 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChin-Hui Lee
A Study of Dropout-Induced Modality Bias on Robustness to Missing Video Frames for Audio-Visual Speech Recognition
Mar 07, 2024
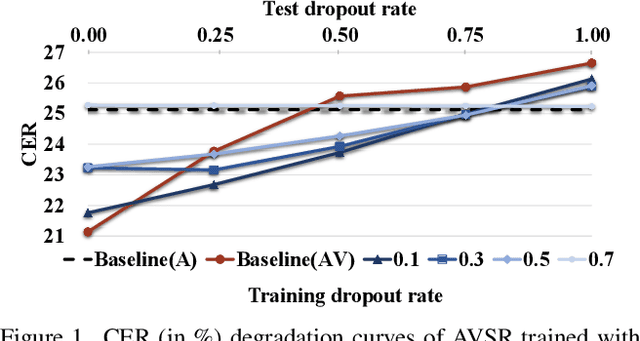

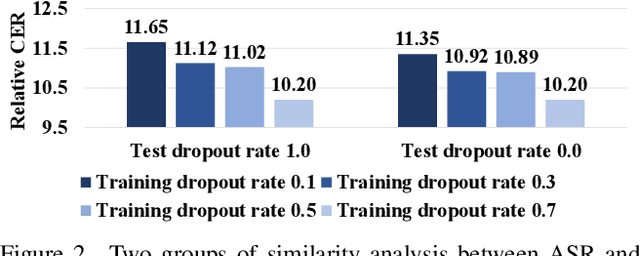
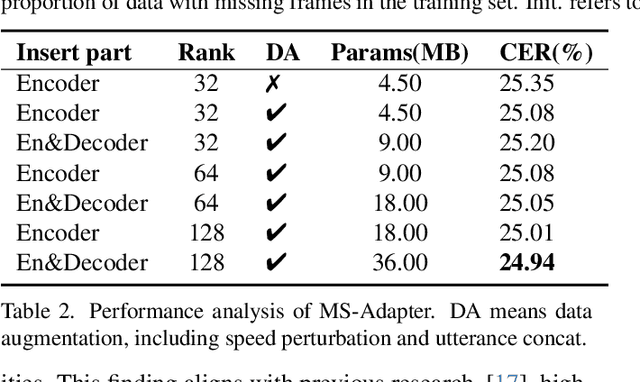
Advanced Audio-Visual Speech Recognition (AVSR) systems have been observed to be sensitive to missing video frames, performing even worse than single-modality models. While applying the dropout technique to the video modality enhances robustness to missing frames, it simultaneously results in a performance loss when dealing with complete data input. In this paper, we investigate this contrasting phenomenon from the perspective of modality bias and reveal that an excessive modality bias on the audio caused by dropout is the underlying reason. Moreover, we present the Modality Bias Hypothesis (MBH) to systematically describe the relationship between modality bias and robustness against missing modality in multimodal systems. Building on these findings, we propose a novel Multimodal Distribution Approximation with Knowledge Distillation (MDA-KD) framework to reduce over-reliance on the audio modality and to maintain performance and robustness simultaneously. Finally, to address an entirely missing modality, we adopt adapters to dynamically switch decision strategies. The effectiveness of our proposed approach is evaluated and validated through a series of comprehensive experiments using the MISP2021 and MISP2022 datasets. Our code is available at https://github.com/dalision/ModalBiasAVSR
Bayesian adaptive learning to latent variables via Variational Bayes and Maximum a Posteriori
Jan 24, 2024In this work, we aim to establish a Bayesian adaptive learning framework by focusing on estimating latent variables in deep neural network (DNN) models. Latent variables indeed encode both transferable distributional information and structural relationships. Thus the distributions of the source latent variables (prior) can be combined with the knowledge learned from the target data (likelihood) to yield the distributions of the target latent variables (posterior) with the goal of addressing acoustic mismatches between training and testing conditions. The prior knowledge transfer is accomplished through Variational Bayes (VB). In addition, we also investigate Maximum a Posteriori (MAP) based Bayesian adaptation. Experimental results on device adaptation in acoustic scene classification show that our proposed approaches can obtain good improvements on target devices, and consistently outperforms other cut-edging algorithms.
Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding with Sequence-to-Sequence Architecture
Sep 17, 2023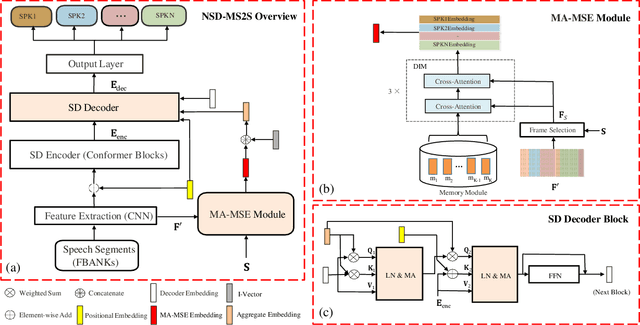
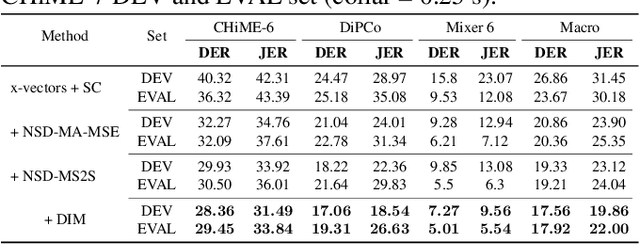
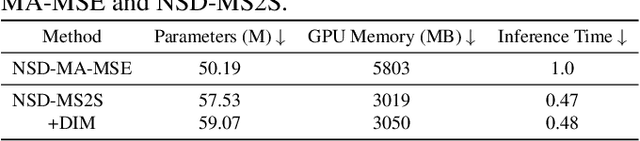
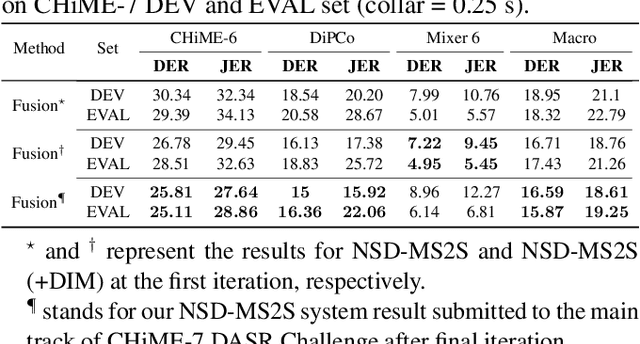
We propose a novel neural speaker diarization system using memory-aware multi-speaker embedding with sequence-to-sequence architecture (NSD-MS2S), which integrates the strengths of memory-aware multi-speaker embedding (MA-MSE) and sequence-to-sequence (Seq2Seq) architecture, leading to improvement in both efficiency and performance. Next, we further decrease the memory occupation of decoding by incorporating input features fusion and then employ a multi-head attention mechanism to capture features at different levels. NSD-MS2S achieved a macro diarization error rate (DER) of 15.9% on the CHiME-7 EVAL set, which signifies a relative improvement of 49% over the official baseline system, and is the key technique for us to achieve the best performance for the main track of CHiME-7 DASR Challenge. Additionally, we introduce a deep interactive module (DIM) in MA-MSE module to better retrieve a cleaner and more discriminative multi-speaker embedding, enabling the current model to outperform the system we used in the CHiME-7 DASR Challenge. Our code will be available at https://github.com/liyunlongaaa/NSD-MS2S.
