 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiacheng Wang
PRISM: A Promptable and Robust Interactive Segmentation Model with Visual Prompts
Apr 23, 2024
In this paper, we present PRISM, a Promptable and Robust Interactive Segmentation Model, aiming for precise segmentation of 3D medical images. PRISM accepts various visual inputs, including points, boxes, and scribbles as sparse prompts, as well as masks as dense prompts. Specifically, PRISM is designed with four principles to achieve robustness: (1) Iterative learning. The model produces segmentations by using visual prompts from previous iterations to achieve progressive improvement. (2) Confidence learning. PRISM employs multiple segmentation heads per input image, each generating a continuous map and a confidence score to optimize predictions. (3) Corrective learning. Following each segmentation iteration, PRISM employs a shallow corrective refinement network to reassign mislabeled voxels. (4) Hybrid design. PRISM integrates hybrid encoders to better capture both the local and global information. Comprehensive validation of PRISM is conducted using four public datasets for tumor segmentation in the colon, pancreas, liver, and kidney, highlighting challenges caused by anatomical variations and ambiguous boundaries in accurate tumor identification. Compared to state-of-the-art methods, both with and without prompt engineering, PRISM significantly improves performance, achieving results that are close to human levels. The code is publicly available at https://github.com/MedICL-VU/PRISM.
Generative Artificial Intelligence Assisted Wireless Sensing: Human Flow Detection in Practical Communication Environments
Apr 22, 2024Groundbreaking applications such as ChatGPT have heightened research interest in generative artificial intelligence (GAI). Essentially, GAI excels not only in content generation but also in signal processing, offering support for wireless sensing. Hence, we introduce a novel GAI-assisted human flow detection system (G-HFD). Rigorously, G-HFD first uses channel state information (CSI) to estimate the velocity and acceleration of propagation path length change of the human-induced reflection (HIR). Then, given the strong inference ability of the diffusion model, we propose a unified weighted conditional diffusion model (UW-CDM) to denoise the estimation results, enabling the detection of the number of targets. Next, we use the CSI obtained by a uniform linear array with wavelength spacing to estimate the HIR's time of flight and direction of arrival (DoA). In this process, UW-CDM solves the problem of ambiguous DoA spectrum, ensuring accurate DoA estimation. Finally, through clustering, G-HFD determines the number of subflows and the number of targets in each subflow, i.e., the subflow size. The evaluation based on practical downlink communication signals shows G-HFD's accuracy of subflow size detection can reach 91%. This validates its effectiveness and underscores the significant potential of GAI in the context of wireless sensing.
Multi-attention Associate Prediction Network for Visual Tracking
Mar 25, 2024Classification-regression prediction networks have realized impressive success in several modern deep trackers. However, there is an inherent difference between classification and regression tasks, so they have diverse even opposite demands for feature matching. Existed models always ignore the key issue and only employ a unified matching block in two task branches, decaying the decision quality. Besides, these models also struggle with decision misalignment situation. In this paper, we propose a multi-attention associate prediction network (MAPNet) to tackle the above problems. Concretely, two novel matchers, i.e., category-aware matcher and spatial-aware matcher, are first designed for feature comparison by integrating self, cross, channel or spatial attentions organically. They are capable of fully capturing the category-related semantics for classification and the local spatial contexts for regression, respectively. Then, we present a dual alignment module to enhance the correspondences between two branches, which is useful to find the optimal tracking solution. Finally, we describe a Siamese tracker built upon the proposed prediction network, which achieves the leading performance on five tracking benchmarks, consisting of LaSOT, TrackingNet, GOT-10k, TNL2k and UAV123, and surpasses other state-of-the-art approaches.
