing additional mechanisms to foster cooperation. However, many of these methods suffer from the drawbacks of manual design costs and the lack of a theoretical grounding convergence procedure to the solution. To address this gap, we approach the mixed-motive game by modeling it as a differentiable game to study learning dynamics. We introduce a novel optimization method named Altruistic Gradient Adjustment (AgA) that employs gradient adjustments to novelly align individual and collective objectives. Furthermore, we provide theoretical proof that the selection of an appropriate alignment weight in AgA can accelerate convergence towards the desired solutions while effectively avoiding the undesired ones. The visualization of learning dynamics effectively demonstrates that AgA successfully achieves alignment between individual and collective objectives. Additionally, through evaluations conducted on established mixed-motive benchmarks such as the public good game, Cleanup, Harvest, and our modified mixed-motive SMAC environment, we validate AgA's capability to facilitate altruistic and fair collaboration.
Multi-Center Fetal Brain Tissue Annotation (FeTA) Challenge 2022 Results
Feb 08, 2024Segmentation is a critical step in analyzing the developing human fetal brain. There have been vast improvements in automatic segmentation methods in the past several years, and the Fetal Brain Tissue Annotation (FeTA) Challenge 2021 helped to establish an excellent standard of fetal brain segmentation. However, FeTA 2021 was a single center study, and the generalizability of algorithms across different imaging centers remains unsolved, limiting real-world clinical applicability. The multi-center FeTA Challenge 2022 focuses on advancing the generalizability of fetal brain segmentation algorithms for magnetic resonance imaging (MRI). In FeTA 2022, the training dataset contained images and corresponding manually annotated multi-class labels from two imaging centers, and the testing data contained images from these two imaging centers as well as two additional unseen centers. The data from different centers varied in many aspects, including scanners used, imaging parameters, and fetal brain super-resolution algorithms applied. 16 teams participated in the challenge, and 17 algorithms were evaluated. Here, a detailed overview and analysis of the challenge results are provided, focusing on the generalizability of the submissions. Both in- and out of domain, the white matter and ventricles were segmented with the highest accuracy, while the most challenging structure remains the cerebral cortex due to anatomical complexity. The FeTA Challenge 2022 was able to successfully evaluate and advance generalizability of multi-class fetal brain tissue segmentation algorithms for MRI and it continues to benchmark new algorithms. The resulting new methods contribute to improving the analysis of brain development in utero.
Transferring Modality-Aware Pedestrian Attentive Learning for Visible-Infrared Person Re-identification
Dec 19, 2023Visible-infrared person re-identification (VI-ReID) aims to search the same pedestrian of interest across visible and infrared modalities. Existing models mainly focus on compensating for modality-specific information to reduce modality variation. However, these methods often lead to a higher computational overhead and may introduce interfering information when generating the corresponding images or features. To address this issue, it is critical to leverage pedestrian-attentive features and learn modality-complete and -consistent representation. In this paper, a novel Transferring Modality-Aware Pedestrian Attentive Learning (TMPA) model is proposed, focusing on the pedestrian regions to efficiently compensate for missing modality-specific features. Specifically, we propose a region-based data augmentation module PedMix to enhance pedestrian region coherence by mixing the corresponding regions from different modalities. A lightweight hybrid compensation module, i.e., the Modality Feature Transfer (MFT), is devised to integrate cross attention and convolution networks to fully explore the discriminative modality-complete features with minimal computational overhead. Extensive experiments conducted on the benchmark SYSU-MM01 and RegDB datasets demonstrated the effectiveness of our proposed TMPA model.