Boosting End-to-End Multilingual Phoneme Recognition through Exploiting Universal Speech Attributes Constraints
Sep 16, 2023



We propose a first step toward multilingual end-to-end automatic speech recognition (ASR) by integrating knowledge about speech articulators. The key idea is to leverage a rich set of fundamental units that can be defined "universally" across all spoken languages, referred to as speech attributes, namely manner and place of articulation. Specifically, several deterministic attribute-to-phoneme mapping matrices are constructed based on the predefined set of universal attribute inventory, which projects the knowledge-rich articulatory attribute logits, into output phoneme logits. The mapping puts knowledge-based constraints to limit inconsistency with acoustic-phonetic evidence in the integrated prediction. Combined with phoneme recognition, our phone recognizer is able to infer from both attribute and phoneme information. The proposed joint multilingual model is evaluated through phoneme recognition. In multilingual experiments over 6 languages on benchmark datasets LibriSpeech and CommonVoice, we find that our proposed solution outperforms conventional multilingual approaches with a relative improvement of 6.85% on average, and it also demonstrates a much better performance compared to monolingual model. Further analysis conclusively demonstrates that the proposed solution eliminates phoneme predictions that are inconsistent with attributes.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023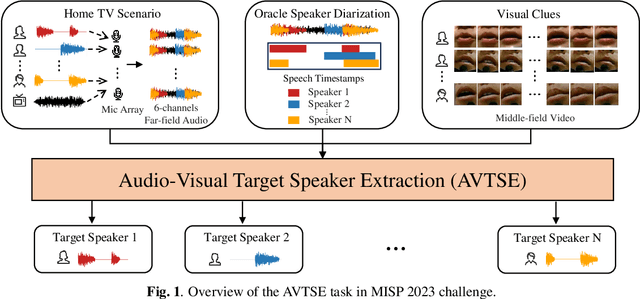
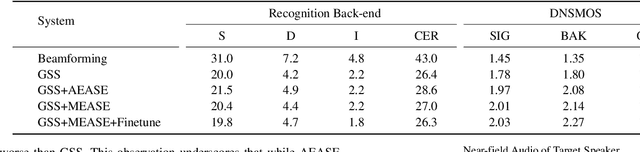
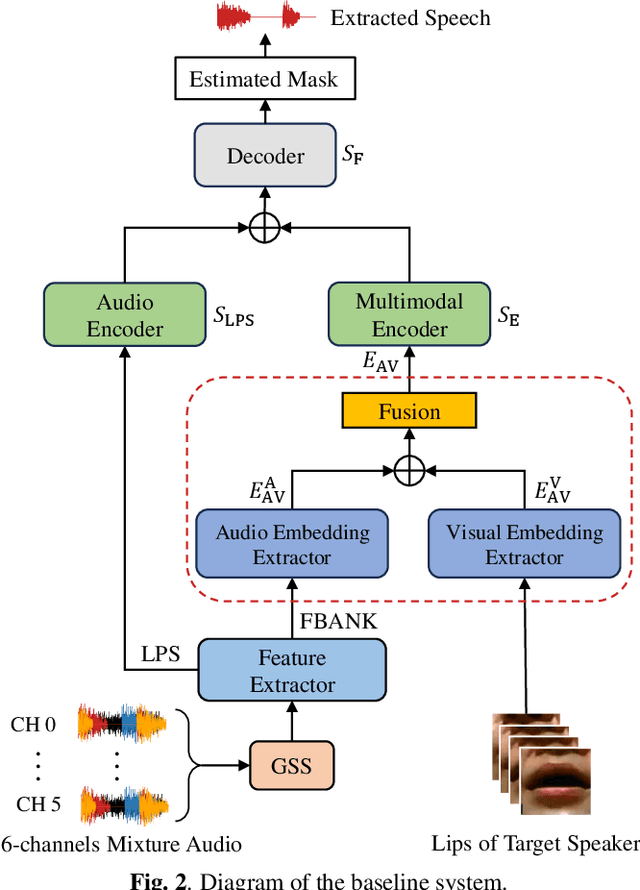
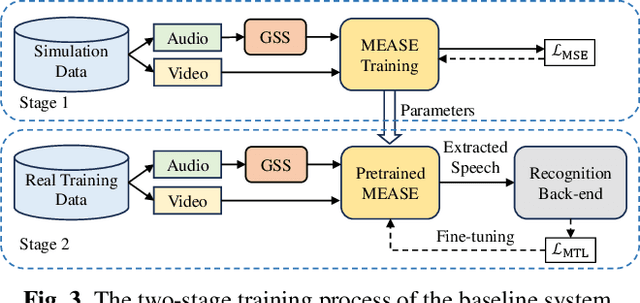
Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023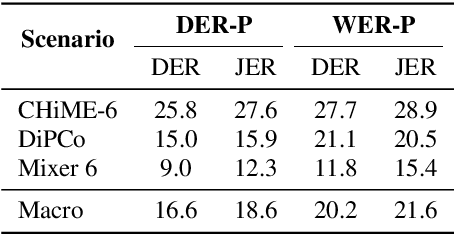
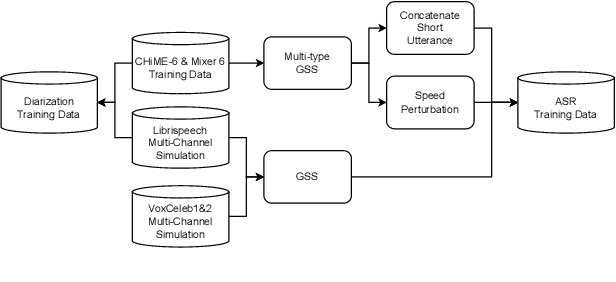
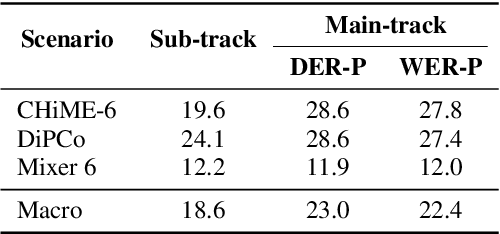
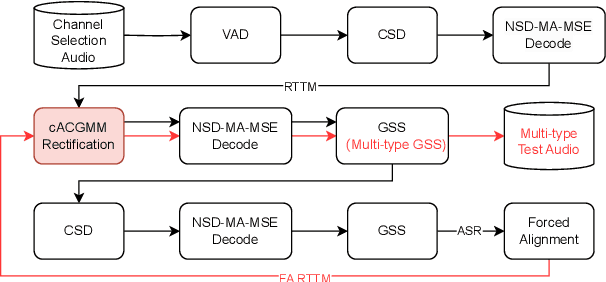
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
Improving Audio-Visual Speech Recognition by Lip-Subword Correlation Based Visual Pre-training and Cross-Modal Fusion Encoder
Aug 14, 2023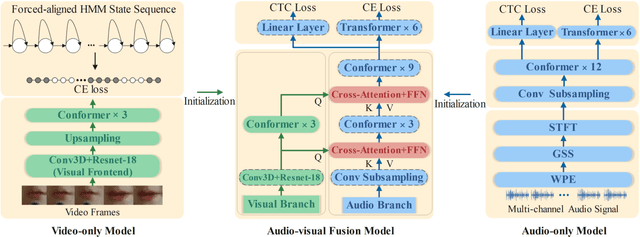
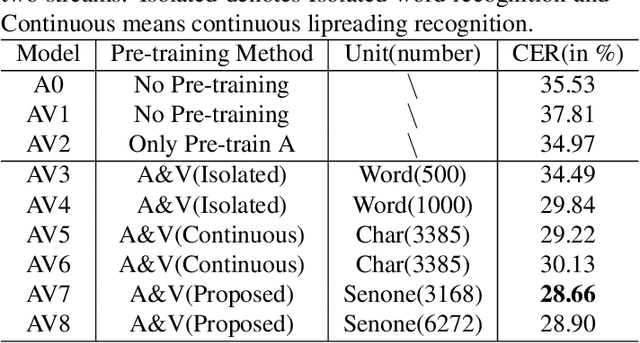
