 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Zheng
A Multi-Expert Large Language Model Architecture for Verilog Code Generation
Apr 11, 2024
Recently, there has been a surging interest in using large language models (LLMs) for Verilog code generation. However, the existing approaches are limited in terms of the quality of the generated Verilog code. To address such limitations, this paper introduces an innovative multi-expert LLM architecture for Verilog code generation (MEV-LLM). Our architecture uniquely integrates multiple LLMs, each specifically fine-tuned with a dataset that is categorized with respect to a distinct level of design complexity. It allows more targeted learning, directly addressing the nuances of generating Verilog code for each category. Empirical evidence from experiments highlights notable improvements in terms of the percentage of generated Verilog outputs that are syntactically and functionally correct. These findings underscore the efficacy of our approach, promising a forward leap in the field of automated hardware design through machine learning.
MetaDefa: Meta-learning based on Domain Enhancement and Feature Alignment for Single Domain Generalization
Nov 27, 2023The single domain generalization(SDG) based on meta-learning has emerged as an effective technique for solving the domain-shift problem. However, the inadequate match of data distribution between source and augmented domains and difficult separation of domain-invariant features from domain-related features make SDG model hard to achieve great generalization. Therefore, a novel meta-learning method based on domain enhancement and feature alignment (MetaDefa) is proposed to improve the model generalization performance. First, the background substitution and visual corruptions techniques are used to generate diverse and effective augmented domains. Then, the multi-channel feature alignment module based on class activation maps and class agnostic activation maps is designed to effectively extract adequate transferability knowledge. In this module, domain-invariant features can be fully explored by focusing on similar target regions between source and augmented domains feature space and suppressing the feature representation of non-similar target regions. Extensive experiments on two publicly available datasets show that MetaDefa has significant generalization performance advantages in unknown multiple target domains.
Double Reverse Regularization Network Based on Self-Knowledge Distillation for SAR Object Classification
Nov 26, 2023In current synthetic aperture radar (SAR) object classification, one of the major challenges is the severe overfitting issue due to the limited dataset (few-shot) and noisy data. Considering the advantages of knowledge distillation as a learned label smoothing regularization, this paper proposes a novel Double Reverse Regularization Network based on Self-Knowledge Distillation (DRRNet-SKD). Specifically, through exploring the effect of distillation weight on the process of distillation, we are inspired to adopt the double reverse thought to implement an effective regularization network by combining offline and online distillation in a complementary way. Then, the Adaptive Weight Assignment (AWA) module is designed to adaptively assign two reverse-changing weights based on the network performance, allowing the student network to better benefit from both teachers. The experimental results on OpenSARShip and FUSAR-Ship demonstrate that DRRNet-SKD exhibits remarkable performance improvement on classical CNNs, outperforming state-of-the-art self-knowledge distillation methods.
Versatile Medical Image Segmentation Learned from Multi-Source Datasets via Model Self-Disambiguation
Nov 17, 2023A versatile medical image segmentation model applicable to imaging data collected with diverse equipment and protocols can facilitate model deployment and maintenance. However, building such a model typically requires a large, diverse, and fully annotated dataset, which is rarely available due to the labor-intensive and costly data curation. In this study, we develop a cost-efficient method by harnessing readily available data with partially or even sparsely annotated segmentation labels. We devise strategies for model self-disambiguation, prior knowledge incorporation, and imbalance mitigation to address challenges associated with inconsistently labeled data from various sources, including label ambiguity and imbalances across modalities, datasets, and segmentation labels. Experimental results on a multi-modal dataset compiled from eight different sources for abdominal organ segmentation have demonstrated our method's effectiveness and superior performance over alternative state-of-the-art methods, highlighting its potential for optimizing the use of existing annotated data and reducing the annotation efforts for new data to further enhance model capability.
Can Machine Learning Uncover Insights into Vehicle Travel Demand from Our Built Environment?
Nov 10, 2023In this paper, we propose a machine learning-based approach to address the lack of ability for designers to optimize urban land use planning from the perspective of vehicle travel demand. Research shows that our computational model can help designers quickly obtain feedback on the vehicle travel demand, which includes its total amount and temporal distribution based on the urban function distribution designed by the designers. It also assists in design optimization and evaluation of the urban function distribution from the perspective of vehicle travel. We obtain the city function distribution information and vehicle hours traveled (VHT) information by collecting the city point-of-interest (POI) data and online vehicle data. The artificial neural networks (ANNs) with the best performance in prediction are selected. By using data sets collected in different regions for mutual prediction and remapping the predictions onto a map for visualization, we evaluate the extent to which the computational model sees use across regions in an attempt to reduce the workload of future urban researchers. Finally, we demonstrate the application of the computational model to help designers obtain feedback on vehicle travel demand in the built environment and combine it with genetic algorithms to optimize the current state of the urban environment to provide recommendations to designers.