Quantifying Zero-shot Coordination Capability with Behavior Preferring Partners
Oct 08, 2023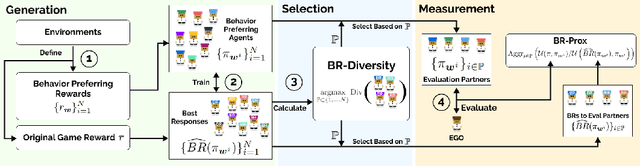
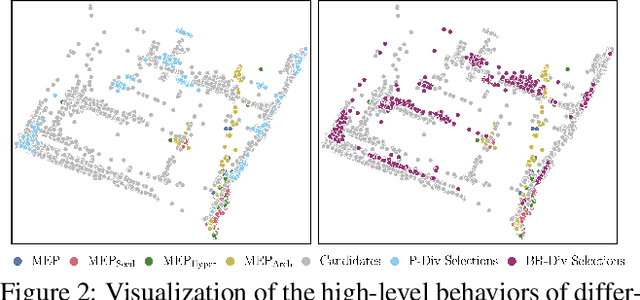
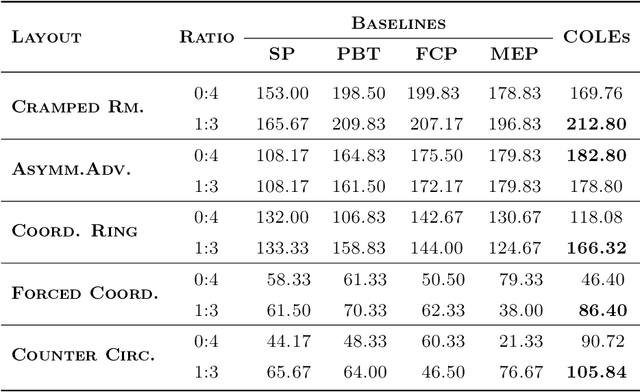
Zero-shot coordination (ZSC) is a new challenge focusing on generalizing learned coordination skills to unseen partners. Existing methods train the ego agent with partners from pre-trained or evolving populations. The agent's ZSC capability is typically evaluated with a few evaluation partners, including human and agent, and reported by mean returns. Current evaluation methods for ZSC capability still need to improve in constructing diverse evaluation partners and comprehensively measuring the ZSC capability. We aim to create a reliable, comprehensive, and efficient evaluation method for ZSC capability. We formally define the ideal 'diversity-complete' evaluation partners and propose the best response (BR) diversity, which is the population diversity of the BRs to the partners, to approximate the ideal evaluation partners. We propose an evaluation workflow including 'diversity-complete' evaluation partners construction and a multi-dimensional metric, the Best Response Proximity (BR-Prox) metric. BR-Prox quantifies the ZSC capability as the performance similarity to each evaluation partner's approximate best response, demonstrating generalization capability and improvement potential. We re-evaluate strong ZSC methods in the Overcooked environment using the proposed evaluation workflow. Surprisingly, the results in some of the most used layouts fail to distinguish the performance of different ZSC methods. Moreover, the evaluated ZSC methods must produce more diverse and high-performing training partners. Our proposed evaluation workflow calls for a change in how we efficiently evaluate ZSC methods as a supplement to human evaluation.
Tackling Cooperative Incompatibility for Zero-Shot Human-AI Coordination
Jun 05, 2023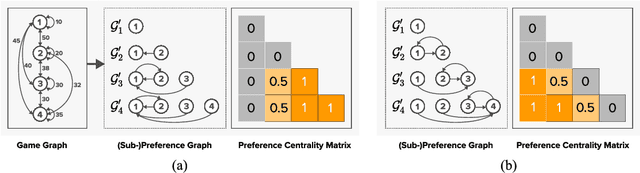
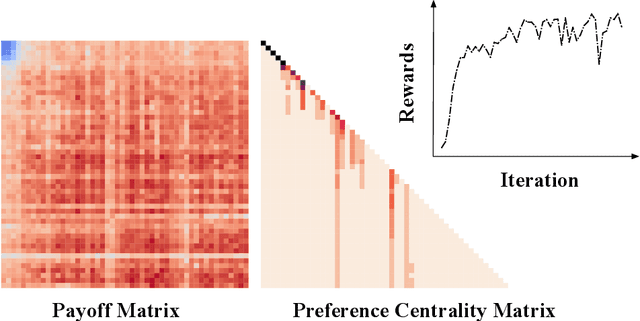
