 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiapeng Wang
DiffChat: Learning to Chat with Text-to-Image Synthesis Models for Interactive Image Creation
Mar 08, 2024
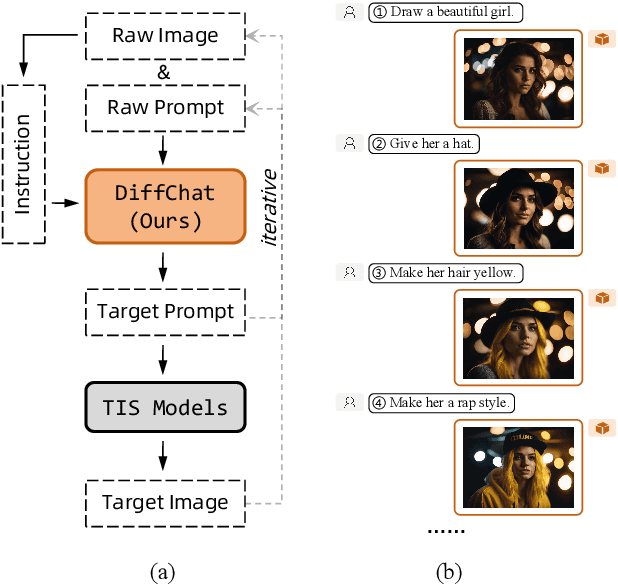

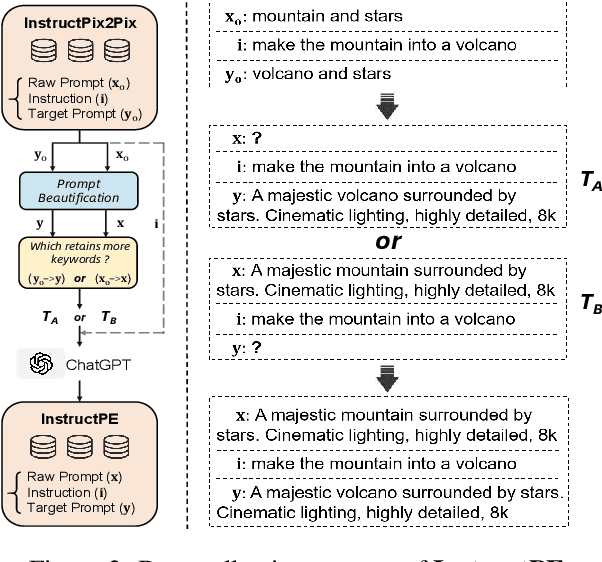
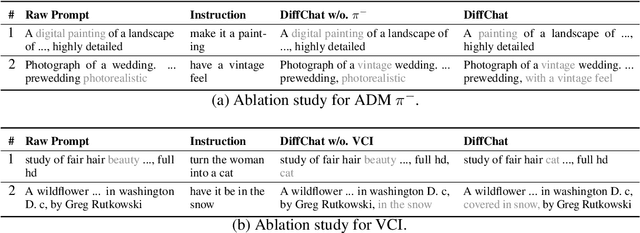
We present DiffChat, a novel method to align Large Language Models (LLMs) to "chat" with prompt-as-input Text-to-Image Synthesis (TIS) models (e.g., Stable Diffusion) for interactive image creation. Given a raw prompt/image and a user-specified instruction, DiffChat can effectively make appropriate modifications and generate the target prompt, which can be leveraged to create the target image of high quality. To achieve this, we first collect an instruction-following prompt engineering dataset named InstructPE for the supervised training of DiffChat. Next, we propose a reinforcement learning framework with the feedback of three core criteria for image creation, i.e., aesthetics, user preference, and content integrity. It involves an action-space dynamic modification technique to obtain more relevant positive samples and harder negative samples during the off-policy sampling. Content integrity is also introduced into the value estimation function for further improvement of produced images. Our method can exhibit superior performance than baseline models and strong competitors based on both automatic and human evaluations, which fully demonstrates its effectiveness.