Cross-Level Distillation and Feature Denoising for Cross-Domain Few-Shot Classification
Nov 04, 2023The conventional few-shot classification aims at learning a model on a large labeled base dataset and rapidly adapting to a target dataset that is from the same distribution as the base dataset. However, in practice, the base and the target datasets of few-shot classification are usually from different domains, which is the problem of cross-domain few-shot classification. We tackle this problem by making a small proportion of unlabeled images in the target domain accessible in the training stage. In this setup, even though the base data are sufficient and labeled, the large domain shift still makes transferring the knowledge from the base dataset difficult. We meticulously design a cross-level knowledge distillation method, which can strengthen the ability of the model to extract more discriminative features in the target dataset by guiding the network's shallow layers to learn higher-level information. Furthermore, in order to alleviate the overfitting in the evaluation stage, we propose a feature denoising operation which can reduce the feature redundancy and mitigate overfitting. Our approach can surpass the previous state-of-the-art method, Dynamic-Distillation, by 5.44% on 1-shot and 1.37% on 5-shot classification tasks on average in the BSCD-FSL benchmark. The implementation code will be available at https://github.com/jarucezh/cldfd.
AC-Norm: Effective Tuning for Medical Image Analysis via Affine Collaborative Normalization
Jul 28, 2023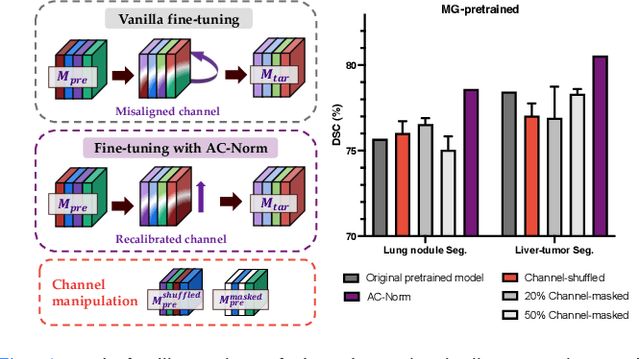
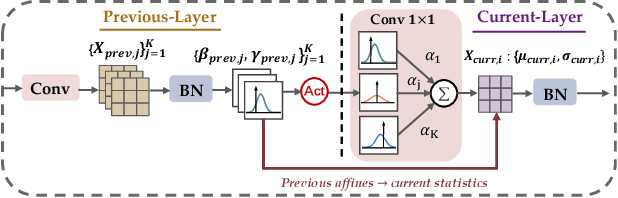
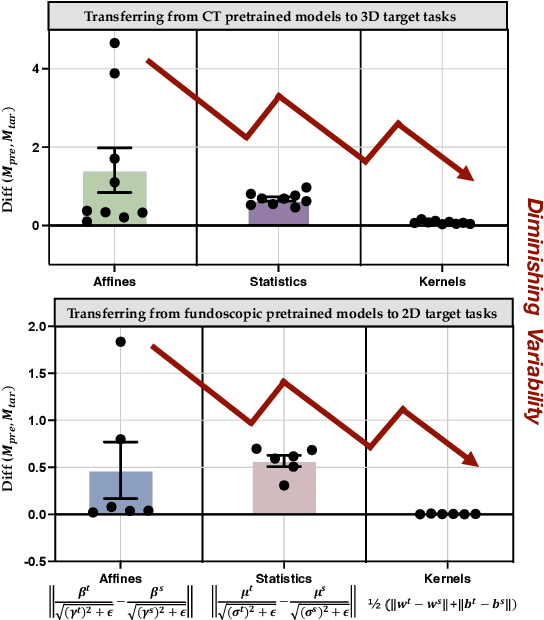
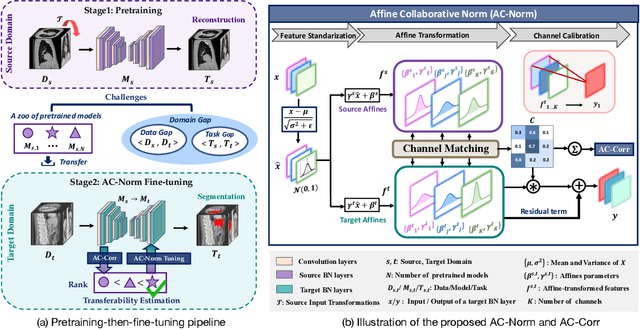
Driven by the latest trend towards self-supervised learning (SSL), the paradigm of "pretraining-then-finetuning" has been extensively explored to enhance the performance of clinical applications with limited annotations. Previous literature on model finetuning has mainly focused on regularization terms and specific policy models, while the misalignment of channels between source and target models has not received sufficient attention. In this work, we revisited the dynamics