 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarek Wodzinski
RegWSI: Whole Slide Image Registration using Combined Deep Feature- and Intensity-Based Methods: Winner of the ACROBAT 2023 Challenge
Apr 26, 2024
The automatic registration of differently stained whole slide images (WSIs) is crucial for improving diagnosis and prognosis by fusing complementary information emerging from different visible structures. It is also useful to quickly transfer annotations between consecutive or restained slides, thus significantly reducing the annotation time and associated costs. Nevertheless, the slide preparation is different for each stain and the tissue undergoes complex and large deformations. Therefore, a robust, efficient, and accurate registration method is highly desired by the scientific community and hospitals specializing in digital pathology. We propose a two-step hybrid method consisting of (i) deep learning- and feature-based initial alignment algorithm, and (ii) intensity-based nonrigid registration using the instance optimization. The proposed method does not require any fine-tuning to a particular dataset and can be used directly for any desired tissue type and stain. The method scored 1st place in the ACROBAT 2023 challenge. We evaluated using three open datasets: (i) ANHIR, (ii) ACROBAT, and (iii) HyReCo, and performed several ablation studies concerning the resolution used for registration and the initial alignment robustness and stability. The method achieves the most accurate results for the ACROBAT dataset, the cell-level registration accuracy for the restained slides from the HyReCo dataset, and is among the best methods evaluated on the ANHIR dataset. The method does not require any fine-tuning to a new datasets and can be used out-of-the-box for other types of microscopic images. The method is incorporated into the DeeperHistReg framework, allowing others to directly use it to register, transform, and save the WSIs at any desired pyramid level. The proposed method is a significant contribution to the WSI registration, thus advancing the field of digital pathology.
DeeperHistReg: Robust Whole Slide Images Registration Framework
Apr 19, 2024DeeperHistReg is a software framework dedicated to registering whole slide images (WSIs) acquired using multiple stains. It allows one to perform the preprocessing, initial alignment, and nonrigid registration of WSIs acquired using multiple stains (e.g. hematoxylin \& eosin, immunochemistry). The framework implements several state-of-the-art registration algorithms and provides an interface to operate on arbitrary resolution of the WSIs (up to 200k x 200k). The framework is extensible and new algorithms can be easily integrated by other researchers. The framework is available both as a PyPI package and as a Docker container.
Eye-tracking in Mixed Reality for Diagnosis of Neurodegenerative Diseases
Apr 19, 2024Parkinson's disease ranks as the second most prevalent neurodegenerative disorder globally. This research aims to develop a system leveraging Mixed Reality capabilities for tracking and assessing eye movements. In this paper, we present a medical scenario and outline the development of an application designed to capture eye-tracking signals through Mixed Reality technology for the evaluation of neurodegenerative diseases. Additionally, we introduce a pipeline for extracting clinically relevant features from eye-gaze analysis, describing the capabilities of the proposed system from a medical perspective. The study involved a cohort of healthy control individuals and patients suffering from Parkinson's disease, showcasing the feasibility and potential of the proposed technology for non-intrusive monitoring of eye movement patterns for the diagnosis of neurodegenerative diseases. Clinical relevance - Developing a non-invasive biomarker for Parkinson's disease is urgently needed to accurately detect the disease's onset. This would allow for the timely introduction of neuroprotective treatment at the earliest stage and enable the continuous monitoring of intervention outcomes. The ability to detect subtle changes in eye movements allows for early diagnosis, offering a critical window for intervention before more pronounced symptoms emerge. Eye tracking provides objective and quantifiable biomarkers, ensuring reliable assessments of disease progression and cognitive function. The eye gaze analysis using Mixed Reality glasses is wireless, facilitating convenient assessments in both home and hospital settings. The approach offers the advantage of utilizing hardware that requires no additional specialized attachments, enabling examinations through personal eyewear.
