 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenxi Wang
RISE: 3D Perception Makes Real-World Robot Imitation Simple and Effective
Apr 18, 2024
Precise robot manipulations require rich spatial information in imitation learning. Image-based policies model object positions from fixed cameras, which are sensitive to camera view changes. Policies utilizing 3D point clouds usually predict keyframes rather than continuous actions, posing difficulty in dynamic and contact-rich scenarios. To utilize 3D perception efficiently, we present RISE, an end-to-end baseline for real-world imitation learning, which predicts continuous actions directly from single-view point clouds. It compresses the point cloud to tokens with a sparse 3D encoder. After adding sparse positional encoding, the tokens are featurized using a transformer. Finally, the features are decoded into robot actions by a diffusion head. Trained with 50 demonstrations for each real-world task, RISE surpasses currently representative 2D and 3D policies by a large margin, showcasing significant advantages in both accuracy and efficiency. Experiments also demonstrate that RISE is more general and robust to environmental change compared with previous baselines. Project website: rise-policy.github.io.
Unified Hallucination Detection for Multimodal Large Language Models
Feb 16, 2024Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UNIHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UNIHD through meticulous evaluation and comprehensive analysis. We also provide strategic insights on the application of specific tools for addressing various categories of hallucinations.
Seamless and multi-resolution energy forecasting