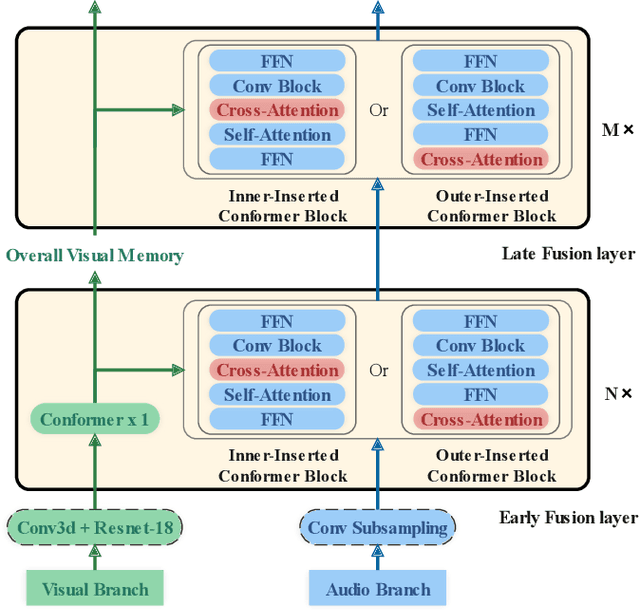
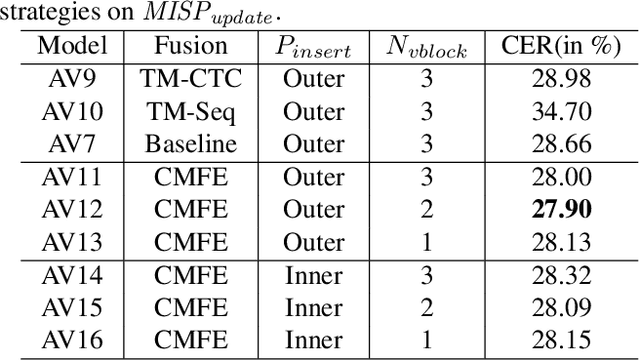
In recent research, slight performance improvement is observed from automatic speech recognition systems to audio-visual speech recognition systems in the end-to-end framework with low-quality videos. Unmatching convergence rates and specialized input representations between audio and visual modalities are considered to cause the problem. In this paper, we propose two novel techniques to improve audio-visual speech recognition (AVSR) under a pre-training and fine-tuning training framework. First, we explore the correlation between lip shapes and syllable-level subword units in Mandarin to establish good frame-level syllable boundaries from lip shapes. This enables accurate alignment of video and audio streams during visual model pre-training and cross-modal fusion. Next, we propose an audio-guided cross-modal fusion encoder (CMFE) neural network to utilize main training parameters for multiple cross-modal attention layers to make full use of modality complementarity. Experiments on the MISP2021-AVSR data set show the effectiveness of the two proposed techniques. Together, using only a relatively small amount of training data, the final system achieves better performances than state-of-the-art systems with more complex front-ends and back-ends.
Semi-supervised multi-channel speaker diarization with cross-channel attention
Jul 17, 2023



Most neural speaker diarization systems rely on sufficient manual training data labels, which are hard to collect under real-world scenarios. This paper proposes a semi-supervised speaker diarization system to utilize large-scale multi-channel training data by generating pseudo-labels for unlabeled data. Furthermore, we introduce cross-channel attention into the Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding (NSD-MA-MSE) to learn channel contextual information of speaker embeddings better. Experimental results on the CHiME-7 Mixer6 dataset which only contains partial speakers' labels of the training set, show that our system achieved 57.01% relative DER reduction compared to the clustering-based model on the development set. We further conducted experiments on the CHiME-6 dataset to simulate the scenario of missing partial training set labels. When using 80% and 50% labeled training data, our system performs comparably to the results obtained using 100% labeled data for training.