PEneo: Unifying Line Extraction, Line Grouping, and Entity Linking for End-to-end Document Pair Extraction
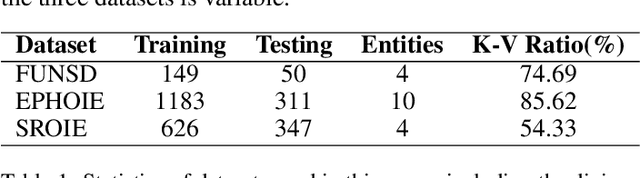
Jan 07, 2024Document pair extraction aims to identify key and value entities as well as their relationships from visually-rich documents. Most existing methods divide it into two separate tasks: semantic entity recognition (SER) and relation extraction (RE). However, simply concatenating SER and RE serially can lead to severe error propagation, and it fails to handle cases like multi-line entities in real scenarios. To address these issues, this paper introduces a novel framework, PEneo (Pair Extraction new decoder option), which performs document pair extraction in a unified pipeline, incorporating three concurrent sub-tasks: line extraction, line grouping, and entity linking. This approach alleviates the error accumulation problem and can handle the case of multi-line entities. Furthermore, to better evaluate the model's performance and to facilitate future research on pair extraction, we introduce RFUND, a re-annotated version of the commonly used FUNSD and XFUND datasets, to make them more accurate and cover realistic situations. Experiments on various benchmarks demonstrate PEneo's superiority over previous pipelines, boosting the performance by a large margin (e.g., 19.89%-22.91% F1 score on RFUND-EN) when combined with various backbones like LiLT and LayoutLMv3, showing its effectiveness and generality. Codes and the new annotations will be open to the public.
Revisiting Scene Text Recognition: A Data Perspective
Jul 19, 2023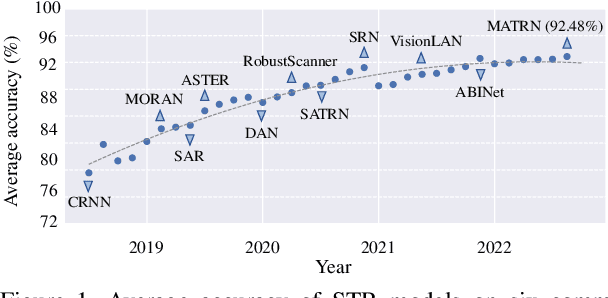
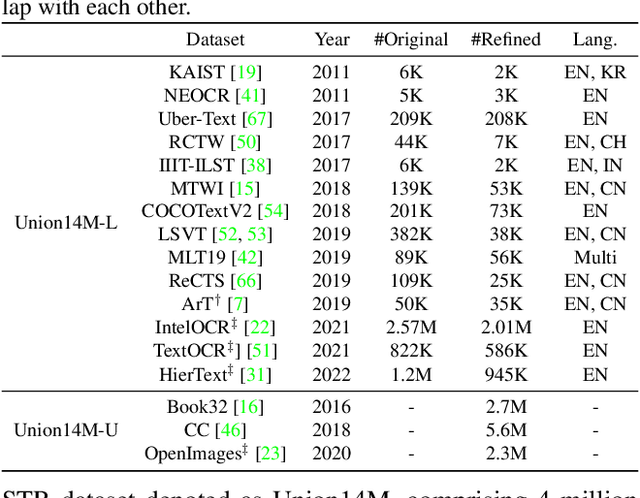
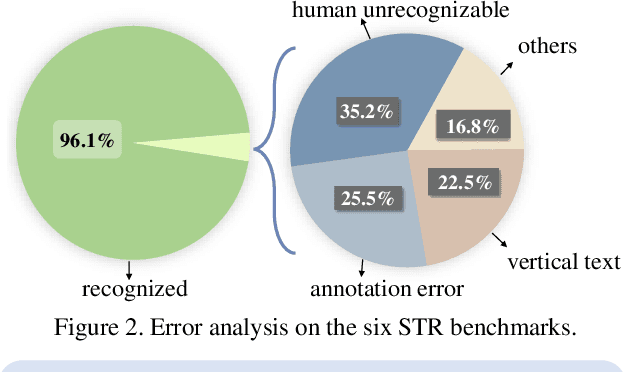
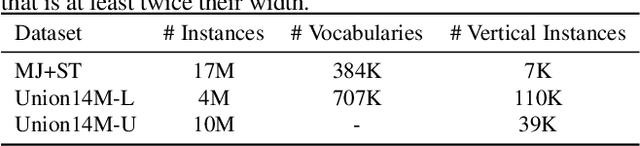
This paper aims to re-assess scene text recognition (STR) from a data-oriented perspective. We begin by revisiting the six commonly used benchmarks in STR and observe a trend of performance saturation, whereby only 2.91% of the benchmark images cannot be accurately recognized by an ensemble of 13 representative models. While these results are impressive and suggest that STR could be considered solved, however, we argue that this is primarily due to the less challenging nature of the common benchmarks, thus concealing the underlying issues that STR faces. To this end, we consolidate a large-scale real STR dataset, namely Union14M, which comprises 4 million labeled images and 10 million unlabeled images, to assess the performance of STR models in more complex real-world scenarios. Our experiments demonstrate that the 13 models can only achieve an average accuracy of 66.53% on the 4 million labeled images, indicating that STR still faces numerous challenges in the real world. By analyzing the error patterns of the 13 models, we identify seven open challenges in STR and develop a challenge-driven benchmark consisting of eight distinct subsets to facilitate further progress in the field. Our exploration demonstrates that STR is far from being solved and leveraging data may be a promising solution. In this regard, we find that utilizing the 10 million unlabeled images through self-supervised pre-training can significantly improve the robustness of STR model in real-world scenarios and leads to state-of-the-art performance.
