 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianqing Gao
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023
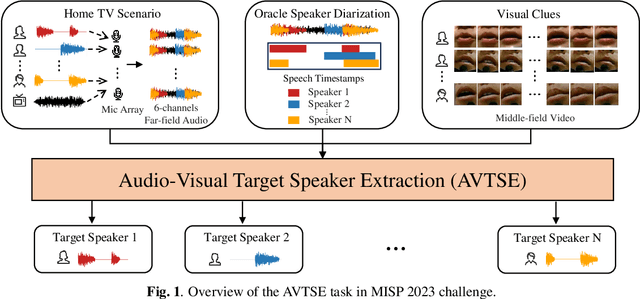
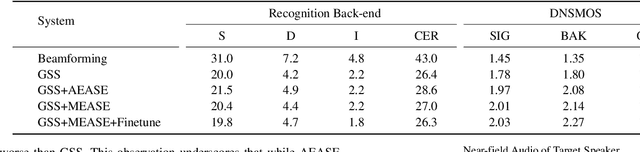
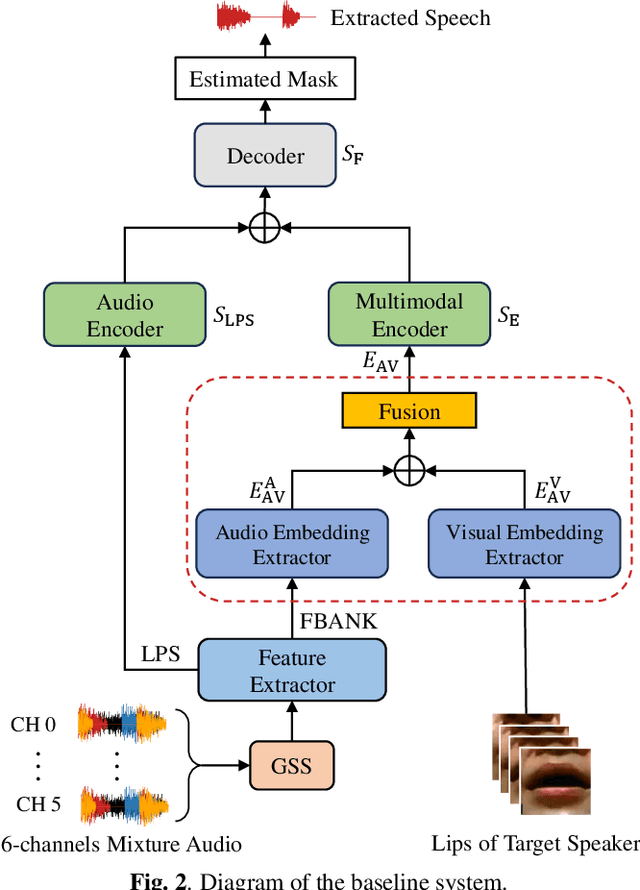
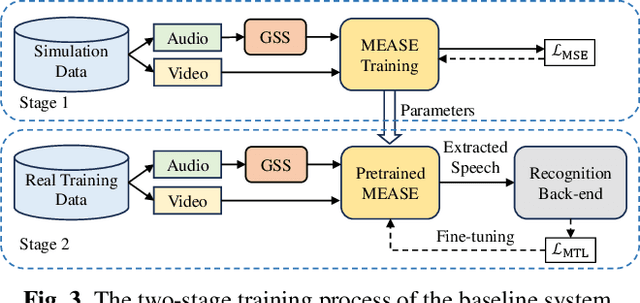
Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
The USTC-NERCSLIP Systems for the CHiME-7 DASR Challenge
Aug 28, 2023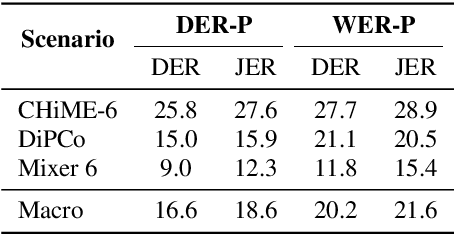
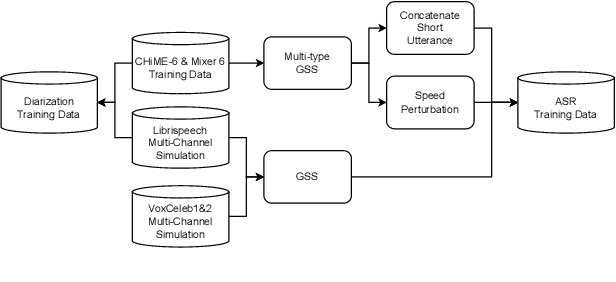
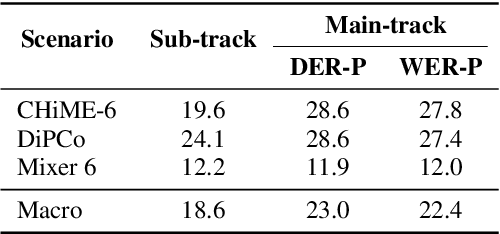
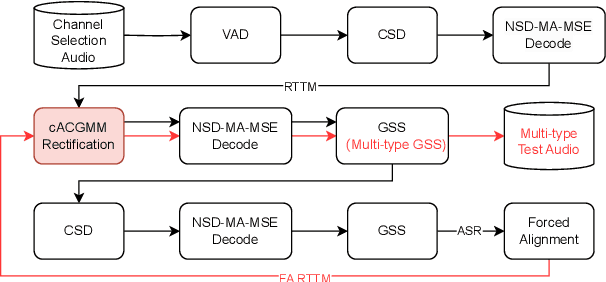
This technical report details our submission system to the CHiME-7 DASR Challenge, which focuses on speaker diarization and speech recognition under complex multi-speaker settings. Additionally, it also evaluates the efficiency of systems in handling diverse array devices. To address these issues, we implemented an end-to-end speaker diarization system and introduced a rectification strategy based on multi-channel spatial information. This approach significantly diminished the word error rates (WER). In terms of recognition, we utilized publicly available pre-trained models as the foundational models to train our end-to-end speech recognition models. Our system attained a macro-averaged diarization-attributed WER (DA-WER) of 22.4\% on the CHiME-7 development set, which signifies a relative improvement of 52.5\% over the official baseline system.
