 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDi Liu
Instantaneous Perception of Moving Objects in 3D
May 05, 2024
The perception of 3D motion of surrounding traffic participants is crucial for driving safety. While existing works primarily focus on general large motions, we contend that the instantaneous detection and quantification of subtle motions is equally important as they indicate the nuances in driving behavior that may be safety critical, such as behaviors near a stop sign of parking positions. We delve into this under-explored task, examining its unique challenges and developing our solution, accompanied by a carefully designed benchmark. Specifically, due to the lack of correspondences between consecutive frames of sparse Lidar point clouds, static objects might appear to be moving - the so-called swimming effect. This intertwines with the true object motion, thereby posing ambiguity in accurate estimation, especially for subtle motions. To address this, we propose to leverage local occupancy completion of object point clouds to densify the shape cue, and mitigate the impact of swimming artifacts. The occupancy completion is learned in an end-to-end fashion together with the detection of moving objects and the estimation of their motion, instantaneously as soon as objects start to move. Extensive experiments demonstrate superior performance compared to standard 3D motion estimation approaches, particularly highlighting our method's specialized treatment of subtle motions.
Evaluating the Application of ChatGPT in Outpatient Triage Guidance: A Comparative Study
Apr 27, 2024The integration of Artificial Intelligence (AI) in healthcare presents a transformative potential for enhancing operational efficiency and health outcomes. Large Language Models (LLMs), such as ChatGPT, have shown their capabilities in supporting medical decision-making. Embedding LLMs in medical systems is becoming a promising trend in healthcare development. The potential of ChatGPT to address the triage problem in emergency departments has been examined, while few studies have explored its application in outpatient departments. With a focus on streamlining workflows and enhancing efficiency for outpatient triage, this study specifically aims to evaluate the consistency of responses provided by ChatGPT in outpatient guidance, including both within-version response analysis and between-version comparisons. For within-version, the results indicate that the internal response consistency for ChatGPT-4.0 is significantly higher than ChatGPT-3.5 (p=0.03) and both have a moderate consistency (71.2% for 4.0 and 59.6% for 3.5) in their top recommendation. However, the between-version consistency is relatively low (mean consistency score=1.43/3, median=1), indicating few recommendations match between the two versions. Also, only 50% top recommendations match perfectly in the comparisons. Interestingly, ChatGPT-3.5 responses are more likely to be complete than those from ChatGPT-4.0 (p=0.02), suggesting possible differences in information processing and response generation between the two versions. The findings offer insights into AI-assisted outpatient operations, while also facilitating the exploration of potentials and limitations of LLMs in healthcare utilization. Future research may focus on carefully optimizing LLMs and AI integration in healthcare systems based on ergonomic and human factors principles, precisely aligning with the specific needs of effective outpatient triage.
AC-EVAL: Evaluating Ancient Chinese Language Understanding in Large Language Models
Mar 11, 2024


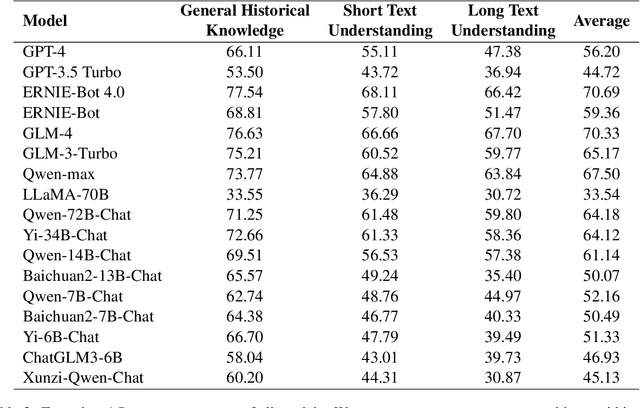
Given the importance of ancient Chinese in capturing the essence of rich historical and cultural heritage, the rapid advancements in Large Language Models (LLMs) necessitate benchmarks that can effectively evaluate their understanding of ancient contexts. To meet this need, we present AC-EVAL, an innovative benchmark designed to assess the advanced knowledge and reasoning capabilities of LLMs within the context of ancient Chinese. AC-EVAL is structured across three levels of difficulty reflecting different facets of language comprehension: general historical knowledge, short text understanding, and long text comprehension. The benchmark comprises 13 tasks, spanning historical facts, geography, social customs, art, philosophy, classical poetry and prose, providing a comprehensive assessment framework. Our extensive evaluation of top-performing LLMs, tailored for both English and Chinese, reveals a substantial potential for enhancing ancient text comprehension. By highlighting the strengths and weaknesses of LLMs, AC-EVAL aims to promote their development and application forward in the realms of ancient Chinese language education and scholarly research. The AC-EVAL data and evaluation code are available at https://github.com/yuting-wei/AC-EVAL.