Unified Diffusion-Based Rigid and Non-Rigid Editing with Text and Image Guidance
Jan 04, 2024Existing text-to-image editing methods tend to excel either in rigid or non-rigid editing but encounter challenges when combining both, resulting in misaligned outputs with the provided text prompts. In addition, integrating reference images for control remains challenging. To address these issues, we present a versatile image editing framework capable of executing both rigid and non-rigid edits, guided by either textual prompts or reference images. We leverage a dual-path injection scheme to handle diverse editing scenarios and introduce an integrated self-attention mechanism for fusion of appearance and structural information. To mitigate potential visual artifacts, we further employ latent fusion techniques to adjust intermediate latents. Compared to previous work, our approach represents a significant advance in achieving precise and versatile image editing. Comprehensive experiments validate the efficacy of our method, showcasing competitive or superior results in text-based editing and appearance transfer tasks, encompassing both rigid and non-rigid settings.
Acceleration Estimation of Signal Propagation Path Length Changes for Wireless Sensing
Dec 30, 2023As indoor applications grow in diversity, wireless sensing, vital in areas like localization and activity recognition, is attracting renewed interest. Indoor wireless sensing relies on signal processing, particularly channel state information (CSI) based signal parameter estimation. Nonetheless, regarding reflected signals induced by dynamic human targets, no satisfactory algorithm yet exists for estimating the acceleration of dynamic path length change (DPLC), which is crucial for various sensing tasks in this context. Hence, this paper proposes DP-AcE, a CSI-based DPLC acceleration estimation algorithm. We first model the relationship between the phase difference of adjacent CSI measurements and the DPLC's acceleration. Unlike existing works assuming constant velocity, DP-AcE considers both velocity and acceleration, yielding a more accurate and objective representation. Using this relationship, an algorithm combining scaling with Fourier transform is proposed to realize acceleration estimation. We evaluate DP-AcE via the acceleration estimation and acceleration-based fall detection with the collected CSI. Experimental results reveal that, using distance as the metric, DP-AcE achieves a median acceleration estimation percentage error of 4.38%. Furthermore, in multi-target scenarios, the fall detection achieves an average true positive rate of 89.56% and a false positive rate of 11.78%, demonstrating its importance in enhancing indoor wireless sensing capabilities.
Generative AI for Physical Layer Communications: A Survey
Dec 09, 2023The recent evolution of generative artificial intelligence (GAI) leads to the emergence of groundbreaking applications such as ChatGPT, which not only enhances the efficiency of digital content production, such as text, audio, video, or even network traffic data, but also enriches its diversity. Beyond digital content creation, GAI's capability in analyzing complex data distributions offers great potential for wireless communications, particularly amidst a rapid expansion of new physical layer communication technologies. For example, the diffusion model can learn input signal distributions and use them to improve the channel estimation accuracy, while the variational autoencoder can model channel distribution and infer latent variables for blind channel equalization. Therefore, this paper presents a comprehensive investigation of GAI's applications for communications at the physical layer, ranging from traditional issues, including signal classification, channel estimation, and equalization, to emerging topics, such as intelligent reflecting surfaces and joint source channel coding. We also compare GAI-enabled physical layer communications with those supported by traditional AI, highlighting GAI's inherent capabilities and unique contributions in these areas. Finally, the paper discusses open issues and proposes several future research directions, laying a foundation for further exploration and advancement of GAI in physical layer communications.
Novel OCT mosaicking pipeline with Feature- and Pixel-based registration
Nov 21, 2023High-resolution Optical Coherence Tomography (OCT) images are crucial for ophthalmology studies but are limited by their relatively narrow field of view (FoV). Image mosaicking is a technique for aligning multiple overlapping images to obtain a larger FoV. Current mosaicking pipelines often struggle with substantial noise and considerable displacement between the input sub-fields. In this paper, we propose a versatile pipeline for stitching multi-view OCT/OCTA \textit{en face} projection images. Our method combines the strengths of learning-based feature matching and robust pixel-based registration to align multiple images effectively. Furthermore, we advance the application of a trained foundational model, Segment Anything Model (SAM), to validate mosaicking results in an unsupervised manner. The efficacy of our pipeline is validated using an in-house dataset and a large public dataset, where our method shows superior performance in terms of both accuracy and computational efficiency. We also made our evaluation tool for image mosaicking and the corresponding pipeline publicly available at \url{https://github.com/MedICL-VU/OCT-mosaicking}.