ConaCLIP: Exploring Distillation of Fully-Connected Knowledge Interaction Graph for Lightweight Text-Image Retrieval
May 28, 2023



Large-scale pre-trained text-image models with dual-encoder architectures (such as CLIP) are typically adopted for various vision-language applications, including text-image retrieval. However,these models are still less practical on edge devices or for real-time situations, due to the substantial indexing and inference time and the large consumption of computational resources. Although knowledge distillation techniques have been widely utilized for uni-modal model compression, how to expand them to the situation when the numbers of modalities and teachers/students are doubled has been rarely studied. In this paper, we conduct comprehensive experiments on this topic and propose the fully-Connected knowledge interaction graph (Cona) technique for cross-modal pre-training distillation. Based on our findings, the resulting ConaCLIP achieves SOTA performances on the widely-used Flickr30K and MSCOCO benchmarks under the lightweight setting. An industry application of our method on an e-commercial platform further demonstrates the significant effectiveness of ConaCLIP.
CAP: instance complexity-aware network pruning
Sep 08, 2022



Existing differentiable channel pruning methods often attach scaling factors or masks behind channels to prune filters with less importance, and assume uniform contribution of input samples to filter importance. Specifically, the effects of instance complexity on pruning performance are not yet fully investigated. In this paper, we propose a simple yet effective differentiable network pruning method CAP based on instance complexity-aware filter importance scores. We define instance complexity related weight for each sample by giving higher weights to hard samples, and measure the weighted sum of sample-specific soft masks to model non-uniform contribution of different inputs, which encourages hard samples to dominate the pruning process and the model performance to be well preserved. In addition, we introduce a new regularizer to encourage polarization of the masks, such that a sweet spot can be easily found to identify the filters to be pruned. Performance evaluations on various network architectures and datasets demonstrate CAP has advantages over the state-of-the-arts in pruning large networks. For instance, CAP improves the accuracy of ResNet56 on CIFAR-10 dataset by 0.33% aftering removing 65.64% FLOPs, and prunes 87.75% FLOPs of ResNet50 on ImageNet dataset with only 0.89% Top-1 accuracy loss.
LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding
Feb 28, 2022



Structured document understanding has attracted considerable attention and made significant progress recently, owing to its crucial role in intelligent document processing. However, most existing related models can only deal with the document data of specific language(s) (typically English) included in the pre-training collection, which is extremely limited. To address this issue, we propose a simple yet effective Language-independent Layout Transformer (LiLT) for structured document understanding. LiLT can be pre-trained on the structured documents of a single language and then directly fine-tuned on other languages with the corresponding off-the-shelf monolingual/multilingual pre-trained textual models. Experimental results on eight languages have shown that LiLT can achieve competitive or even superior performance on diverse widely-used downstream benchmarks, which enables language-independent benefit from the pre-training of document layout structure. Code and model are publicly available at https://github.com/jpWang/LiLT.
MatchVIE: Exploiting Match Relevancy between Entities for Visual Information Extraction
Jun 24, 2021
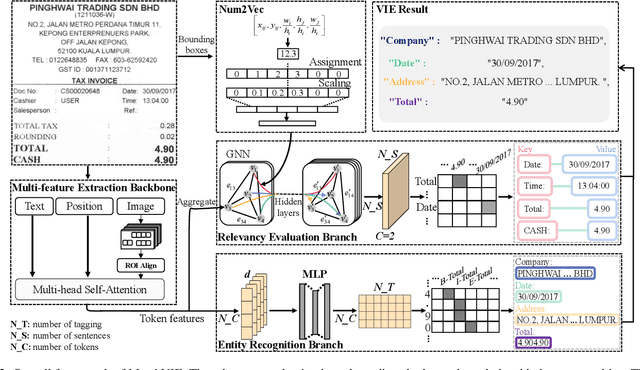
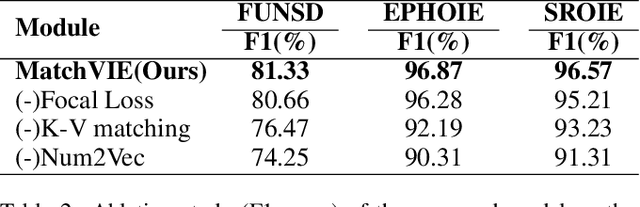
Visual Information Extraction (VIE) task aims to extract key information from multifarious document images (e.g., invoices and purchase receipts). Most previous methods treat the VIE task simply as a sequence labeling problem or classification problem, which requires models to carefully identify each kind of semantics by introducing multimodal features, such as font, color, layout. But simply introducing multimodal features couldn't work well when faced with numeric semantic categories or some ambiguous texts. To address this issue, in this paper we propose a novel key-value matching model based on a graph neural network for VIE (MatchVIE). Through key-value matching based on relevancy evaluation, the proposed MatchVIE can bypass the recognitions to various semantics, and simply focuses on the strong relevancy between entities. Besides, we introduce a simple but effective operation, Num2Vec, to tackle the instability of encoded values, which helps model converge more smoothly. Comprehensive experiments demonstrate that the proposed MatchVIE can significantly outperform previous methods. Notably, to the best of our knowledge, MatchVIE may be the first attempt to tackle the VIE task by modeling the relevancy between keys and values and it is a good complement to the existing methods.
Tag, Copy or Predict: A Unified Weakly-Supervised Learning Framework for Visual Information Extraction using Sequences
Jun 20, 2021



Visual information extraction (VIE) has attracted increasing attention in recent years. The existing methods usually first organized optical character recognition (OCR) results into plain texts and then utilized token-level entity annotations as supervision to train a sequence tagging model. However, it expends great annotation costs and may be exposed to label confusion, and the OCR errors will also significantly affect the final performance. In this paper, we propose a unified weakly-supervised learning framework called TCPN (Tag, Copy or Predict Network), which introduces 1) an efficient encoder to simultaneously model the semantic and layout information in 2D OCR results; 2) a weakly-supervised training strategy that utilizes only key information sequences as supervision; and 3) a flexible and switchable decoder which contains two inference modes: one (Copy or Predict Mode) is to output key information sequences of different categories by copying a token from the input or predicting one in each time step, and the other (Tag Mode) is to directly tag the input sequence in a single forward pass. Our method shows new state-of-the-art performance on several public benchmarks, which fully proves its effectiveness.
