 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenze Lou
Evaluating LLMs at Detecting Errors in LLM Responses
Apr 04, 2024
With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.
TravelPlanner: A Benchmark for Real-World Planning with Language Agents
Feb 05, 2024Planning has been part of the core pursuit for artificial intelligence since its conception, but earlier AI agents mostly focused on constrained settings because many of the cognitive substrates necessary for human-level planning have been lacking. Recently, language agents powered by large language models (LLMs) have shown interesting capabilities such as tool use and reasoning. Are these language agents capable of planning in more complex settings that are out of the reach of prior AI agents? To advance this investigation, we propose TravelPlanner, a new planning benchmark that focuses on travel planning, a common real-world planning scenario. It provides a rich sandbox environment, various tools for accessing nearly four million data records, and 1,225 meticulously curated planning intents and reference plans. Comprehensive evaluations show that the current language agents are not yet capable of handling such complex planning tasks-even GPT-4 only achieves a success rate of 0.6%. Language agents struggle to stay on task, use the right tools to collect information, or keep track of multiple constraints. However, we note that the mere possibility for language agents to tackle such a complex problem is in itself non-trivial progress. TravelPlanner provides a challenging yet meaningful testbed for future language agents.
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Jan 31, 2024Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
UMIE: Unified Multimodal Information Extraction with Instruction Tuning
Jan 05, 2024Multimodal information extraction (MIE) gains significant attention as the popularity of multimedia content increases. However, current MIE methods often resort to using task-specific model structures, which results in limited generalizability across tasks and underutilizes shared knowledge across MIE tasks. To address these issues, we propose UMIE, a unified multimodal information extractor to unify three MIE tasks as a generation problem using instruction tuning, being able to effectively extract both textual and visual mentions. Extensive experiments show that our single UMIE outperforms various state-of-the-art (SoTA) methods across six MIE datasets on three tasks. Furthermore, in-depth analysis demonstrates UMIE's strong generalization in the zero-shot setting, robustness to instruction variants, and interpretability. Our research serves as an initial step towards a unified MIE model and initiates the exploration into both instruction tuning and large language models within the MIE domain. Our code, data, and model are available at https://github.com/ZUCC-AI/UMIE
MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following
Dec 05, 2023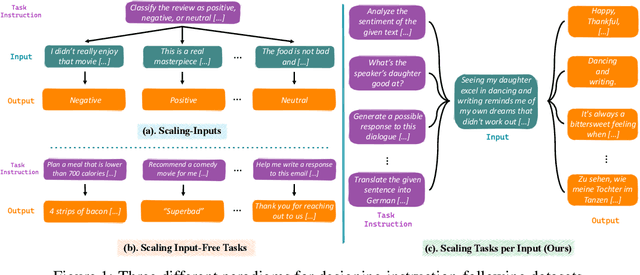