Assessing Test-time Variability for Interactive 3D Medical Image Segmentation with Diverse Point Prompts
Nov 13, 2023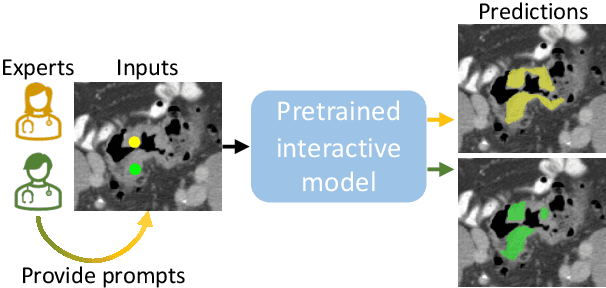
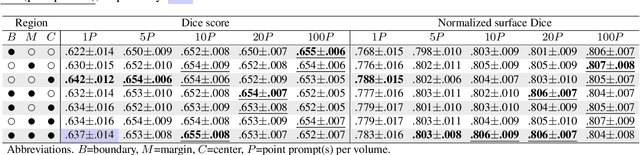
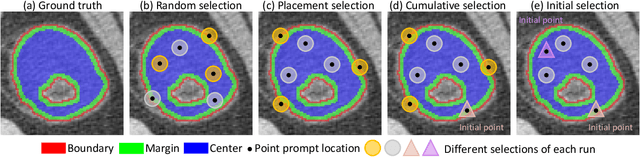

Interactive segmentation model leverages prompts from users to produce robust segmentation. This advancement is facilitated by prompt engineering, where interactive prompts serve as strong priors during test-time. However, this is an inherently subjective and hard-to-reproduce process. The variability in user expertise and inherently ambiguous boundaries in medical images can lead to inconsistent prompt selections, potentially affecting segmentation accuracy. This issue has not yet been extensively explored for medical imaging. In this paper, we assess the test-time variability for interactive medical image segmentation with diverse point prompts. For a given target region, the point is classified into three sub-regions: boundary, margin, and center. Our goal is to identify a straightforward and efficient approach for optimal prompt selection during test-time based on three considerations: (1) benefits of additional prompts, (2) effects of prompt placement, and (3) strategies for optimal prompt selection. We conduct extensive experiments on the public Medical Segmentation Decathlon dataset for challenging colon tumor segmentation task. We suggest an optimal strategy for prompt selection during test-time, supported by comprehensive results. The code is publicly available at https://github.com/MedICL-VU/variability
Promise:Prompt-driven 3D Medical Image Segmentation Using Pretrained Image Foundation Models
Nov 13, 2023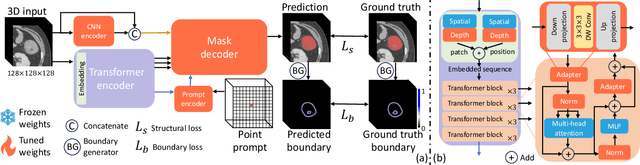



To address prevalent issues in medical imaging, such as data acquisition challenges and label availability, transfer learning from natural to medical image domains serves as a viable strategy to produce reliable segmentation results. However, several existing barriers between domains need to be broken down, including addressing contrast discrepancies, managing anatomical variability, and adapting 2D pretrained models for 3D segmentation tasks. In this paper, we propose ProMISe,a prompt-driven 3D medical image segmentation model using only a single point prompt to leverage knowledge from a pretrained 2D image foundation model. In particular, we use the pretrained vision transformer from the Segment Anything Model (SAM) and integrate lightweight adapters to extract depth-related (3D) spatial context without updating the pretrained weights. For robust results, a hybrid network with complementary encoders is designed, and a boundary-aware loss is proposed to achieve precise boundaries. We evaluate our model on two public datasets for colon and pancreas tumor segmentations, respectively. Compared to the state-of-the-art segmentation methods with and without prompt engineering, our proposed method achieves superior performance. The code is publicly available at https://github.com/MedICL-VU/ProMISe.