Achieving coordination between humans and artificial intelligence in scenarios involving previously unencountered humans remains a substantial obstacle within Zero-Shot Human-AI Coordination, which aims to develop AI agents capable of efficiently working alongside previously unknown human teammates. Traditional algorithms have aimed to collaborate with humans by optimizing fixed objectives within a population, fostering diversity in strategies and behaviors. However, these techniques may lead to learning loss and an inability to cooperate with specific strategies within the population, a phenomenon named cooperative incompatibility. To mitigate this issue, we introduce the Cooperative Open-ended LEarning (COLE) framework, which formulates open-ended objectives in cooperative games with two players using perspectives of graph theory to evaluate and pinpoint the cooperative capacity of each strategy. We put forth a practical algorithm incorporating insights from game theory and graph theory, e.g., Shapley Value and Centrality. We also show that COLE could effectively overcome the cooperative incompatibility from theoretical and empirical analysis. Subsequently, we created an online Overcooked human-AI experiment platform, the COLE platform, which enables easy customization of questionnaires, model weights, and other aspects. Utilizing the COLE platform, we enlist 130 participants for human experiments. Our findings reveal a preference for our approach over state-of-the-art methods using a variety of subjective metrics. Moreover, objective experimental outcomes in the Overcooked game environment indicate that our method surpasses existing ones when coordinating with previously unencountered AI agents and the human proxy model. Our code and demo are publicly available at https://sites.google.com/view/cole-2023.
Covert Communication in Hybrid Microwave/mmWave A2G Systems with Transmission Mode Selection
Feb 01, 2023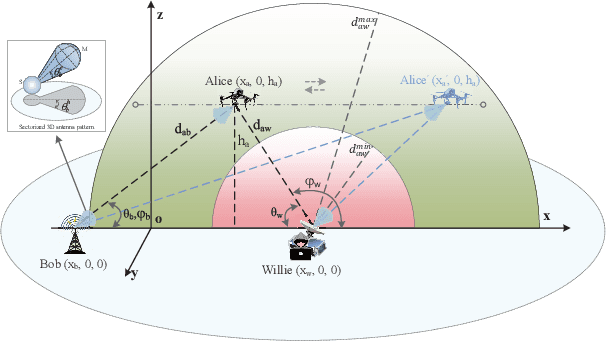
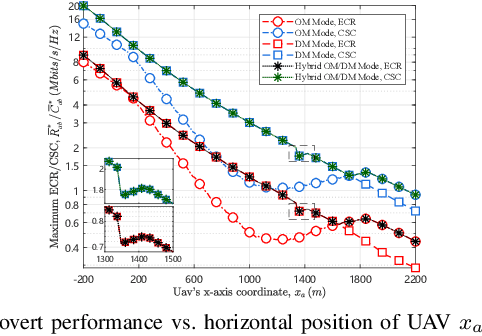
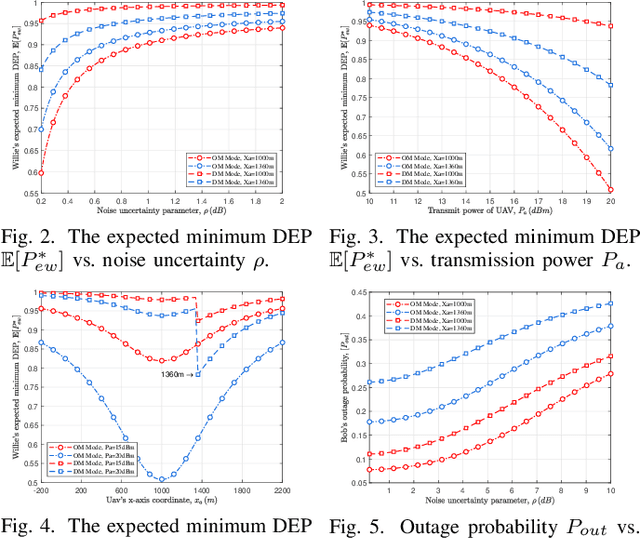
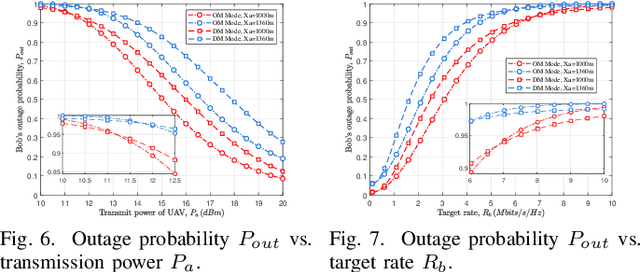