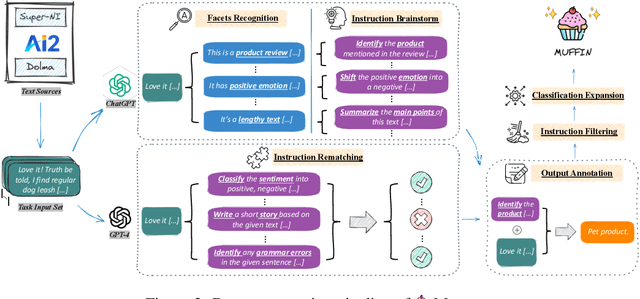
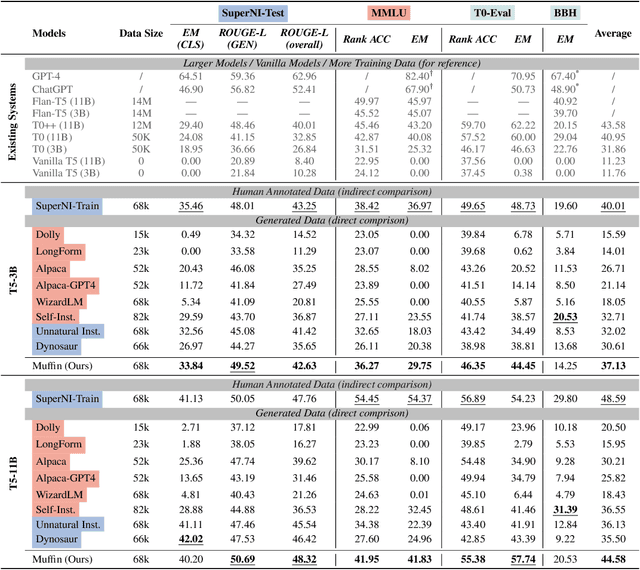
In the realm of large language models (LLMs), enhancing instruction-following capability often involves curating expansive training data. This is achieved through two primary schemes: i) Scaling-Inputs: Amplifying (input, output) pairs per task instruction, aiming for better instruction adherence. ii) Scaling Input-Free Tasks: Enlarging tasks, each composed of an (instruction, output) pair (without requiring a separate input anymore). However, LLMs under Scaling-Inputs tend to be overly sensitive to inputs, leading to misinterpretation or non-compliance with instructions. Conversely, Scaling Input-Free Tasks demands a substantial number of tasks but is less effective in instruction following when dealing with instances in Scaling-Inputs. This work introduces MUFFIN, a new scheme of instruction-following dataset curation. Specifically, we automatically Scale Tasks per Input by diversifying these tasks with various input facets. Experimental results across four zero-shot benchmarks, spanning both Scaling-Inputs and Scaling Input-Free Tasks schemes, reveal that LLMs, at various scales, trained on MUFFIN generally demonstrate superior instruction-following capabilities compared to those trained on the two aforementioned schemes.
Forget Demonstrations, Focus on Learning from Textual Instructions
Aug 04, 2023This work studies a challenging yet more realistic setting for zero-shot cross-task generalization: demonstration-free learning from textual instructions, presuming the existence of a paragraph-style task definition while no demonstrations exist. To better learn the task supervision from the definition, we propose two strategies: first, to automatically find out the critical sentences in the definition; second, a ranking objective to force the model to generate the gold outputs with higher probabilities when those critical parts are highlighted in the definition. The joint efforts of the two strategies yield state-of-the-art performance on the challenging benchmark. Our code will be released in the final version of the paper.
Adaptive Chameleon or Stubborn Sloth: Unraveling the Behavior of Large Language Models in Knowledge Clashes
May 24, 2023
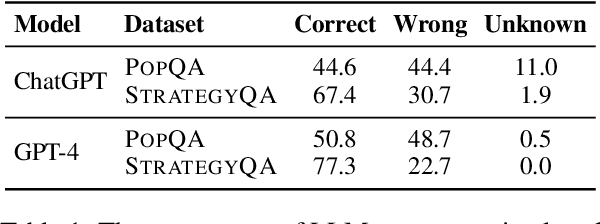


By providing external information to large language models (LLMs), tool augmentation (including retrieval augmentation) has emerged as a promising solution for addressing the limitations of LLMs' static parametric memory. However, how receptive are LLMs to such external evidence, especially when the evidence conflicts with their parametric memory? We present the first comprehensive and controlled investigation into the behavior of LLMs when encountering knowledge conflicts. We propose a systematic framework to elicit high-quality parametric memory from LLMs and construct the corresponding counter-memory, which enables us to conduct a series of controlled experiments. Our investigation reveals seemingly contradicting behaviors of LLMs. On the one hand, different from prior wisdom, we find that LLMs can be highly receptive to external evidence even when that conflicts with their parametric memory, given that the external evidence is coherent and convincing. On the other hand, LLMs also demonstrate a strong confirmation bias when the external evidence contains some information that is consistent with their parametric memory, despite being presented with conflicting evidence at the same time. These results pose important implications that are worth careful consideration for the further development and deployment of tool- and retrieval-augmented LLMs.
Is Prompt All You Need? No. A Comprehensive and Broader View of Instruction Learning
Mar 21, 2023
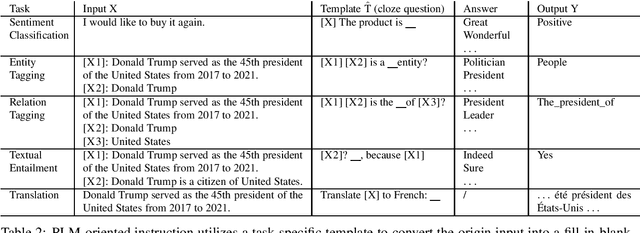