Dec 28, 2023Energy forecasting is pivotal in energy systems, by providing fundamentals for operation, with different horizons and resolutions. Though energy forecasting has been widely studied for capturing temporal information, very few works concentrate on the frequency information provided by forecasts. They are consequently often limited to single-resolution applications (e.g., hourly). Here, we propose a unified energy forecasting framework based on Laplace transform in the multi-resolution context. The forecasts can be seamlessly produced at different desired resolutions without re-training or post-processing. Case studies on both energy demand and supply data show that the forecasts from our proposed method can provide accurate information in both time and frequency domains. Across the resolutions, the forecasts also demonstrate high consistency. More importantly, we explore the operational effects of our produced forecasts in the day-ahead and intra-day energy scheduling. The relationship between (i) errors in both time and frequency domains and (ii) operational value of the forecasts is analysed. Significant operational benefits are obtained.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023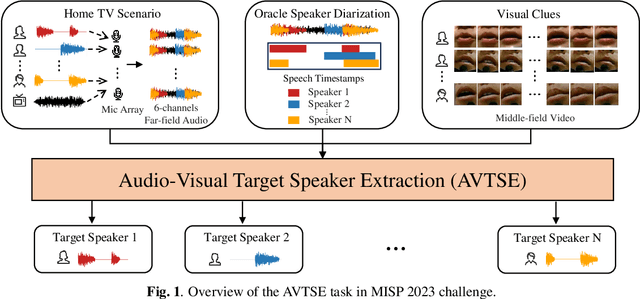
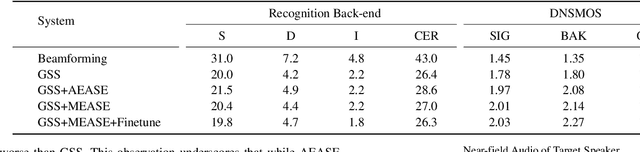
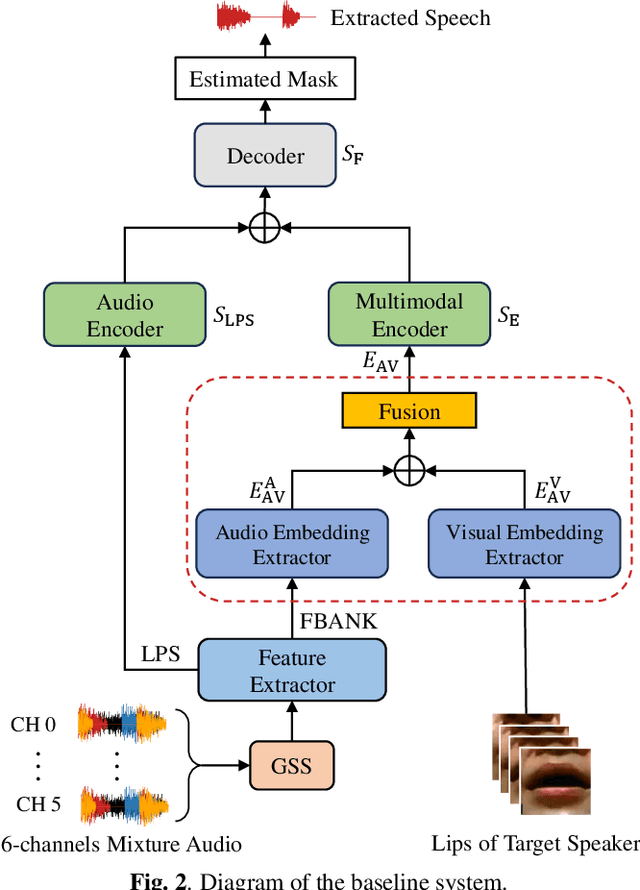
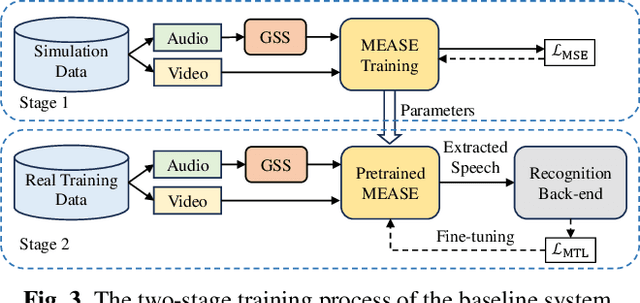
Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
Hierarchical Audio-Visual Information Fusion with Multi-label Joint Decoding for MER 2023
Sep 11, 2023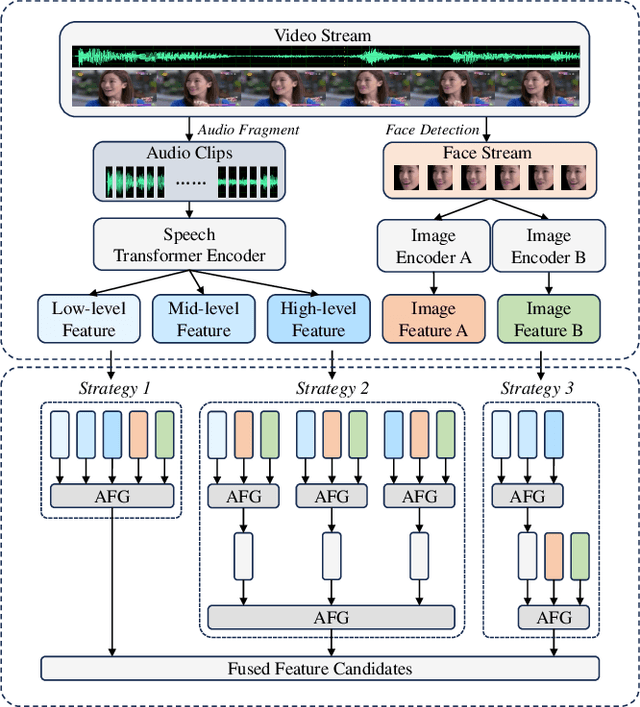
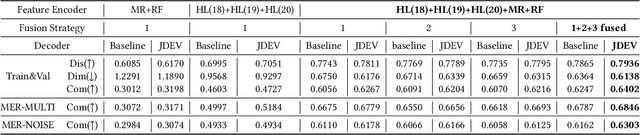
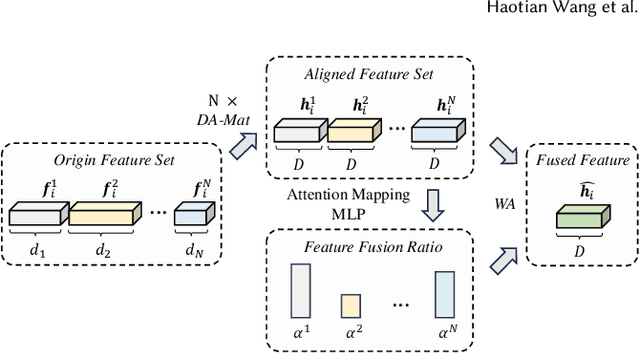
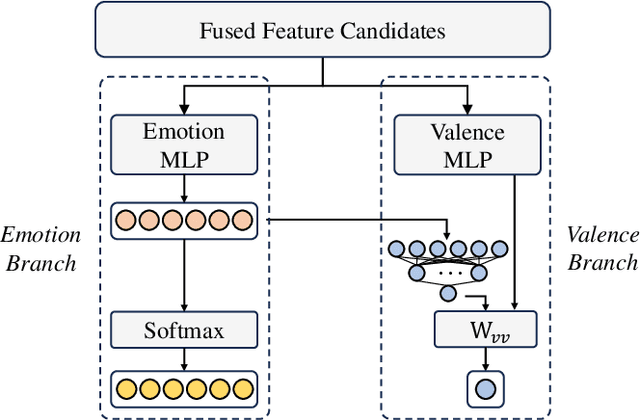
In this paper, we propose a novel framework for recognizing both discrete and dimensional emotions. In our framework, deep features extracted from foundation models are used as robust acoustic and visual representations of raw video. Three different structures based on attention-guided feature gathering (AFG) are designed for deep feature fusion. Then, we introduce a joint decoding structure for emotion classification and valence regression in the decoding stage. A multi-task loss based on uncertainty is also designed to optimize