Generative AI for Integrated Sensing and Communication: Insights from the Physical Layer Perspective
Oct 02, 2023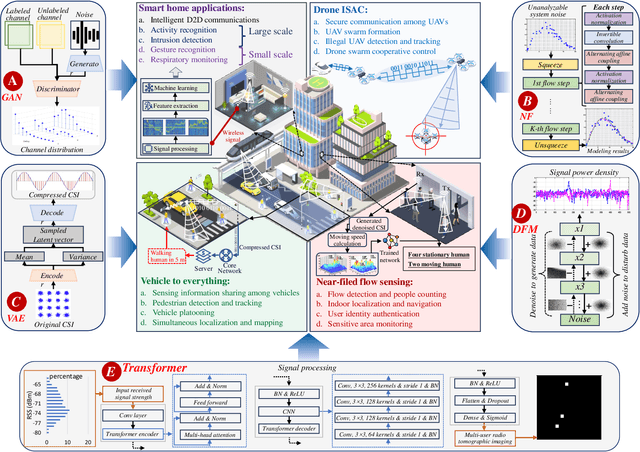

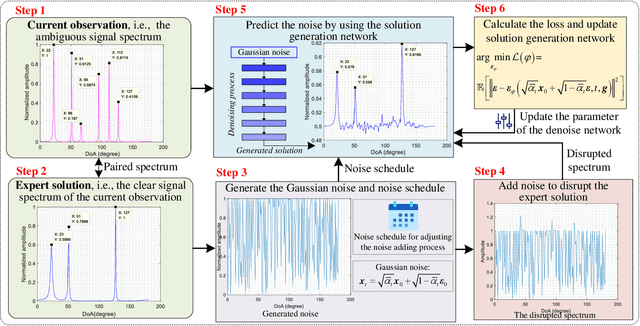
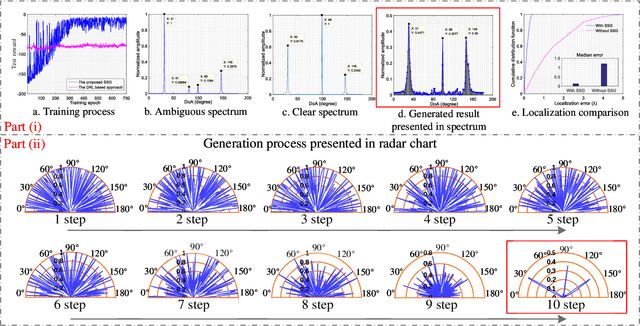
As generative artificial intelligence (GAI) models continue to evolve, their generative capabilities are increasingly enhanced and being used extensively in content generation. Beyond this, GAI also excels in data modeling and analysis, benefitting wireless communication systems. In this article, we investigate applications of GAI in the physical layer and analyze its support for integrated sensing and communications (ISAC) systems. Specifically, we first provide an overview of GAI and ISAC, touching on GAI's potential support across multiple layers of ISAC. We then concentrate on the physical layer, investigating GAI's applications from various perspectives thoroughly, such as channel estimation, and demonstrate the value of these GAI-enhanced physical layer technologies for ISAC systems. In the case study, the proposed diffusion model-based method effectively estimates the signal direction of arrival under the near-field condition based on the uniform linear array, when antenna spacing surpassing half the wavelength. With a mean square error of 1.03 degrees, it confirms GAI's support for the physical layer in near-field sensing and communications.