This paper investigates the covert communication in an air-to-ground (A2G) system, where a UAV (Alice) can adopt the omnidirectional microwave (OM) or directional mmWave (DM) transmission mode to transmit covert data to a ground user (Bob) while suffering from the detection of an adversary (Willie). For both the OM and DM modes, we first conduct theoretical analysis to reveal the inherent relationship between the transmit rate/transmit power and basic covert performance metrics in terms of detection error probability (DEP), effective covert rate (ECR), and covert Shannon capacity (CSC). To facilitate the transmission mode selection at Alice, we then explore the optimization of transmit rate and transmit power for ECR/CSC maximization under the OM and DM modes, and further propose a hybrid OM/DM transmission mode which allows the UAV to adaptively select between the OM and DM modes to achieve the maximum ECR and CSC at a given location of UAV. Finally, extensive numerical results are provided to illustrate the covert performances of the concerned A2G system under different transmission modes, and demonstrate that the hybrid OM/DM transmission mode outperforms the pure OM or DM mode in terms of covert performance.
ECG Heartbeat classification using deep transfer learning with Convolutional Neural Network and STFT technique
Jul 05, 2022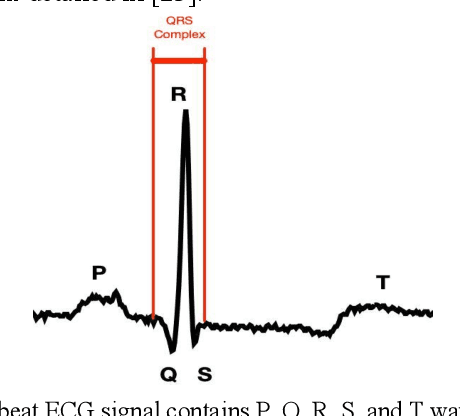
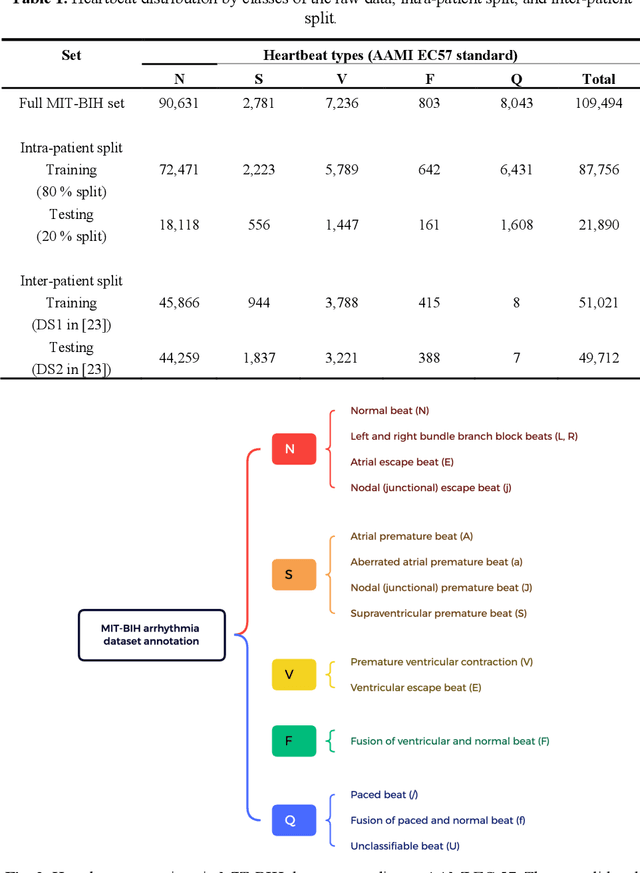
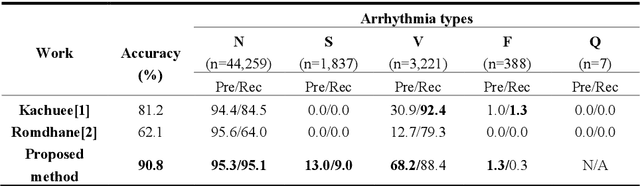
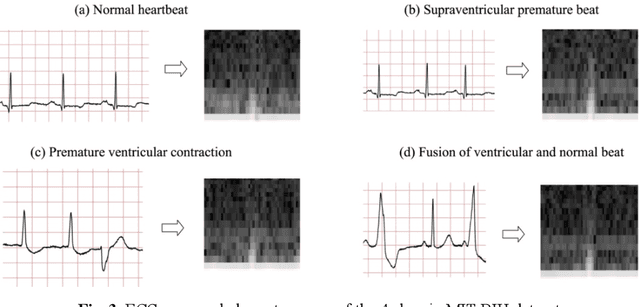
Electrocardiogram (ECG) is a simple non-invasive measure to identify heart-related issues such as irregular heartbeats known as arrhythmias. While artificial intelligence and machine learning is being utilized in a wide range of healthcare related applications and datasets, many arrhythmia classifiers using deep learning methods have been proposed in recent years. However, sizes of the available datasets from which to build and assess machine learning models is often very small and the lack of well-annotated public ECG datasets is evident. In this paper, we propose a deep transfer learning framework