the whole process. Finally, by combining three different structures on the posterior probability level, we obtain the final predictions of discrete and dimensional emotions. When tested on the dataset of multimodal emotion recognition challenge (MER 2023), the proposed framework yields consistent improvements in both emotion classification and valence regression. Our final system achieves state-of-the-art performance and ranks third on the leaderboard on MER-MULTI sub-challenge.
* 5 pages, 4 figures
MB-TaylorFormer: Multi-branch Efficient Transformer Expanded by Taylor Formula for Image Dehazing
Aug 30, 2023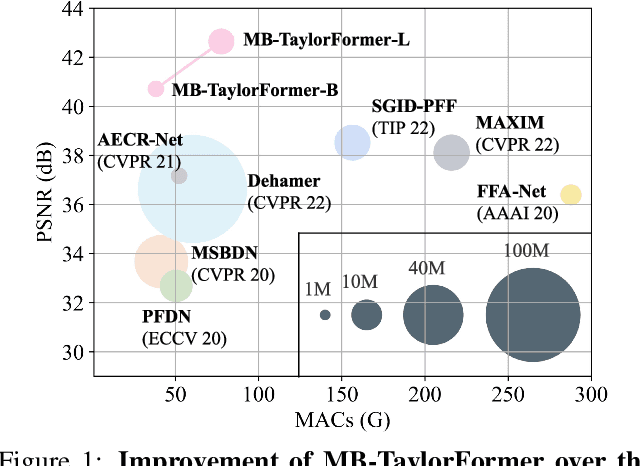
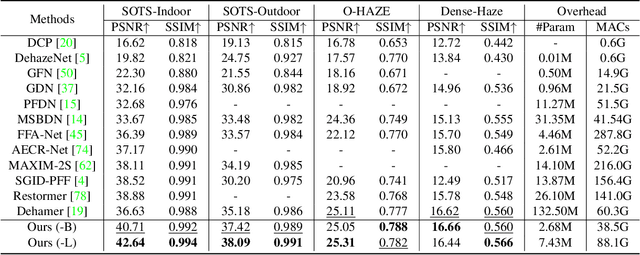
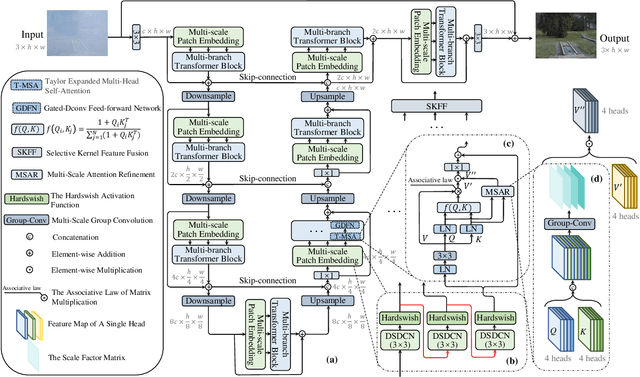

In recent years, Transformer networks are beginning to replace pure convolutional neural networks (CNNs) in the field of computer vision due to their global receptive field and adaptability to input. However, the quadratic computational complexity of softmax-attention limits the wide application in image dehazing task, especially for high-resolution images. To address this issue, we propose a new Transformer variant, which applies the Taylor expansion to approximate the softmax-attention and achieves linear computational complexity. A multi-scale attention refinement module is proposed as a complement to correct the error of the Taylor expansion. Furthermore, we introduce a multi-branch architecture with multi-scale patch embedding to the proposed Transformer, which embeds features by overlapping deformable convolution of different scales. The design of multi-scale patch embedding is based on three key ideas: 1) various sizes of the receptive field; 2) multi-level semantic information; 3) flexible shapes of the receptive field. Our model, named Multi-branch Transformer expanded by Taylor formula (MB-TaylorFormer), can embed coarse to fine features more flexibly at the patch embedding stage and capture long-distance