"When He Feels Cold, He Goes to the Seahorse"-Blending Generative AI into Multimaterial Storymaking for Family Expressive Arts Therapy
Feb 09, 2024Storymaking, as an integrative form of expressive arts therapy, is an effective means to foster family communication. Yet, the integration of generative AI as expressive materials in therapeutic storymaking remains underexplored. And there is a lack of HCI implications on how to support families and therapists in this context. Addressing this, our study involved five weeks of storymaking sessions with seven families guided by a professional therapist. In these sessions, the families used both traditional art-making materials and image-based generative AI to create and evolve their family stories. Via the rich empirical data and commentaries from four expert therapists, we contextualize how families creatively melded AI and traditional expressive materials to externalize their ideas and feelings. Through the lens of Expressive Therapies Continuum (ETC), we characterize the therapeutic implications of AI as expressive materials. Desirable interaction qualities to support children, parents, and therapists are distilled for future HCI research.
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Jan 31, 2024Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
Clustering Molecular Energy Landscapes by Adaptive Network Embedding
Jan 19, 2024In order to efficiently explore the chemical space of all possible small molecules, a common approach is to compress the dimension of the system to facilitate downstream machine learning tasks. Towards this end, we present a data driven approach for clustering potential energy landscapes of molecular structures by applying recently developed Network Embedding techniques, to obtain latent variables defined through the embedding function. To scale up the method, we also incorporate an entropy sensitive adaptive scheme for hierarchical sampling of the energy landscape, based on Metadynamics and Transition Path Theory. By taking into account the kinetic information implied by a system's energy landscape, we are able to interpret dynamical node-node relationships in reduced dimensions. We demonstrate the framework through Lennard-Jones (LJ) clusters and a human DNA sequence.
Pairwise GUI Dataset Construction Between Android Phones and Tablets
Oct 12, 2023
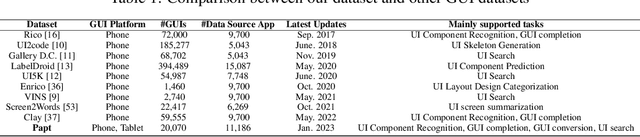
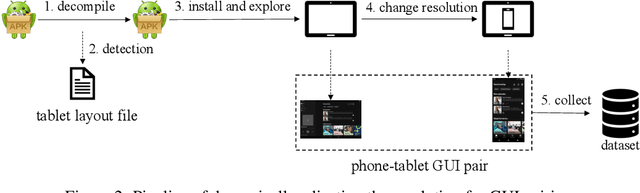

In the current landscape of pervasive smartphones and tablets, apps frequently exist across both platforms. Although apps share most graphic user interfaces (GUIs) and functionalities across phones and tablets, developers often rebuild from scratch for tablet versions, escalating costs and squandering existing design resources. Researchers are attempting to collect data and employ deep learning in automated GUIs development to enhance developers' productivity. There are currently several publicly accessible GUI page datasets for phones, but none for pairwise GUIs between phones and tablets. This poses a significant barrier to the employment of deep learning in automated GUI development. In this paper, we introduce the Papt dataset, a pioneering pairwise GUI dataset tailored for Android phones and tablets, encompassing 10,035 phone-tablet GUI page pairs sourced from 5,593 unique app pairs. We propose novel pairwise GUI collection approaches for constructing this dataset and delineate its advantages over currently prevailing datasets in the field. Through preliminary experiments on this dataset, we analyze the present challenges of utilizing deep learning in automated GUI development.
