 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQingpei Guo
SHE-Net: Syntax-Hierarchy-Enhanced Text-Video Retrieval
Apr 22, 2024
The user base of short video apps has experienced unprecedented growth in recent years, resulting in a significant demand for video content analysis. In particular, text-video retrieval, which aims to find the top matching videos given text descriptions from a vast video corpus, is an essential function, the primary challenge of which is to bridge the modality gap. Nevertheless, most existing approaches treat texts merely as discrete tokens and neglect their syntax structures. Moreover, the abundant spatial and temporal clues in videos are often underutilized due to the lack of interaction with text. To address these issues, we argue that using texts as guidance to focus on relevant temporal frames and spatial regions within videos is beneficial. In this paper, we propose a novel Syntax-Hierarchy-Enhanced text-video retrieval method (SHE-Net) that exploits the inherent semantic and syntax hierarchy of texts to bridge the modality gap from two perspectives. First, to facilitate a more fine-grained integration of visual content, we employ the text syntax hierarchy, which reveals the grammatical structure of text descriptions, to guide the visual representations. Second, to further enhance the multi-modal interaction and alignment, we also utilize the syntax hierarchy to guide the similarity calculation. We evaluated our method on four public text-video retrieval datasets of MSR-VTT, MSVD, DiDeMo, and ActivityNet. The experimental results and ablation studies confirm the advantages of our proposed method.
M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining
Feb 04, 2024Vision-language foundation models like CLIP have revolutionized the field of artificial intelligence. Nevertheless, VLM models supporting multi-language, e.g., in both Chinese and English, have lagged due to the relative scarcity of large-scale pretraining datasets. Toward this end, we introduce a comprehensive bilingual (Chinese-English) dataset BM-6B with over 6 billion image-text pairs, aimed at enhancing multimodal foundation models to well understand images in both languages. To handle such a scale of dataset, we propose a novel grouped aggregation approach for image-text contrastive loss computation, which reduces the communication overhead and GPU memory demands significantly, facilitating a 60% increase in training speed. We pretrain a series of bilingual image-text foundation models with an enhanced fine-grained understanding ability on BM-6B, the resulting models, dubbed as $M^2$-Encoders (pronounced "M-Square"), set new benchmarks in both languages for multimodal retrieval and classification tasks. Notably, Our largest $M^2$-Encoder-10B model has achieved top-1 accuracies of 88.5% on ImageNet and 80.7% on ImageNet-CN under a zero-shot classification setting, surpassing previously reported SoTA methods by 2.2% and 21.1%, respectively. The $M^2$-Encoder series represents one of the most comprehensive bilingual image-text foundation models to date, so we are making it available to the research community for further exploration and development.
SNP-S3: Shared Network Pre-training and Significant Semantic Strengthening for Various Video-Text Tasks
Jan 31, 2024We present a framework for learning cross-modal video representations by directly pre-training on raw data to facilitate various downstream video-text tasks. Our main contributions lie in the pre-training framework and proxy tasks. First, based on the shortcomings of two mainstream pixel-level pre-training architectures (limited applications or less efficient), we propose Shared Network Pre-training (SNP). By employing one shared BERT-type network to refine textual and cross-modal features simultaneously, SNP is lightweight and could support various downstream applications. Second, based on the intuition that people always pay attention to several "significant words" when understanding a sentence, we propose the Significant Semantic Strengthening (S3) strategy, which includes a novel masking and matching proxy task to promote the pre-training performance. Experiments conducted on three downstream video-text tasks and six datasets demonstrate that, we establish a new state-of-the-art in pixel-level video-text pre-training; we also achieve a satisfactory balance between the pre-training efficiency and the fine-tuning performance. The codebase are available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/snps3_vtp.