pixel interactions with limited computational cost. Experimental results on several dehazing benchmarks show that MB-TaylorFormer achieves state-of-the-art (SOTA) performance with a light computational burden. The source code and pre-trained models are available at https://github.com/FVL2020/ICCV-2023-MB-TaylorFormer.
FourLLIE: Boosting Low-Light Image Enhancement by Fourier Frequency Information
Aug 06, 2023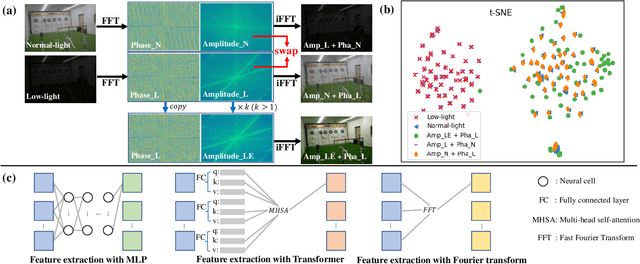

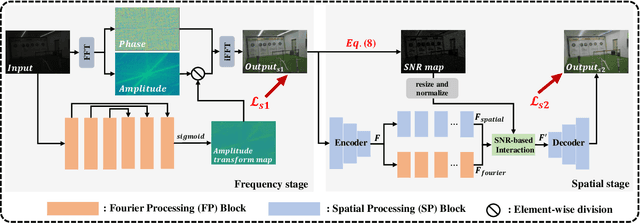
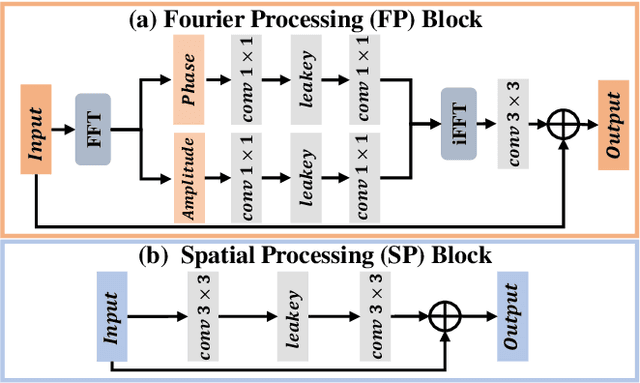
Recently, Fourier frequency information has attracted much attention in Low-Light Image Enhancement (LLIE). Some researchers noticed that, in the Fourier space, the lightness degradation mainly exists in the amplitude component and the rest exists in the phase component. By incorporating both the Fourier frequency and the spatial information, these researchers proposed remarkable solutions for LLIE. In this work, we further explore the positive correlation between the magnitude of amplitude and the magnitude of lightness, which can be effectively leveraged to improve the lightness of low-light images in the Fourier space. Moreover, we find that the Fourier transform can extract the global information of the image, and does not introduce massive neural network parameters like Multi-Layer Perceptrons (MLPs) or Transformer. To this end, a two-stage Fourier-based LLIE network (FourLLIE) is proposed. In the first stage, we improve the lightness of low-light images by estimating the amplitude transform map in the Fourier space. In the second stage, we introduce the Signal-to-Noise-Ratio (SNR) map to provide the prior for integrating the global Fourier frequency and the local spatial information, which recovers image details in the spatial space. With this ingenious design, FourLLIE outperforms the existing state-of-the-art (SOTA) LLIE methods on four representative datasets while maintaining good model efficiency.