Variance-Preserving-Based Interpolation Diffusion Models for Speech Enhancement
Jun 14, 2023



The goal of this study is to implement diffusion models for speech enhancement (SE). The first step is to emphasize the theoretical foundation of variance-preserving (VP)-based interpolation diffusion under continuous conditions. Subsequently, we present a more concise framework that encapsulates both the VP- and variance-exploding (VE)-based interpolation diffusion methods. We demonstrate that these two methods are special cases of the proposed framework. Additionally, we provide a practical example of VP-based interpolation diffusion for the SE task. To improve performance and ease model training, we analyze the common difficulties encountered in diffusion models and suggest amenable hyper-parameters. Finally, we evaluate our model against several methods using a public benchmark to showcase the effectiveness of our approach
A Multi-dimensional Deep Structured State Space Approach to Speech Enhancement Using Small-footprint Models
Jun 01, 2023



We propose a multi-dimensional structured state space (S4) approach to speech enhancement. To better capture the spectral dependencies across the frequency axis, we focus on modifying the multi-dimensional S4 layer with whitening transformation to build new small-footprint models that also achieve good performance. We explore several S4-based deep architectures in time (T) and time-frequency (TF) domains. The 2-D S4 layer can be considered a particular convolutional layer with an infinite receptive field although it utilizes fewer parameters than a conventional convolutional layer. Evaluated on the VoiceBank-DEMAND data set, when compared with the conventional U-net model based on convolutional layers, the proposed TF-domain S4-based model is 78.6% smaller in size, yet it still achieves competitive results with a PESQ score of 3.15 with data augmentation. By increasing the model size, we can even reach a PESQ score of 3.18.