Improved Speech Pre-Training with Supervision-Enhanced Acoustic Unit
Dec 07, 2022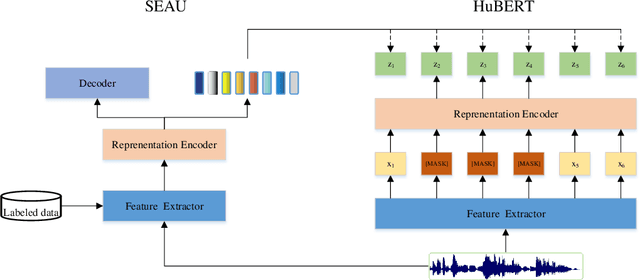
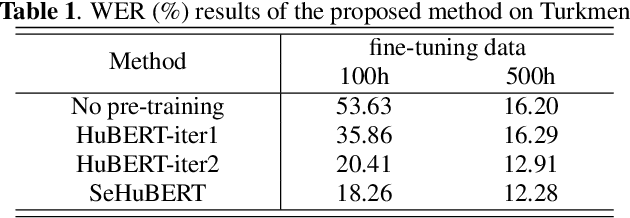


Speech pre-training has shown great success in learning useful and general latent representations from large-scale unlabeled data. Based on a well-designed self-supervised learning pattern, pre-trained models can be used to serve lots of downstream speech tasks such as automatic speech recognition. In order to take full advantage of the labed data in low resource task, we present an improved pre-training method by introducing a supervision-enhanced acoustic unit (SEAU) pattern to intensify the expression of comtext information and ruduce the training cost. Encoder representations extracted from the SEAU pattern are used to generate more representative target units for HuBERT pre-training process. The proposed method, named SeHuBERT, achieves a relative word error rate reductions of 10.5% and 4.9% comared with the standard HuBERT on Turkmen speech recognition task with 500 hours and 100 hours fine-tuning data respectively. Extended to more languages and more data, SeHuBERT can aslo achieve a relative word error rate reductions of approximately 10% at half of the training cost compared with HuBERT.
Self-Supervised Audio-Visual Speech Representations Learning By Multimodal Self-Distillation
Dec 06, 2022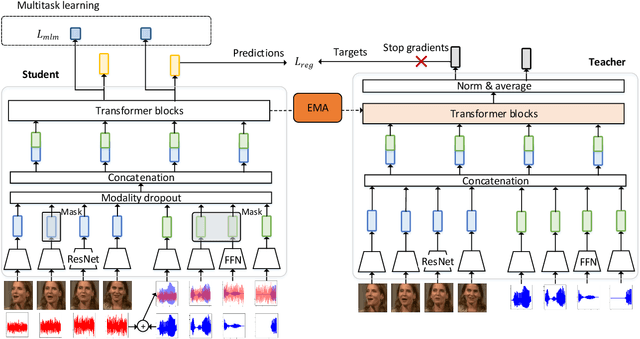
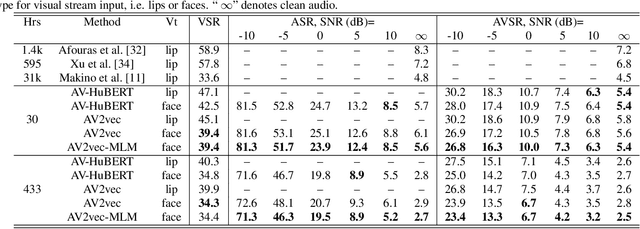
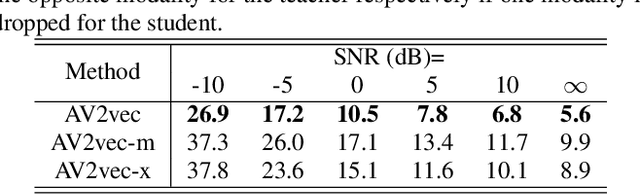
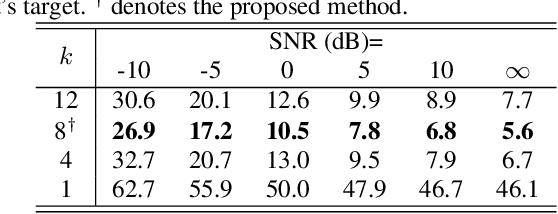
In this work, we present a novel method, named AV2vec, for learning audio-visual speech representations by multimodal self-distillation. AV2vec has a student and a teacher module, in which the student performs a masked latent feature regression task using the multimodal target features generated online by the teacher. The parameters of the teacher model are a momentum update of the student. Since our target features are generated online, AV2vec needs no iteration step like AV-HuBERT and the total training time cost is reduced to less than one-fifth. We further propose AV2vec-MLM in this study, which augments AV2vec with a masked language model (MLM)-style loss using multitask learning. Our experimental results show that AV2vec achieved comparable performance to the AV-HuBERT baseline. When combined with an MLM-style loss, AV2vec-MLM outperformed baselines and achieved the best performance on the downstream tasks.