Brighten-and-Colorize: A Decoupled Network for Customized Low-Light Image Enhancement
Aug 06, 2023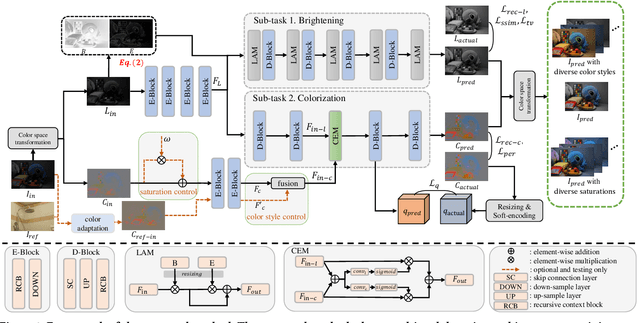

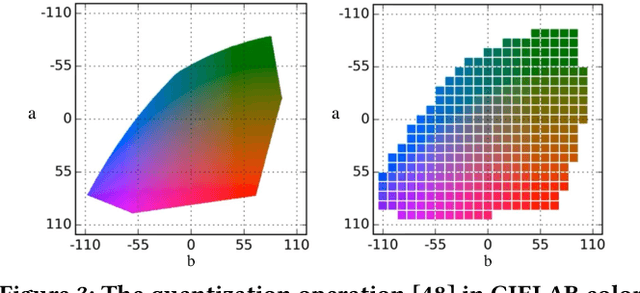
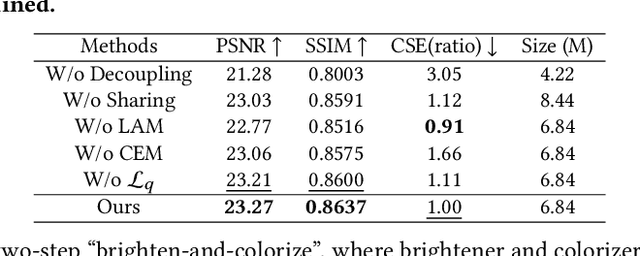
Low-Light Image Enhancement (LLIE) aims to improve the perceptual quality of an image captured in low-light conditions. Generally, a low-light image can be divided into lightness and chrominance components. Recent advances in this area mainly focus on the refinement of the lightness, while ignoring the role of chrominance. It easily leads to chromatic aberration and, to some extent, limits the diverse applications of chrominance in customized LLIE. In this work, a ``brighten-and-colorize'' network (called BCNet), which introduces image colorization to LLIE, is proposed to address the above issues. BCNet can accomplish LLIE with accurate color and simultaneously enables customized enhancement with varying saturations and color styles based on user preferences. Specifically, BCNet regards LLIE as a multi-task learning problem: brightening and colorization. The brightening sub-task aligns with other conventional LLIE methods to get a well-lit lightness. The colorization sub-task is accomplished by regarding the chrominance of the low-light image as color guidance like the user-guide image colorization. Upon completion of model training, the color guidance (i.e., input low-light chrominance) can be simply manipulated by users to acquire customized results. This customized process is optional and, due to its decoupled nature, does not compromise the structural and detailed information of lightness. Extensive experiments on the commonly used LLIE datasets show that the proposed method achieves both State-Of-The-Art (SOTA) performance and user-friendly customization.
AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains
Dec 16, 2022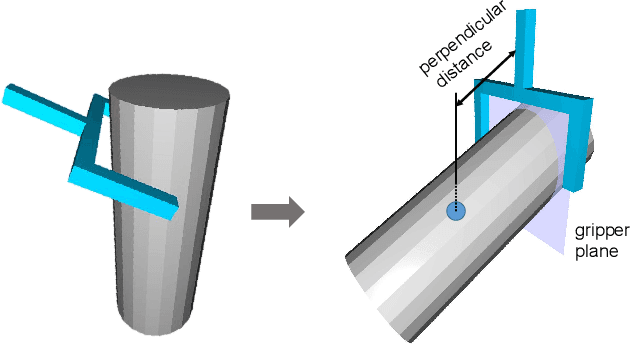
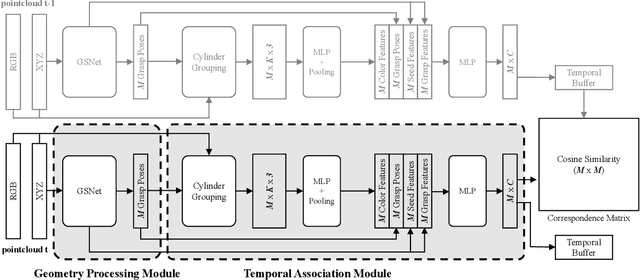
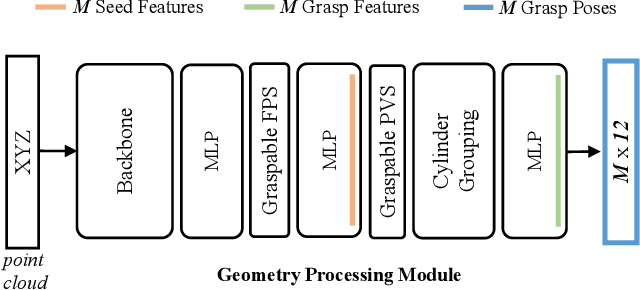
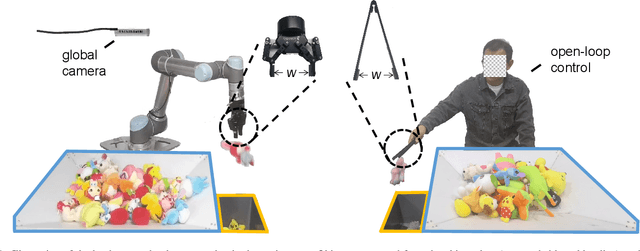
As the basis for prehensile manipulation, it is vital to enable robots to grasp as robustly as humans. In daily manipulation, our grasping system is prompt, accurate, flexible and continuous across spatial and temporal domains. Few existing methods cover all these properties for robot grasping. In this paper, we propose a new methodology for grasp perception to enable robots these abilities. Specifically, we develop a dense supervision strategy with real perception and analytic labels in the spatial-temporal domain. Additional awareness of objects' center-of-mass is incorporated into the learning process to help improve grasping stability. Utilization of grasp correspondence across observations enables dynamic grasp tracking. Our model, AnyGrasp, can generate accurate, full-DoF, dense and temporally-smooth grasp poses efficiently, and works robustly against large depth sensing noise. Embedded with AnyGrasp, we achieve a 93.3% success rate when clearing bins with over 300 unseen objects, which is comparable with human subjects under controlled conditions. Over 900 MPPH is reported on a single-arm system. For dynamic grasping, we demonstrate catching swimming robot fish in the water.
