 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingdong Chen
Enhancing DETRs Variants through Improved Content Query and Similar Query Aggregation
May 06, 2024
The design of the query is crucial for the performance of DETR and its variants. Each query consists of two components: a content part and a positional one. Traditionally, the content query is initialized with a zero or learnable embedding, lacking essential content information and resulting in sub-optimal performance. In this paper, we introduce a novel plug-and-play module, Self-Adaptive Content Query (SACQ), to address this limitation. The SACQ module utilizes features from the transformer encoder to generate content queries via self-attention pooling. This allows candidate queries to adapt to the input image, resulting in a more comprehensive content prior and better focus on target objects. However, this improved concentration poses a challenge for the training process that utilizes the Hungarian matching, which selects only a single candidate and suppresses other similar ones. To overcome this, we propose a query aggregation strategy to cooperate with SACQ. It merges similar predicted candidates from different queries, easing the optimization. Our extensive experiments on the COCO dataset demonstrate the effectiveness of our proposed approaches across six different DETR's variants with multiple configurations, achieving an average improvement of over 1.0 AP.
Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis
Feb 27, 2024Recent works in implicit representations, such as Neural Radiance Fields (NeRF), have advanced the generation of realistic and animatable head avatars from video sequences. These implicit methods are still confronted by visual artifacts and jitters, since the lack of explicit geometric constraints poses a fundamental challenge in accurately modeling complex facial deformations. In this paper, we introduce Dynamic Tetrahedra (DynTet), a novel hybrid representation that encodes explicit dynamic meshes by neural networks to ensure geometric consistency across various motions and viewpoints. DynTet is parameterized by the coordinate-based networks which learn signed distance, deformation, and material texture, anchoring the training data into a predefined tetrahedra grid. Leveraging Marching Tetrahedra, DynTet efficiently decodes textured meshes with a consistent topology, enabling fast rendering through a differentiable rasterizer and supervision via a pixel loss. To enhance training efficiency, we incorporate classical 3D Morphable Models to facilitate geometry learning and define a canonical space for simplifying texture learning. These advantages are readily achievable owing to the effective geometric representation employed in DynTet. Compared with prior works, DynTet demonstrates significant improvements in fidelity, lip synchronization, and real-time performance according to various metrics. Beyond producing stable and visually appealing synthesis videos, our method also outputs the dynamic meshes which is promising to enable many emerging applications.
M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining
Feb 04, 2024Vision-language foundation models like CLIP have revolutionized the field of artificial intelligence. Nevertheless, VLM models supporting multi-language, e.g., in both Chinese and English, have lagged due to the relative scarcity of large-scale pretraining datasets. Toward this end, we introduce a comprehensive bilingual (Chinese-English) dataset BM-6B with over 6 billion image-text pairs, aimed at enhancing multimodal foundation models to well understand images in both languages. To handle such a scale of dataset, we propose a novel grouped aggregation approach for image-text contrastive loss computation, which reduces the communication overhead and GPU memory demands significantly, facilitating a 60% increase in training speed. We pretrain a series of bilingual image-text foundation models with an enhanced fine-grained understanding ability on BM-6B, the resulting models, dubbed as $M^2$-Encoders (pronounced "M-Square"), set new benchmarks in both languages for multimodal retrieval and classification tasks. Notably, Our largest $M^2$-Encoder-10B model has achieved top-1 accuracies of 88.5% on ImageNet and 80.7% on ImageNet-CN under a zero-shot classification setting, surpassing previously reported SoTA methods by 2.2% and 21.1%, respectively. The $M^2$-Encoder series represents one of the most comprehensive bilingual image-text foundation models to date, so we are making it available to the research community for further exploration and development.
Independent low-rank matrix analysis based on the Sinkhorn divergence source model for blind source separation
Jan 03, 2024The so-called independent low-rank matrix analysis (ILRMA) has demonstrated a great potential for dealing with the problem of determined blind source separation (BSS) for audio and speech signals. This method assumes that the spectra from different frequency bands are independent and the spectral coefficients in any frequency band are Gaussian distributed. The Itakura-Saito divergence is then employed to estimate the source model related parameters. In reality, however, the spectral coefficients from different frequency bands may be dependent, which is not considered in the existing ILRMA algorithm. This paper presents an improved version of ILRMA, which considers the dependency between the spectral coefficients from different frequency bands. The Sinkhorn divergence is then exploited to optimize the source model parameters. As a result of using the cross-band information, the BSS performance is improved. But the number of parameters to be estimated also increases significantly, and so is the computational complexity. To reduce the algorithm complexity, we apply the Kronecker product to decompose the modeling matrix into the product of a number of matrices of much smaller dimensionality. An efficient algorithm is then developed to implement the Sinkhorn divergence based BSS algorithm and the complexity is reduced by an order of magnitude.
SkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery
Dec 15, 2023Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primarily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pre-trained on a curated multi-modal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multi-modal spatiotemporal encoder taking temporal sequences of optical and Synthetic Aperture Radar (SAR) data as input. This encoder is pre-trained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multi-modal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thorough evaluation encompassing 16 datasets over 7 tasks, from single- to multi-modal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pre-trained weights to facilitate future research and Earth Observation applications.
A computationally efficient semi-blind source separation based approach for nonlinear echo cancellation based on an element-wise iterative source steering
Dec 14, 2023While the semi-blind source separation-based acoustic echo cancellation (SBSS-AEC) has received much research attention due to its promising performance during double-talk compared to the traditional adaptive algorithms, it suffers from system latency and nonlinear distortions. To circumvent these drawbacks, the recently developed ideas on convolutive transfer function (CTF) approximation and nonlinear expansion have been used in the iterative projection (IP)-based semi-blind source separation (SBSS) algorithm. However, because of the introduction of CTF approximation and nonlinear expansion, this algorithm becomes computationally very expensive, which makes it difficult to implement in embedded systems. Thus, we attempt in this paper to improve this IP-based algorithm, thereby developing an element-wise iterative source steering (EISS) algorithm. In comparison with the IP-based SBSS algorithm, the proposed algorithm is computationally much more efficient, especially when the nonlinear expansion order is high and the length of the CTF filter is long. Meanwhile, its AEC performance is as good as that of IP-based SBSS.
Large Multimodal Model Compression via Efficient Pruning and Distillation at AntGroup
Dec 10, 2023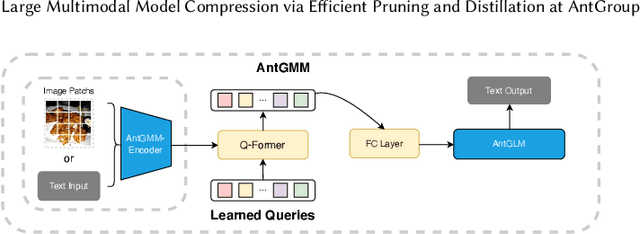

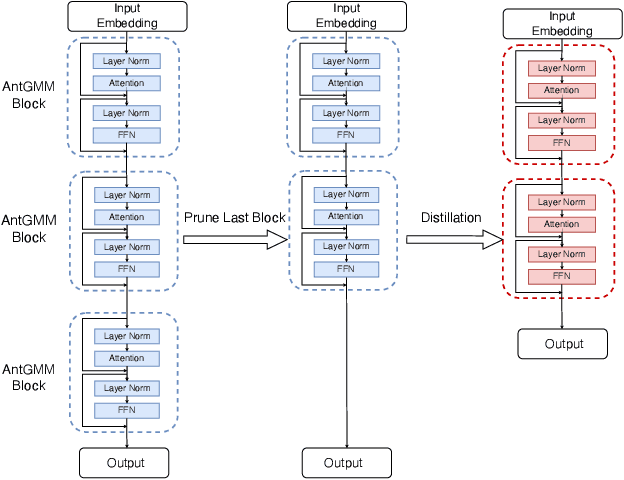

The deployment of Large Multimodal Models (LMMs) within AntGroup has significantly advanced multimodal tasks in payment, security, and advertising, notably enhancing advertisement audition tasks in Alipay. However, the deployment of such sizable models introduces challenges, particularly in increased latency and carbon emissions, which are antithetical to the ideals of Green AI. This paper introduces a novel multi-stage compression strategy for our proprietary LLM, AntGMM. Our methodology pivots on three main aspects: employing small training sample sizes, addressing multi-level redundancy through multi-stage pruning, and introducing an advanced distillation loss design. In our research, we constructed a dataset, the Multimodal Advertisement Audition Dataset (MAAD), from real-world scenarios within Alipay, and conducted experiments to validate the reliability of our proposed strategy. Furthermore, the effectiveness of our strategy is evident in its operational success in Alipay's real-world multimodal advertisement audition for three months from September 2023. Notably, our approach achieved a substantial reduction in latency, decreasing it from 700ms to 90ms, while maintaining online performance with only a slight performance decrease. Moreover, our compressed model is estimated to reduce electricity consumption by approximately 75 million kWh annually compared to the direct deployment of AntGMM, demonstrating our commitment to green AI initiatives. We will publicly release our code and the MAAD dataset after some reviews\footnote{https://github.com/MorinW/AntGMM$\_$Pruning}.