DeFormer: Integrating Transformers with Deformable Models for 3D Shape Abstraction from a Single Image
Sep 22, 2023
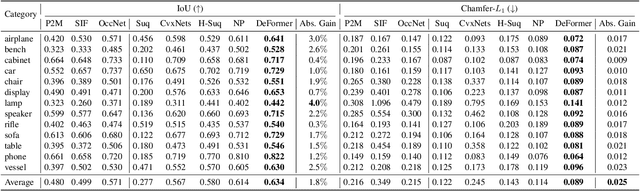
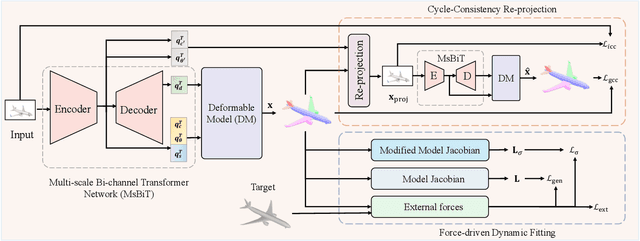
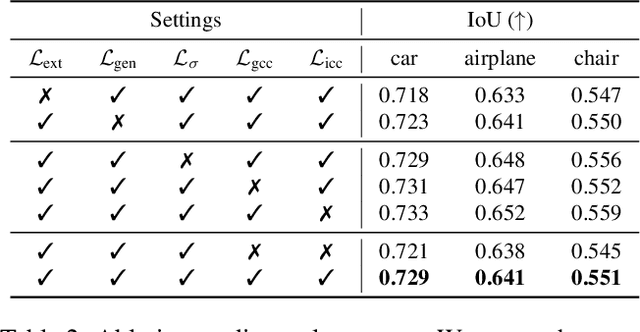
Accurate 3D shape abstraction from a single 2D image is a long-standing problem in computer vision and graphics. By leveraging a set of primitives to represent the target shape, recent methods have achieved promising results. However, these methods either use a relatively large number of primitives or lack geometric flexibility due to the limited expressibility of the primitives. In this paper, we propose a novel bi-channel Transformer architecture, integrated with parameterized deformable models, termed DeFormer, to simultaneously estimate the global and local deformations of primitives. In this way, DeFormer can abstract complex object shapes while using a small number of primitives which offer a broader geometry coverage and finer details. Then, we introduce a force-driven dynamic fitting and a cycle-consistent re-projection loss to optimize the primitive parameters. Extensive experiments on ShapeNet across various settings show that DeFormer achieves better reconstruction accuracy over the state-of-the-art, and visualizes with consistent semantic correspondences for improved interpretability.
Deep Deformable Models: Learning 3D Shape Abstractions with Part Consistency
Sep 02, 2023
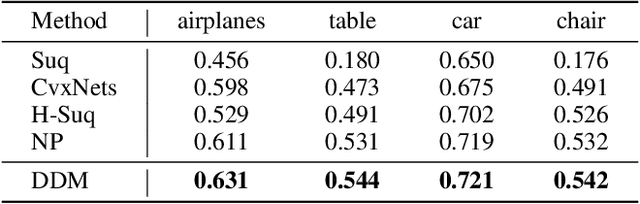
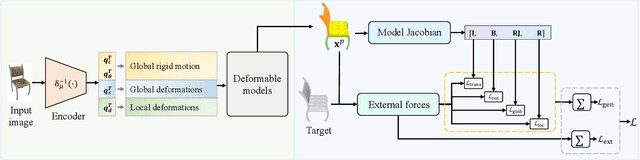
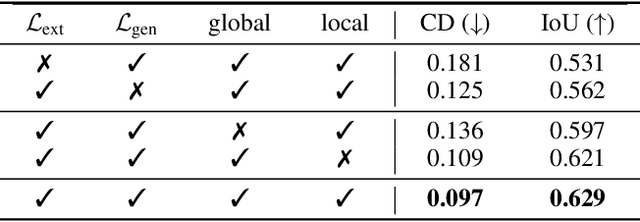
The task of shape abstraction with semantic part consistency is challenging due to the complex geometries of natural objects. Recent methods learn to represent an object shape using a set of simple primitives to fit the target. \textcolor{black}{However, in these methods, the primitives used do not always correspond to real parts or lack geometric flexibility for semantic interpretation.} In this paper, we investigate salient and efficient primitive descriptors for accurate shape abstractions, and propose \textit{Deep Deformable Models (DDMs)}. DDM employs global deformations and diffeomorphic local deformations. These properties enable DDM to abstract complex object shapes with significantly fewer primitives that offer broader geometry coverage and finer details. DDM is also capable of learning part-level semantic correspondences due to the differentiable and invertible properties of our primitive deformation. Moreover, DDM learning formulation is based on dynamic and kinematic modeling, which enables joint regularization of each sub-transformation during primitive fitting. Extensive experiments on \textit{ShapeNet} demonstrate that DDM outperforms the state-of-the-art in terms of reconstruction and part consistency by a notable margin.
Network Embedding Using Sparse Approximations of Random Walks
Aug 25, 2023



In this paper, we propose an efficient numerical implementation of Network Embedding based on commute times, using sparse approximation of a diffusion process on the network obtained by a modified version of the diffusion wavelet algorithm. The node embeddings are computed by optimizing the cross entropy loss via the stochastic gradient descent method with sampling of low-dimensional representations of green functions. We demonstrate the efficacy of this method for data clustering and multi-label classification through several examples, and compare its performance over existing methods in terms of efficiency and accuracy. Theoretical issues justifying the scheme are also discussed.