Task semantics can be expressed by a set of input-to-output examples or a piece of textual instruction. Conventional machine learning approaches for natural language processing (NLP) mainly rely on the availability of large-scale sets of task-specific examples. Two issues arise: first, collecting task-specific labeled examples does not apply to scenarios where tasks may be too complicated or costly to annotate, or the system is required to handle a new task immediately; second, this is not user-friendly since end-users are probably more willing to provide task description rather than a set of examples before using the system. Therefore, the community is paying increasing interest in a new supervision-seeking paradigm for NLP: learning from task instructions. Despite its impressive progress, there are some common issues that the community struggles with. This survey paper tries to summarize the current research on instruction learning, particularly, by answering the following questions: (i) what is task instruction, and what instruction types exist? (ii) how to model instructions? (iii) what factors influence and explain the instructions' performance? (iv) what challenges remain in instruction learning? To our knowledge, this is the first comprehensive survey about textual instructions.
PAGE: A Position-Aware Graph-Based Model for Emotion Cause Entailment in Conversation
Mar 03, 2023


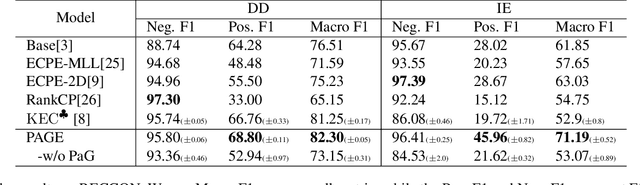
Conversational Causal Emotion Entailment (C2E2) is a task that aims at recognizing the causes corresponding to a target emotion in a conversation. The order of utterances in the conversation affects the causal inference. However, most current position encoding strategies ignore the order relation among utterances and speakers. To address the issue, we devise a novel position-aware graph to encode the entire conversation, fully modeling causal relations among utterances. The comprehensive experiments show that our method consistently achieves state-of-the-art performance on two challenging test sets, proving the effectiveness of our model. Our source code is available on Github: https://github.com/XiaojieGu/PAGE.
MORE: A Metric Learning Based Framework for Open-domain Relation Extraction
Jun 01, 2022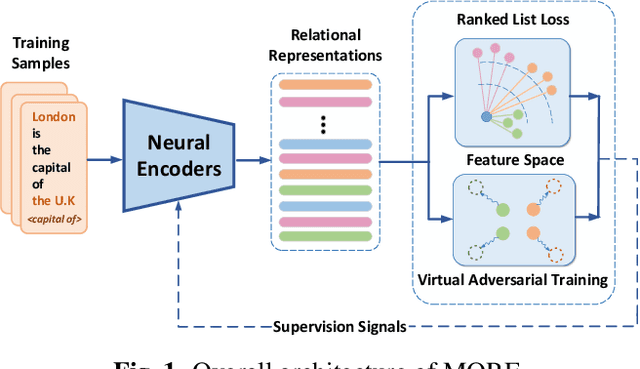
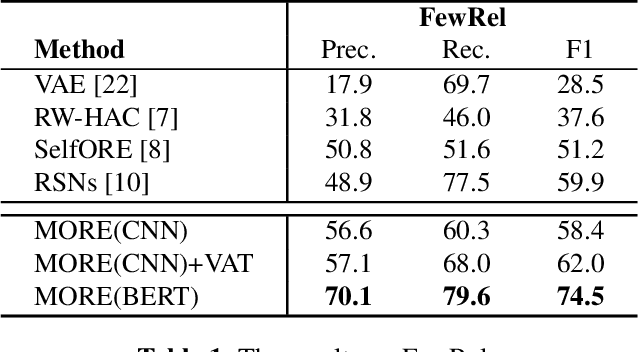

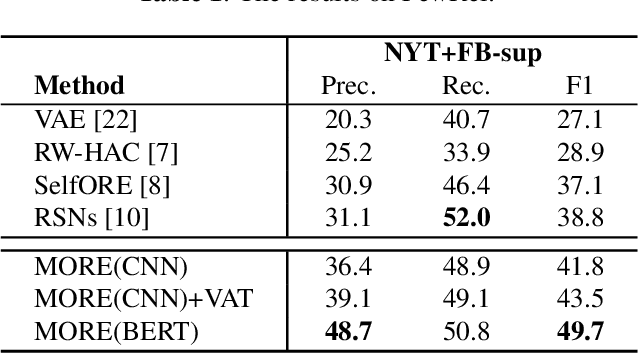
Open relation extraction (OpenRE) is the task of extracting relation schemes from open-domain corpora. Most existing OpenRE methods either do not fully benefit from high-quality labeled corpora or can not learn semantic representation directly, affecting downstream clustering efficiency. To address these problems, in this work, we propose a novel learning framework named MORE (Metric learning-based Open Relation Extraction). The framework utilizes deep metric learning to obtain rich supervision signals from labeled data and drive the neural model to learn semantic relational representation directly. Experiments result in two real-world datasets show that our method outperforms other state-of-the-art baselines. Our source code is available on Github.