LogicMP: A Neuro-symbolic Approach for Encoding First-order Logic Constraints
Sep 29, 2023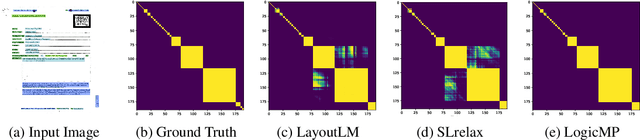


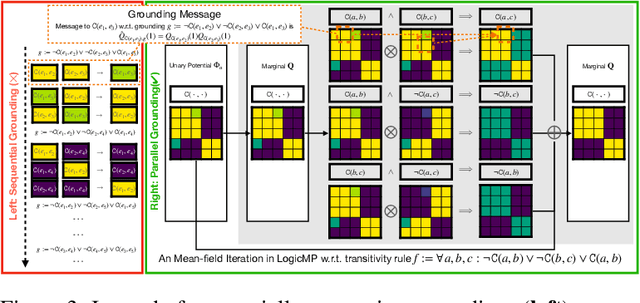
Integrating first-order logic constraints (FOLCs) with neural networks is a crucial but challenging problem since it involves modeling intricate correlations to satisfy the constraints. This paper proposes a novel neural layer, LogicMP, whose layers perform mean-field variational inference over an MLN. It can be plugged into any off-the-shelf neural network to encode FOLCs while retaining modularity and efficiency. By exploiting the structure and symmetries in MLNs, we theoretically demonstrate that our well-designed, efficient mean-field iterations effectively mitigate the difficulty of MLN inference, reducing the inference from sequential calculation to a series of parallel tensor operations. Empirical results in three kinds of tasks over graphs, images, and text show that LogicMP outperforms advanced competitors in both performance and efficiency.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023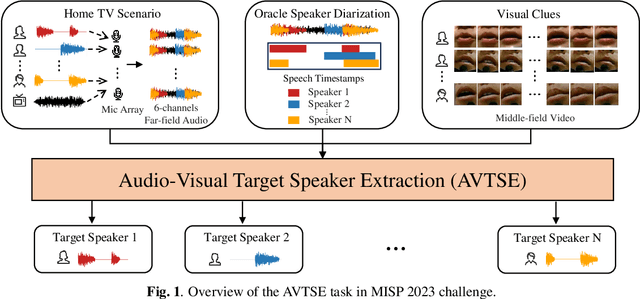
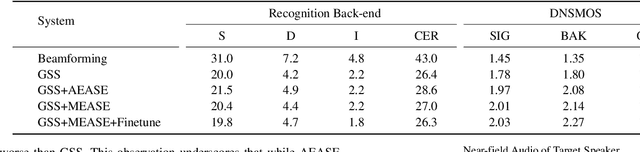
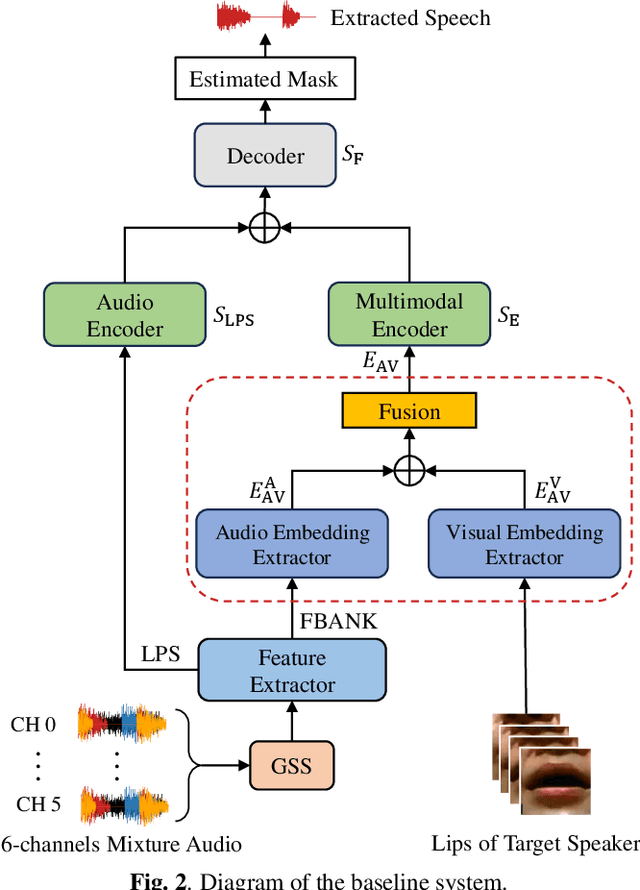
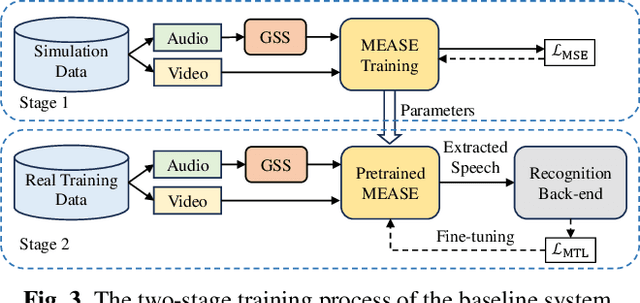
Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
Mapping EEG Signals to Visual Stimuli: A Deep Learning Approach to Match vs. Mismatch Classification