M2-RAAP: A Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards Effective and Efficient Zero-shot Video-text Retrieval
Jan 31, 2024We present a Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards effective and efficient zero-shot video-text retrieval, dubbed M2-RAAP. Upon popular image-text models like CLIP, most current adaptation-based video-text pre-training methods are confronted by three major issues, i.e., noisy data corpus, time-consuming pre-training, and limited performance gain. Towards this end, we conduct a comprehensive study including four critical steps in video-text pre-training. Specifically, we investigate 1) data filtering and refinement, 2) video input type selection, 3) temporal modeling, and 4) video feature enhancement. We then summarize this empirical study into the M2-RAAP recipe, where our technical contributions lie in 1) the data filtering and text re-writing pipeline resulting in 1M high-quality bilingual video-text pairs, 2) the replacement of video inputs with key-frames to accelerate pre-training, and 3) the Auxiliary-Caption-Guided (ACG) strategy to enhance video features. We conduct extensive experiments by adapting three image-text foundation models on two refined video-text datasets from different languages, validating the robustness and reproducibility of M2-RAAP for adaptation-based pre-training. Results demonstrate that M2-RAAP yields superior performance with significantly reduced data (-90%) and time consumption (-95%), establishing a new SOTA on four English zero-shot retrieval datasets and two Chinese ones. We are preparing our refined bilingual data annotations and codebase, which will be available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/M2_RAAP.
Knowledge-enhanced Multi-perspective Video Representation Learning for Scene Recognition
Jan 09, 2024With the explosive growth of video data in real-world applications, a comprehensive representation of videos becomes increasingly important. In this paper, we address the problem of video scene recognition, whose goal is to learn a high-level video representation to classify scenes in videos. Due to the diversity and complexity of video contents in realistic scenarios, this task remains a challenge. Most existing works identify scenes for videos only from visual or textual information in a temporal perspective, ignoring the valuable information hidden in single frames, while several earlier studies only recognize scenes for separate images in a non-temporal perspective. We argue that these two perspectives are both meaningful for this task and complementary to each other, meanwhile, externally introduced knowledge can also promote the comprehension of videos. We propose a novel two-stream framework to model video representations from multiple perspectives, i.e. temporal and non-temporal perspectives, and integrate the two perspectives in an end-to-end manner by self-distillation. Besides, we design a knowledge-enhanced feature fusion and label prediction method that contributes to naturally introducing knowledge into the task of video scene recognition. Experiments conducted on a real-world dataset demonstrate the effectiveness of our proposed method.
SyCoCa: Symmetrizing Contrastive Captioners with Attentive Masking for Multimodal Alignment
Jan 04, 2024Multimodal alignment between language and vision is the fundamental topic in current vision-language model research. Contrastive Captioners (CoCa), as a representative method, integrates Contrastive Language-Image Pretraining (CLIP) and Image Caption (IC) into a unified framework, resulting in impressive results. CLIP imposes a bidirectional constraints on global representation of entire images and sentences. Although IC conducts an unidirectional image-to-text generation on local representation, it lacks any constraint on local text-to-image reconstruction, which limits the ability to understand images at a fine-grained level when aligned with texts. To achieve multimodal alignment from both global and local perspectives, this paper proposes Symmetrizing Contrastive Captioners (SyCoCa), which introduces bidirectional interactions on images and texts across the global and local representation levels. Specifically, we expand a Text-Guided Masked Image Modeling (TG-MIM) head based on ITC and IC heads. The improved SyCoCa can further leverage textual cues to reconstruct contextual images and visual cues to predict textual contents. When implementing bidirectional local interactions, the local contents of images tend to be cluttered or unrelated to their textual descriptions. Thus, we employ an attentive masking strategy to select effective image patches for interaction. Extensive experiments on five vision-language tasks, including image-text retrieval, image-captioning, visual question answering, and zero-shot/finetuned image classification, validate the effectiveness of our proposed method.