of batch normalization (BN) layers and observed that the trainable affine parameters of BN serve as sensitive indicators of domain information. Therefore, Affine Collaborative Normalization (AC-Norm) is proposed for finetuning, which dynamically recalibrates the channels in the target model according to the cross-domain channel-wise correlations without adding extra parameters. Based on a single-step backpropagation, AC-Norm can also be utilized to measure the transferability of pretrained models. We evaluated AC-Norm against the vanilla finetuning and state-of-the-art fine-tuning methods on transferring diverse pretrained models to the diabetic retinopathy grade classification, retinal vessel segmentation, CT lung nodule segmentation/classification, CT liver-tumor segmentation and MRI cardiac segmentation tasks. Extensive experiments demonstrate that AC-Norm unanimously outperforms the vanilla finetuning by up to 4% improvement, even under significant domain shifts where the state-of-the-art methods bring no gains. We also prove the capability of AC-Norm in fast transferability estimation. Our code is available at https://github.com/EndoluminalSurgicalVision-IMR/ACNorm.
Gait Cycle-Inspired Learning Strategy for Continuous Prediction of Knee Joint Trajectory from sEMG
Jul 25, 2023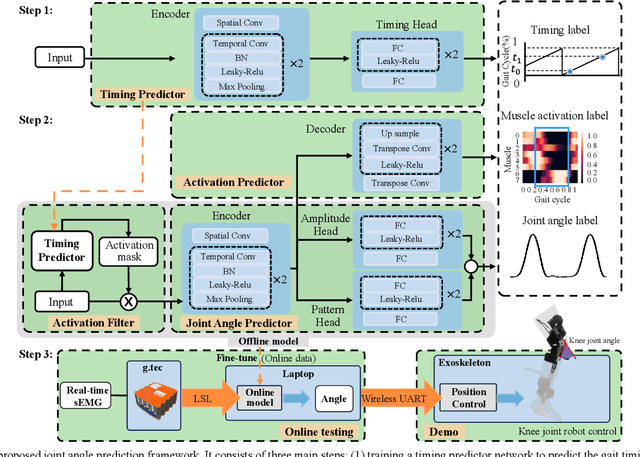
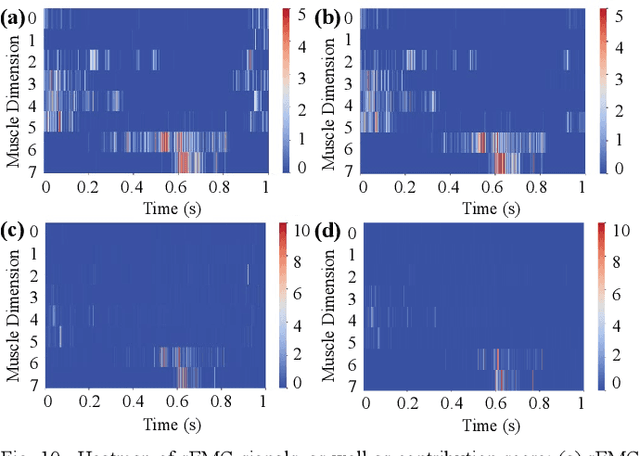
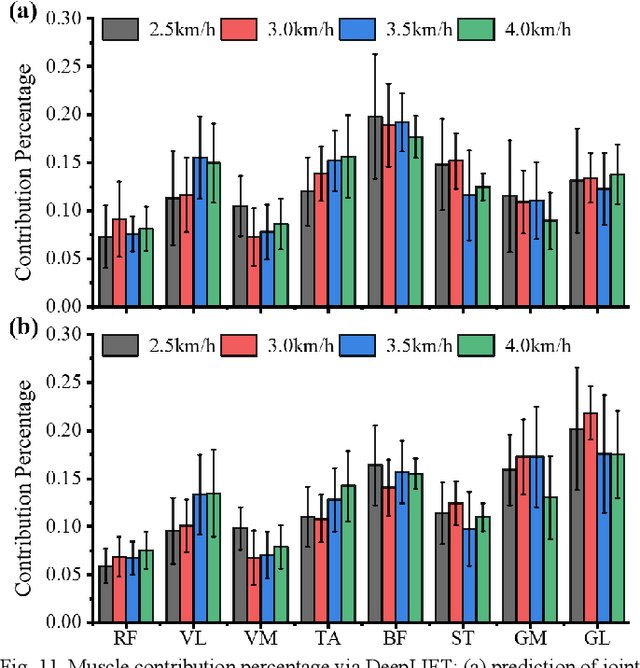
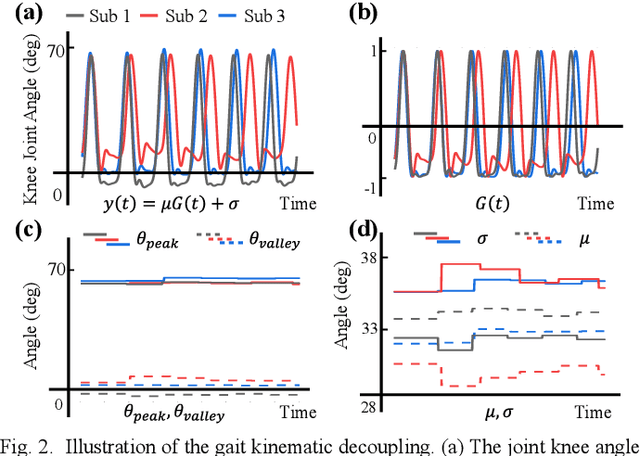
Predicting lower limb motion intent is vital for controlling exoskeleton robots and prosthetic limbs. Surface electromyography (sEMG) attracts increasing attention in recent years as it enables ahead-of-time prediction of motion intentions before actual movement. However, the estimation performance of human joint trajectory remains a challenging problem due to the inter- and intra-subject variations. The former is related to physiological differences (such as height and weight) and preferred walking patterns of individuals, while the latter is mainly caused by irregular and gait-irrelevant muscle activity. This paper proposes a model integrating two gait cycle-inspired learning strategies to mitigate the challenge for predicting