Towards Robust Visual Information Extraction in Real World: New Dataset and Novel Solution
Jan 24, 2021

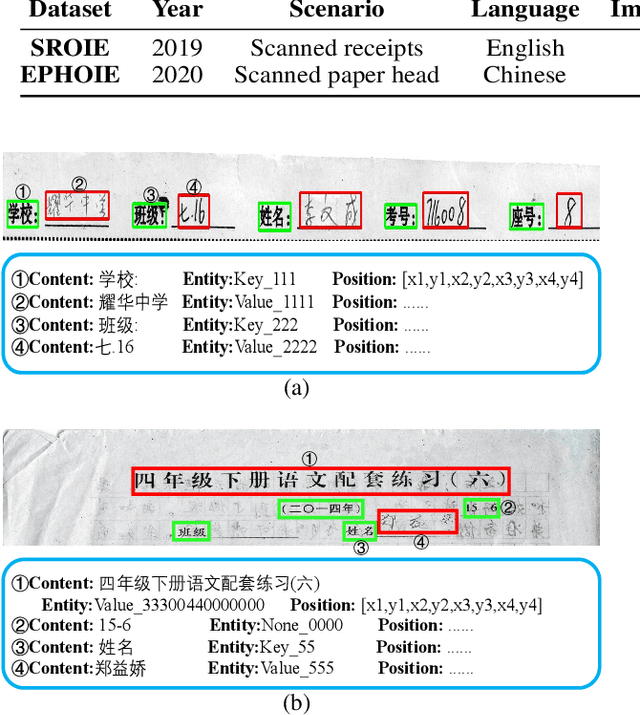
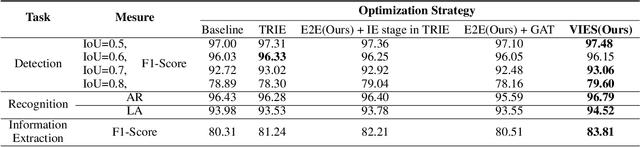
Visual information extraction (VIE) has attracted considerable attention recently owing to its various advanced applications such as document understanding, automatic marking and intelligent education. Most existing works decoupled this problem into several independent sub-tasks of text spotting (text detection and recognition) and information extraction, which completely ignored the high correlation among them during optimization. In this paper, we propose a robust visual information extraction system (VIES) towards real-world scenarios, which is a unified end-to-end trainable framework for simultaneous text detection, recognition and information extraction by taking a single document image as input and outputting the structured information. Specifically, the information extraction branch collects abundant visual and semantic representations from text spotting for multimodal feature fusion and conversely, provides higher-level semantic clues to contribute to the optimization of text spotting. Moreover, regarding the shortage of public benchmarks, we construct a fully-annotated dataset called EPHOIE (https://github.com/HCIILAB/EPHOIE), which is the first Chinese benchmark for both text spotting and visual information extraction. EPHOIE consists of 1,494 images of examination paper head with complex layouts and background, including a total of 15,771 Chinese handwritten or printed text instances. Compared with the state-of-the-art methods, our VIES shows significant superior performance on the EPHOIE dataset and achieves a 9.01% F-score gain on the widely used SROIE dataset under the end-to-end scenario.
Joint Layout Analysis, Character Detection and Recognition for Historical Document Digitization
Jul 14, 2020



In this paper, we propose an end-to-end trainable framework for restoring historical documents content that follows the correct reading order. In this framework, two branches named character branch and layout branch are added behind the feature extraction network. The character branch localizes individual characters in a document image and recognizes them simultaneously. Then we adopt a post-processing method to group them into text lines. The layout branch based on fully convolutional network outputs a binary mask. We then use Hough transform for line detection on the binary mask and combine character results with the layout information to restore document content. These two branches can be trained in parallel and are easy to train. Furthermore, we propose a re-score mechanism to minimize recognition error. Experiment results on the extended Chinese historical document MTHv2 dataset demonstrate the effectiveness of the proposed framework.