Text as Image: Learning Transferable Adapter for Multi-Label Classification
Dec 07, 2023Pre-trained vision-language models have notably accelerated progress of open-world concept recognition. Their impressive zero-shot ability has recently been transferred to multi-label image classification via prompt tuning, enabling to discover novel labels in an open-vocabulary manner. However, this paradigm suffers from non-trivial training costs, and becomes computationally prohibitive for a large number of candidate labels. To address this issue, we note that vision-language pre-training aligns images and texts in a unified embedding space, making it potential for an adapter network to identify labels in visual modality while be trained in text modality. To enhance such cross-modal transfer ability, a simple yet effective method termed random perturbation is proposed, which enables the adapter to search for potential visual embeddings by perturbing text embeddings with noise during training, resulting in better performance in visual modality. Furthermore, we introduce an effective approach to employ large language models for multi-label instruction-following text generation. In this way, a fully automated pipeline for visual label recognition is developed without relying on any manual data. Extensive experiments on public benchmarks show the superiority of our method in various multi-label classification tasks.
Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs
Oct 01, 2023Multi-modal Large Language Models (MLLMs) have shown remarkable capabilities in many vision-language tasks. Nevertheless, most MLLMs still lack the Referential Comprehension (RC) ability to identify a specific object or area in images, limiting their application in fine-grained perception tasks. This paper proposes a novel method to enhance the RC capability for MLLMs. Our model represents the referring object in the image using the coordinates of its bounding box and converts the coordinates into texts in a specific format. This allows the model to treat the coordinates as natural language. Moreover, we construct the instruction tuning dataset with various designed RC tasks at a low cost by unleashing the potential of annotations in existing datasets. To further boost the RC ability of the model, we propose a self-consistent bootstrapping method that extends dense object annotations of a dataset into high-quality referring-expression-bounding-box pairs. The model is trained end-to-end with a parameter-efficient tuning framework that allows both modalities to benefit from multi-modal instruction tuning. This framework requires fewer trainable parameters and less training data. Experimental results on conventional vision-language and RC tasks demonstrate the superior performance of our method. For instance, our model exhibits a 12.0% absolute accuracy improvement over Instruct-BLIP on VSR and surpasses Kosmos-2 by 24.7% on RefCOCO_val under zero-shot settings. We also attain the top position on the leaderboard of MMBench. The models, datasets, and codes are publicly available at https://github.com/SY-Xuan/Pink