Automatic Cranial Defect Reconstruction with Self-Supervised Deep Deformable Masked Autoencoders
Apr 19, 2024Thousands of people suffer from cranial injuries every year. They require personalized implants that need to be designed and manufactured before the reconstruction surgery. The manual design is expensive and time-consuming leading to searching for algorithms whose goal is to automatize the process. The problem can be formulated as volumetric shape completion and solved by deep neural networks dedicated to supervised image segmentation. However, such an approach requires annotating the ground-truth defects which is costly and time-consuming. Usually, the process is replaced with synthetic defect generation. However, even the synthetic ground-truth generation is time-consuming and limits the data heterogeneity, thus the deep models' generalizability. In our work, we propose an alternative and simple approach to use a self-supervised masked autoencoder to solve the problem. This approach by design increases the heterogeneity of the training set and can be seen as a form of data augmentation. We compare the proposed method with several state-of-the-art deep neural networks and show both the quantitative and qualitative improvement on the SkullBreak and SkullFix datasets. The proposed method can be used to efficiently reconstruct the cranial defects in real time.
Deep Learning-Based Segmentation of Tumors in PET/CT Volumes: Benchmark of Different Architectures and Training Strategies
Apr 15, 2024Cancer is one of the leading causes of death globally, and early diagnosis is crucial for patient survival. Deep learning algorithms have great potential for automatic cancer analysis. Artificial intelligence has achieved high performance in recognizing and segmenting single lesions. However, diagnosing multiple lesions remains a challenge. This study examines and compares various neural network architectures and training strategies for automatically segmentation of cancer lesions using PET/CT images from the head, neck, and whole body. The authors analyzed datasets from the AutoPET and HECKTOR challenges, exploring popular single-step segmentation architectures and presenting a two-step approach. The results indicate that the V-Net and nnU-Net models were the most effective for their respective datasets. The results for the HECKTOR dataset ranged from 0.75 to 0.76 for the aggregated Dice coefficient. Eliminating cancer-free cases from the AutoPET dataset was found to improve the performance of most models. In the case of AutoPET data, the average segmentation efficiency after training only on images containing cancer lesions increased from 0.55 to 0.66 for the classic Dice coefficient and from 0.65 to 0.73 for the aggregated Dice coefficient. The research demonstrates the potential of artificial intelligence in precise oncological diagnostics and may contribute to the development of more targeted and effective cancer assessment techniques.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
Automatic Aorta Segmentation with Heavily Augmented, High-Resolution 3-D ResUNet: Contribution to the SEG.A Challenge
Oct 24, 2023Automatic aorta segmentation from 3-D medical volumes is an important yet difficult task. Several factors make the problem challenging, e.g. the possibility of aortic dissection or the difficulty with segmenting and annotating the small branches. This work presents a contribution by the MedGIFT team to the SEG.A challenge organized during the MICCAI 2023 conference. We propose a fully automated algorithm based on deep encoder-decoder architecture. The main assumption behind our work is that data preprocessing and augmentation are much more important than the deep architecture, especially in low data regimes. Therefore, the solution is based on a variant of traditional convolutional U-Net. The proposed solution achieved a Dice score above 0.9 for all testing cases with the highest stability among all participants. The method scored 1st, 4th, and 3rd in terms of the clinical evaluation, quantitative results, and volumetric meshing quality, respectively. We freely release the source code, pretrained model, and provide access to the algorithm on the Grand-Challenge platform.