that is aimed to perform classification on a small size training dataset. The proposed method is to fine-tune a general-purpose image classifier ResNet-18 with MIT-BIH arrhythmia dataset in accordance with the AAMI EC57 standard. This paper further investigates many existing deep learning models that have failed to avoid data leakage against AAMI recommendations. We compare how different data split methods impact the model performance. This comparison study implies that future work in arrhythmia classification should follow the AAMI EC57 standard when using any including MIT-BIH arrhythmia dataset.
Range of Motion Sensors for Monitoring Recovery of Total Knee Arthroplasty
Jul 01, 2022
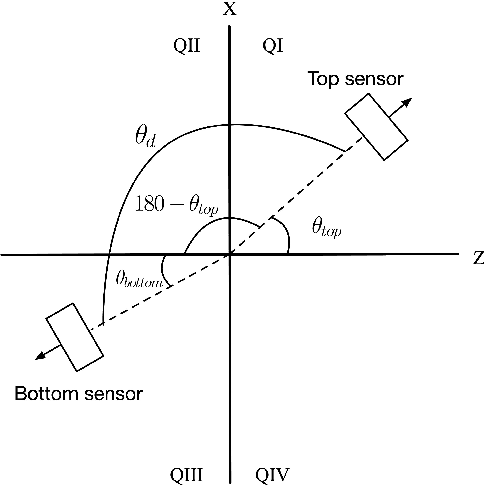


A low-cost, accurate device to measure and record knee range of motion (ROM) is of the essential need to improve confidence in at-home rehabilitation. It is to reduce hospital stay duration and overall medical cost after Total Knee Arthroplasty (TKA) procedures. The shift in Medicare funding from pay-as-you-go to the Bundled Payments for Care Improvement (BPCI) has created a push towards at-home care over extended hospital stays. It has heavily affected TKA patients, who typically undergo physical therapy at the clinic after the procedure to ensure full recovery of ROM. In this paper, we use accelerometers to create a ROM sensor that can be integrated into the post-operative surgical dressing, so that the cost of the sensors can be included in the bundled payments. In this paper, we demonstrate the efficacy of our method in comparison to the baseline computer vision method. Our results suggest that calculating angular displacement from accelerometer sensors demonstrates accurate ROM recordings under both stationary and walking conditions. The device would keep track of angle measurements and alert the patient when certain angle thresholds have been crossed, allowing patients to recover safely at home instead of going to multiple physical therapy sessions. The affordability of our sensor makes it more accessible to patients in need.