human knee joint trajectory. The first strategy is to decouple knee joint angles into motion patterns and amplitudes former exhibit low variability while latter show high variability among individuals. By learning through separate network entities, the model manages to capture both the common and personalized gait features. In the second, muscle principal activation masks are extracted from gait cycles in a prolonged walk. These masks are used to filter out components unrelated to walking from raw sEMG and provide auxiliary guidance to capture more gait-related features. Experimental results indicate that our model could predict knee angles with the average root mean square error (RMSE) of 3.03(0.49) degrees and 50ms ahead of time. To our knowledge this is the best performance in relevant literatures that has been reported, with reduced RMSE by at least 9.5%.
HA-ViD: A Human Assembly Video Dataset for Comprehensive Assembly Knowledge Understanding
Jul 09, 2023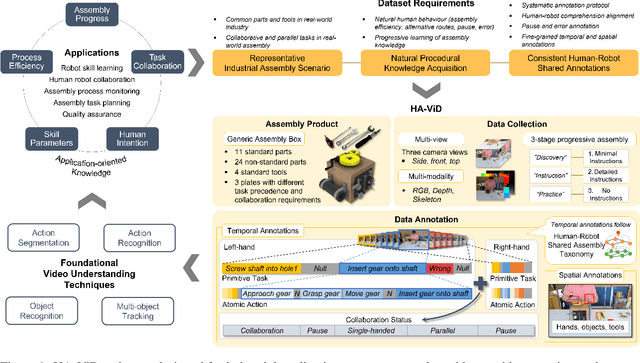
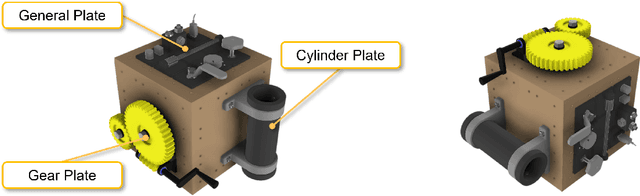

Understanding comprehensive assembly knowledge from videos is critical for futuristic ultra-intelligent industry. To enable technological breakthrough, we present HA-ViD - the first human assembly video dataset that features representative industrial assembly scenarios, natural procedural knowledge acquisition process, and consistent human-robot shared annotations. Specifically, HA-ViD captures diverse collaboration patterns of real-world assembly, natural human behaviors and learning progression during assembly, and granulate action annotations to subject, action verb, manipulated object, target object, and tool. We provide 3222 multi-view, multi-modality videos (each video contains one assembly task), 1.5M frames, 96K temporal labels and 2M spatial labels. We benchmark four foundational video understanding tasks: action recognition, action segmentation, object detection and multi-object tracking. Importantly, we analyze their performance for comprehending knowledge in assembly progress, process efficiency, task collaboration, skill parameters and human intention. Details of HA-ViD is available at: https://iai-hrc.github.io/ha-vid.