Deep Generative Networks for Heterogeneous Augmentation of Cranial Defects
Aug 09, 2023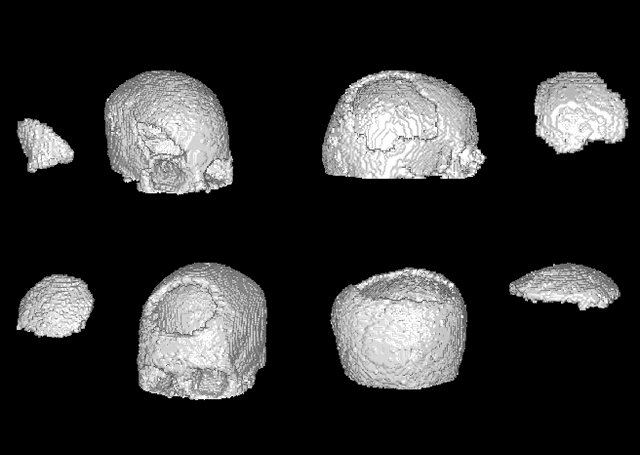
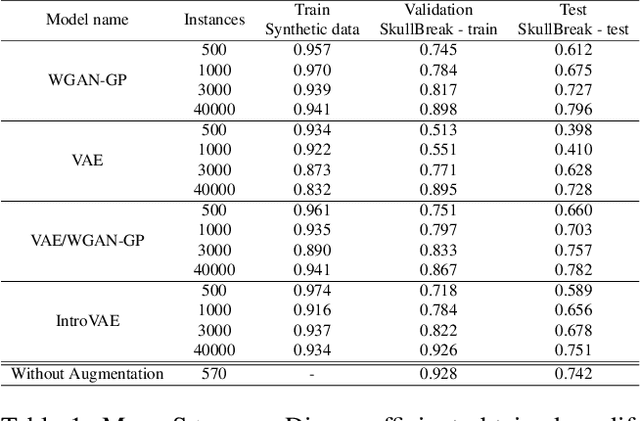

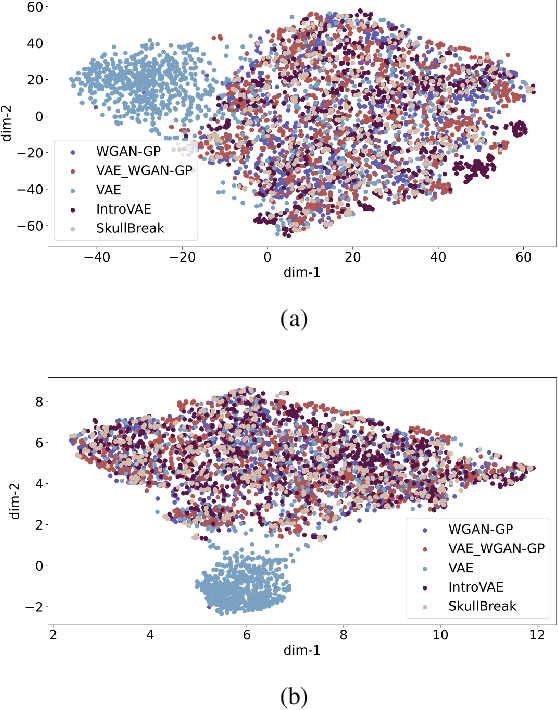
The design of personalized cranial implants is a challenging and tremendous task that has become a hot topic in terms of process automation with the use of deep learning techniques. The main challenge is associated with the high diversity of possible cranial defects. The lack of appropriate data sources negatively influences the data-driven nature of deep learning algorithms. Hence, one of the possible solutions to overcome this problem is to rely on synthetic data. In this work, we propose three volumetric variations of deep generative models to augment the dataset by generating synthetic skulls, i.e. Wasserstein Generative Adversarial Network with Gradient Penalty (WGAN-GP), WGAN-GP hybrid with Variational Autoencoder pretraining (VAE/WGAN-GP) and Introspective Variational Autoencoder (IntroVAE). We show that it is possible to generate dozens of thousands of defective skulls with compatible defects that achieve a trade-off between defect heterogeneity and the realistic shape of the skull. We evaluate obtained synthetic data quantitatively by defect segmentation with the use of V-Net and qualitatively by their latent space exploration. We show that the synthetically generated skulls highly improve the segmentation process compared to using only the original unaugmented data. The generated skulls may improve the automatic design of personalized cranial implants for real medical cases.