Dual-Modal Attention-Enhanced Text-Video Retrieval with Triplet Partial Margin Contrastive Learning
Sep 20, 2023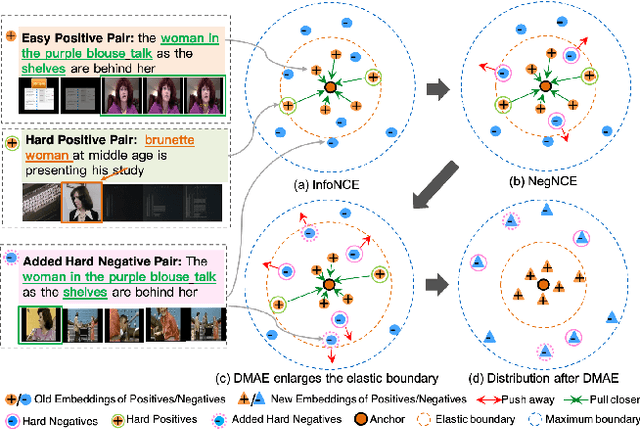
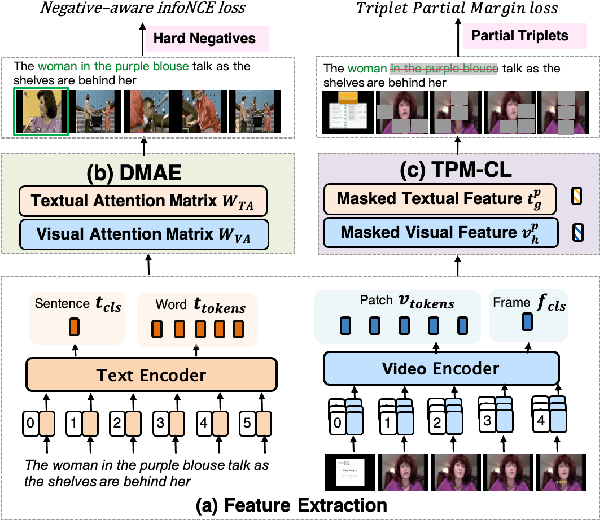
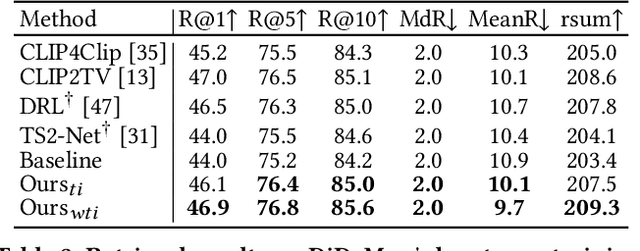
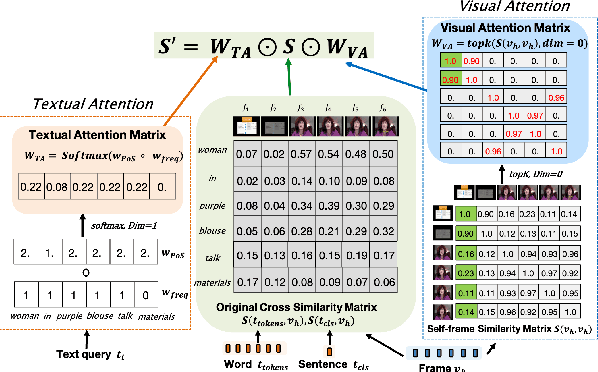
In recent years, the explosion of web videos makes text-video retrieval increasingly essential and popular for video filtering, recommendation, and search. Text-video retrieval aims to rank relevant text/video higher than irrelevant ones. The core of this task is to precisely measure the cross-modal similarity between texts and videos. Recently, contrastive learning methods have shown promising results for text-video retrieval, most of which focus on the construction of positive and negative pairs to learn text and video representations. Nevertheless, they do not pay enough attention to hard negative pairs and lack the ability to model different levels of semantic similarity. To address these two issues, this paper improves contrastive learning using two novel techniques. First, to exploit hard examples for robust discriminative power, we propose a novel Dual-Modal Attention-Enhanced Module (DMAE) to mine hard negative pairs from textual and visual clues. By further introducing a Negative-aware InfoNCE (NegNCE) loss, we are able to adaptively identify all these hard negatives and explicitly highlight their impacts in the training loss. Second, our work argues that triplet samples can better model fine-grained semantic similarity compared to pairwise samples. We thereby present a new Triplet Partial Margin Contrastive Learning (TPM-CL) module to construct partial order triplet samples by automatically generating fine-grained hard negatives for matched text-video pairs. The proposed TPM-CL designs an adaptive token masking strategy with cross-modal interaction to model subtle semantic differences. Extensive experiments demonstrate that the proposed approach outperforms existing methods on four widely-used text-video retrieval datasets, including MSR-VTT, MSVD, DiDeMo and ActivityNet.
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints
Aug 21, 2023



Motivated by the superior performance of image diffusion models, more and more researchers strive to extend these models to the text-based video editing task. Nevertheless, current video editing tasks mainly suffer from the dilemma between the high fine-tuning cost and the limited generation capacity. Compared with images, we conjecture that videos necessitate more constraints to preserve the temporal consistency during editing. Towards this end, we propose EVE, a robust and efficient zero-shot video editing method. Under the guidance of depth maps and temporal consistency constraints, EVE derives satisfactory video editing results with an affordable computational and time cost. Moreover, recognizing the absence of a publicly available video editing dataset for fair comparisons, we construct a new benchmark ZVE-50 dataset. Through comprehensive experimentation, we validate that EVE could achieve a satisfactory trade-off between performance and efficiency. We will release our dataset and codebase to facilitate future researchers.