Few-Shot Learning with Visual Distribution Calibration and Cross-Modal Distribution Alignment
May 19, 2023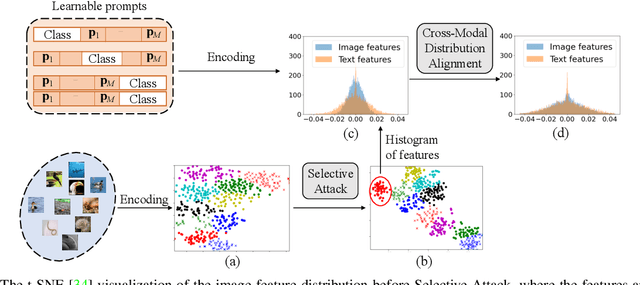
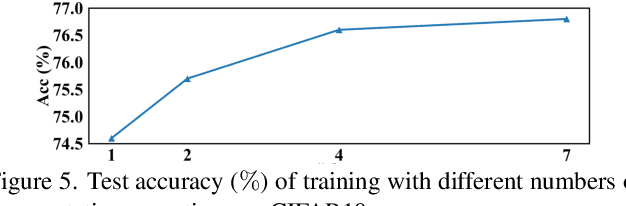
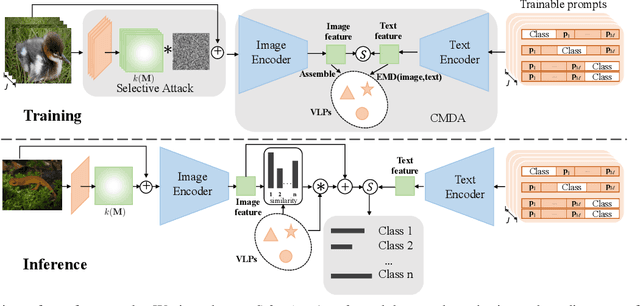
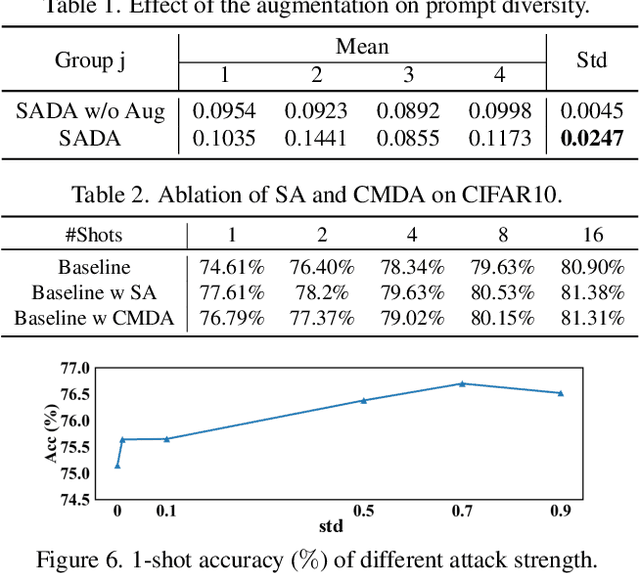
Pre-trained vision-language models have inspired much research on few-shot learning. However, with only a few training images, there exist two crucial problems: (1) the visual feature distributions are easily distracted by class-irrelevant information in images, and (2) the alignment between the visual and language feature distributions is difficult. To deal with the distraction problem, we propose a Selective Attack module, which consists of trainable adapters that generate spatial attention maps of images to guide the attacks on class-irrelevant image areas. By messing up these areas, the critical features are captured and the visual distributions of image features are calibrated. To better align the visual and language feature distributions that describe the same object class, we propose a cross-modal distribution alignment module, in which we introduce a vision-language prototype for each class to align the distributions, and adopt the Earth Mover's Distance (EMD) to optimize the prototypes. For efficient computation, the upper bound of EMD is derived. In addition, we propose an augmentation strategy to increase the diversity of the images and the text prompts, which can reduce overfitting to the few-shot training images. Extensive experiments on 11 datasets demonstrate that our method consistently outperforms prior arts in few-shot learning. The implementation code will be available at https://github.com/bhrqw/SADA.