High-Resolution Cranial Defect Reconstruction by Iterative, Low-Resolution, Point Cloud Completion Transformers
Aug 07, 2023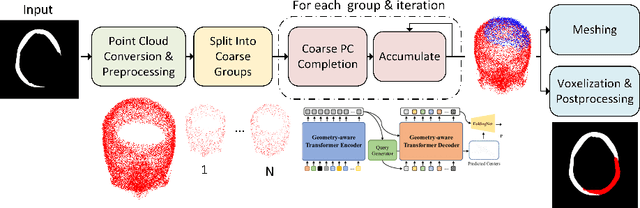
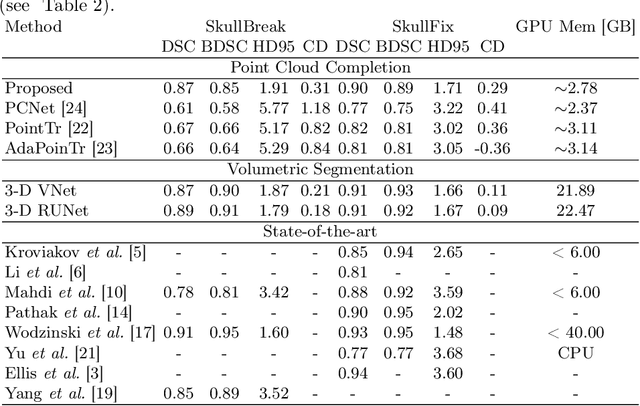
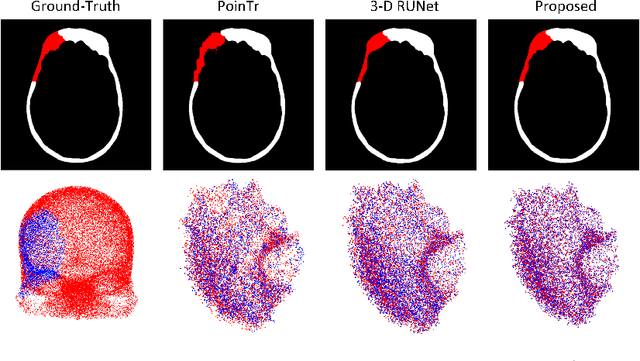

Each year thousands of people suffer from various types of cranial injuries and require personalized implants whose manual design is expensive and time-consuming. Therefore, an automatic, dedicated system to increase the availability of personalized cranial reconstruction is highly desirable. The problem of the automatic cranial defect reconstruction can be formulated as the shape completion task and solved using dedicated deep networks. Currently, the most common approach is to use the volumetric representation and apply deep networks dedicated to image segmentation. However, this approach has several limitations and does not scale well into high-resolution volumes, nor takes into account the data sparsity. In our work, we reformulate the problem into a point cloud completion task. We propose an iterative, transformer-based method to reconstruct the cranial defect at any resolution while also being fast and resource-efficient during training and inference. We compare the proposed methods to the state-of-the-art volumetric approaches and show superior performance in terms of GPU memory consumption while maintaining high-quality of the reconstructed defects.