Sep 08, 2023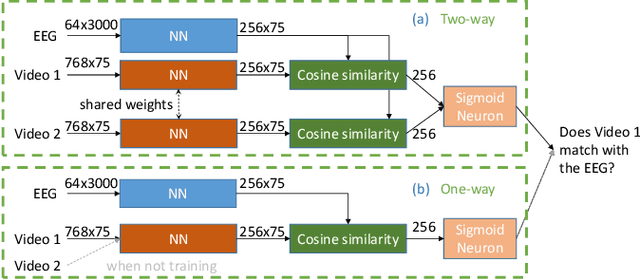
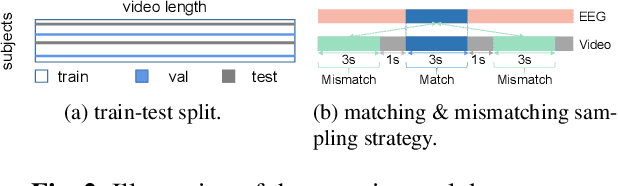
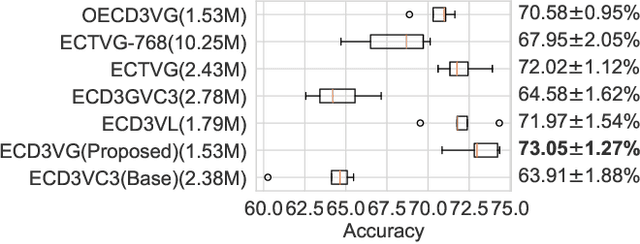
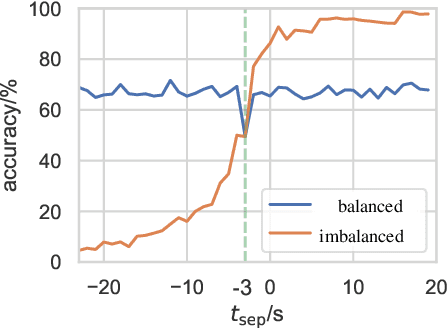
Existing approaches to modeling associations between visual stimuli and brain responses are facing difficulties in handling between-subject variance and model generalization. Inspired by the recent progress in modeling speech-brain response, we propose in this work a ``match-vs-mismatch'' deep learning model to classify whether a video clip induces excitatory responses in recorded EEG signals and learn associations between the visual content and corresponding neural recordings. Using an exclusive experimental dataset, we demonstrate that the proposed model is able to achieve the highest accuracy on unseen subjects as compared to other baseline models. Furthermore, we analyze the inter-subject noise using a subject-level silhouette score in the embedding space and show that the developed model is able to mitigate inter-subject noise and significantly reduce the silhouette score. Moreover, we examine the Grad-CAM activation score and show that the brain regions associated with language processing contribute most to the model predictions, followed by regions associated with visual processing. These results have the potential to facilitate the development of neural recording-based video reconstruction and its related applications.