A Composable Framework for Policy Design, Learning, and Transfer Toward Safe and Efficient Industrial Insertion
Mar 06, 2022
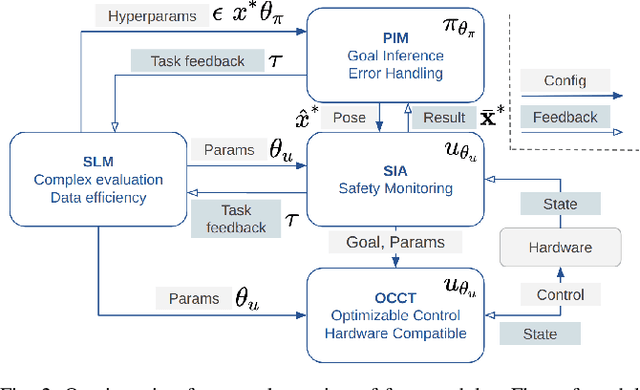
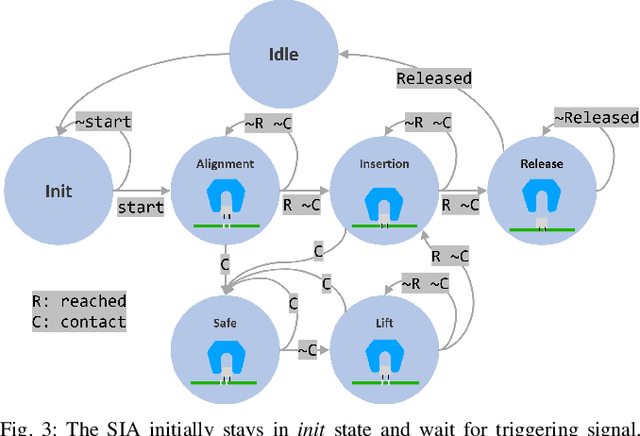
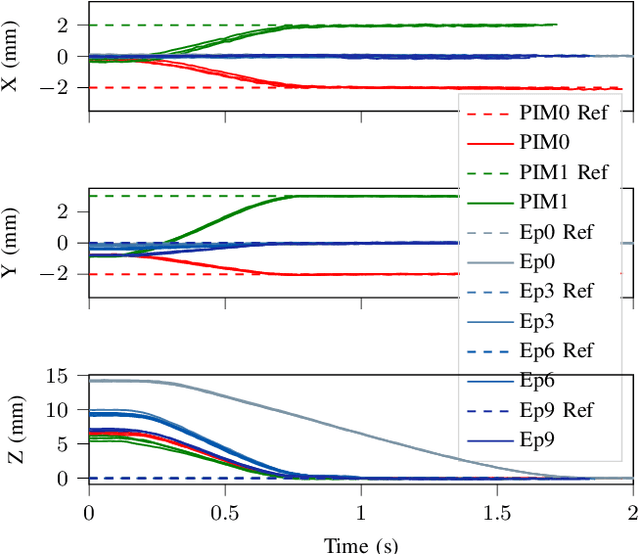
Delicate industrial insertion tasks (e.g., PC board assembly) remain challenging for industrial robots. The challenges include low error tolerance, delicacy of the components, and large task variations with respect to the components to be inserted. To deliver a feasible robotic solution for these insertion tasks, we also need to account for hardware limits of existing robotic systems and minimize the integration effort. This paper proposes a composable framework for efficient integration of a safe insertion policy on existing robotic platforms to accomplish these insertion tasks. The policy has an interpretable modularized design and can be learned efficiently on hardware and transferred to new tasks easily. In particular, the policy includes a safe insertion agent as a baseline policy for insertion, an optimal configurable Cartesian tracker as an interface to robot hardware, a probabilistic inference module to handle component variety and insertion errors, and a safe learning module to optimize the parameters in the aforementioned modules to achieve the best performance on designated hardware. The experiment results on a UR10 robot show that the proposed framework achieves safety (for the delicacy of components), accuracy (for low tolerance), robustness (against perception error and component defection), adaptability and transferability (for task variations), as well as task efficiency during execution plus data and time efficiency during learning.