The ACROBAT 2022 Challenge: Automatic Registration Of Breast Cancer Tissue
May 29, 2023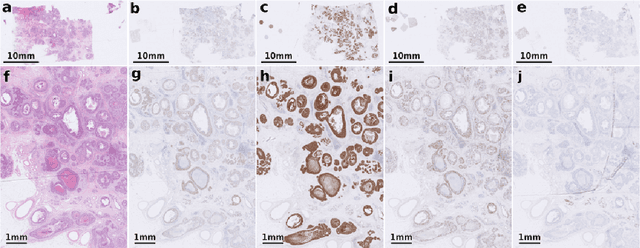
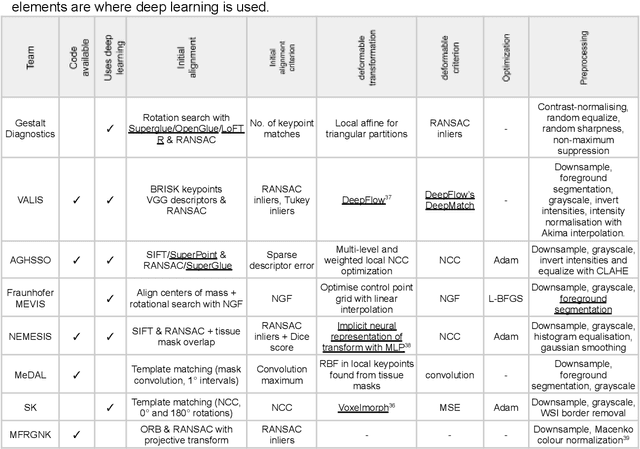
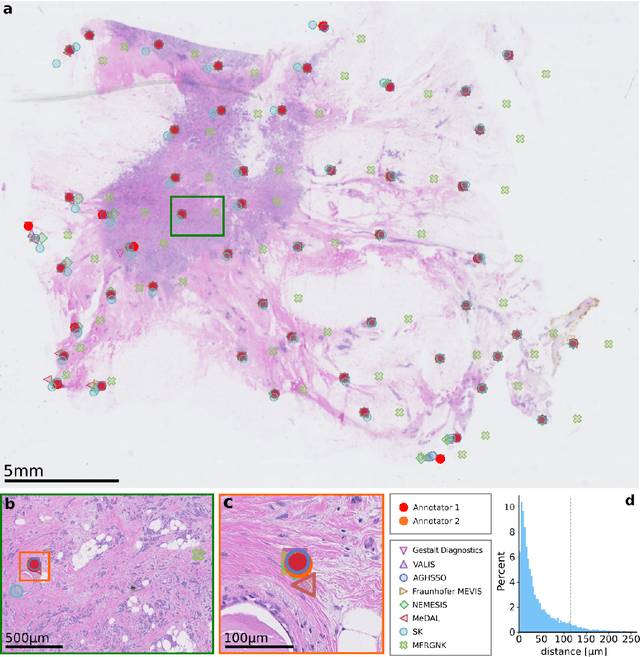
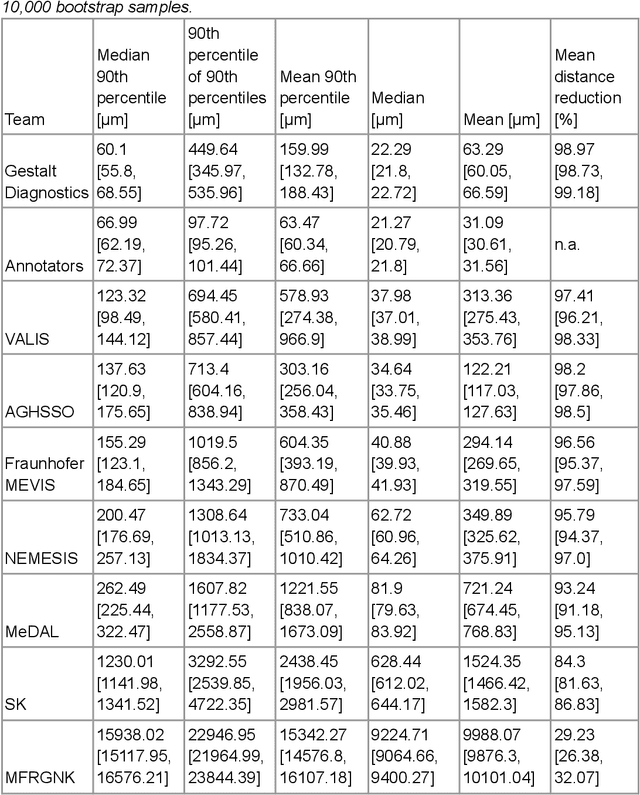
The alignment of tissue between histopathological whole-slide-images (WSI) is crucial for research and clinical applications. Advances in computing, deep learning, and availability of large WSI datasets have revolutionised WSI analysis. Therefore, the current state-of-the-art in WSI registration is unclear. To address this, we conducted the ACROBAT challenge, based on the largest WSI registration dataset to date, including 4,212 WSIs from 1,152 breast cancer patients. The challenge objective was to align WSIs of tissue that was stained with routine diagnostic immunohistochemistry to its H&E-stained counterpart. We compare the performance of eight WSI registration algorithms, including an investigation of the impact of different WSI properties and clinical covariates. We find that conceptually distinct WSI registration methods can lead to highly accurate registration performances and identify covariates that impact performances across methods. These results establish the current state-of-the-art in WSI registration and guide researchers in selecting and developing methods.