 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhongyi Liu
Multi-Intent Attribute-Aware Text Matching in Searching
Feb 12, 2024
Text matching systems have become a fundamental service in most searching platforms. For instance, they are responsible for matching user queries to relevant candidate items, or rewriting the user-input query to a pre-selected high-performing one for a better search experience. In practice, both the queries and items often contain multiple attributes, such as the category of the item and the location mentioned in the query, which represent condensed key information that is helpful for matching. However, most of the existing works downplay the effectiveness of attributes by integrating them into text representations as supplementary information. Hence, in this work, we focus on exploring the relationship between the attributes from two sides. Since attributes from two ends are often not aligned in terms of number and type, we propose to exploit the benefit of attributes by multiple-intent modeling. The intents extracted from attributes summarize the diverse needs of queries and provide rich content of items, which are more refined and abstract, and can be aligned for paired inputs. Concretely, we propose a multi-intent attribute-aware matching model (MIM), which consists of three main components: attribute-aware encoder, multi-intent modeling, and intent-aware matching. In the attribute-aware encoder, the text and attributes are weighted and processed through a scaled attention mechanism with regard to the attributes' importance. Afterward, the multi-intent modeling extracts intents from two ends and aligns them. Herein, we come up with a distribution loss to ensure the learned intents are diverse but concentrated, and a kullback-leibler divergence loss that aligns the learned intents. Finally, in the intent-aware matching, the intents are evaluated by a self-supervised masking task, and then incorporated to output the final matching result.
A Multi-Granularity-Aware Aspect Learning Model for Multi-Aspect Dense Retrieval
Dec 05, 2023

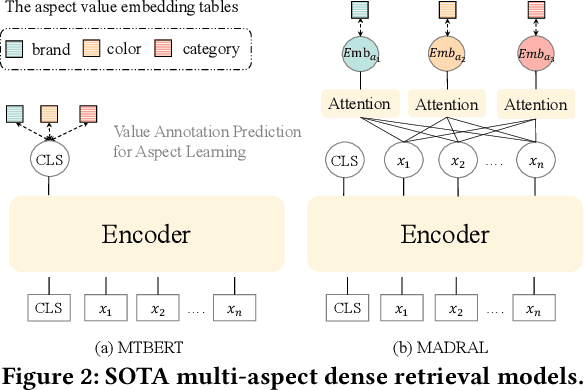

Dense retrieval methods have been mostly focused on unstructured text and less attention has been drawn to structured data with various aspects, e.g., products with aspects such as category and brand. Recent work has proposed two approaches to incorporate the aspect information into item representations for effective retrieval by predicting the values associated with the item aspects. Despite their efficacy, they treat the values as isolated classes (e.g., "Smart Homes", "Home, Garden & Tools", and "Beauty & Health") and ignore their fine-grained semantic relation. Furthermore, they either enforce the learning of aspects into the CLS token, which could confuse it from its designated use for representing the entire content semantics, or learn extra aspect embeddings only with the value prediction objective, which could be insufficient especially when there are no annotated values for an item aspect. Aware of these limitations, we propose a MUlti-granulaRity-aware Aspect Learning model (MURAL) for multi-aspect dense retrieval. It leverages aspect information across various granularities to capture both coarse and fine-grained semantic relations between values. Moreover, MURAL incorporates separate aspect embeddings as input to transformer encoders so that the masked language model objective can assist implicit aspect learning even without aspect-value annotations. Extensive experiments on two real-world datasets of products and mini-programs show that MURAL outperforms state-of-the-art baselines significantly.
Dual-Modal Attention-Enhanced Text-Video Retrieval with Triplet Partial Margin Contrastive Learning
Sep 20, 2023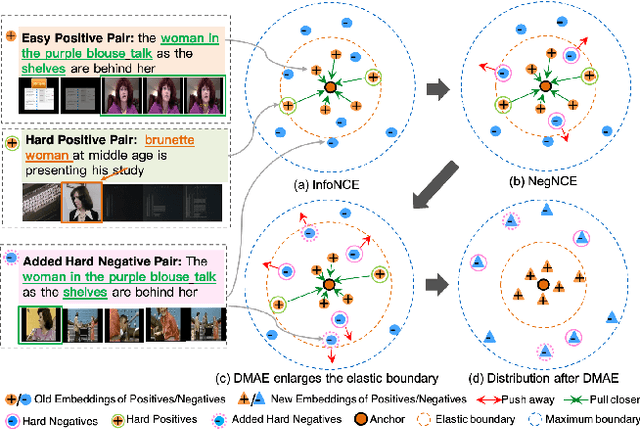
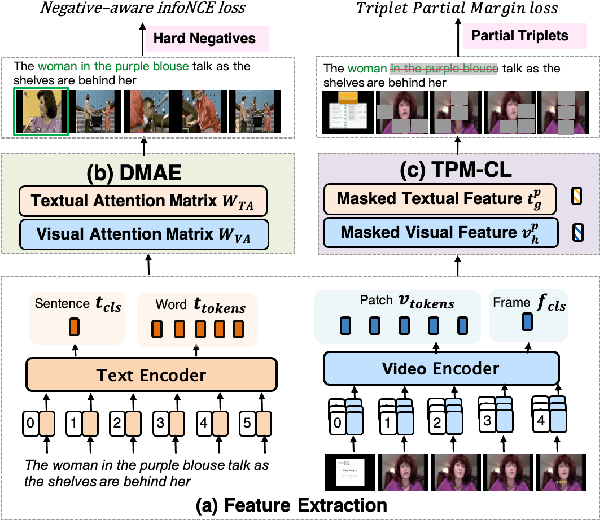
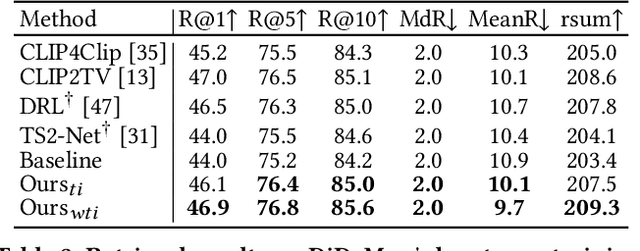
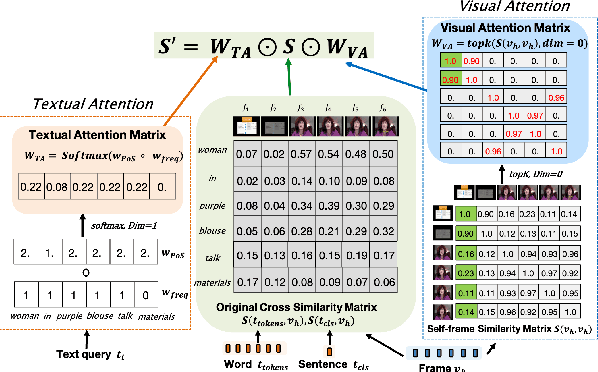
In recent years, the explosion of web videos makes text-video retrieval increasingly essential and popular for video filtering, recommendation, and search. Text-video retrieval aims to rank relevant text/video higher than irrelevant ones. The core of this task is to precisely measure the cross-modal similarity between texts and videos. Recently, contrastive learning methods have shown promising results for text-video retrieval, most of which focus on the construction of positive and negative pairs to learn text and video representations. Nevertheless, they do not pay enough attention to hard negative pairs and lack the ability to model different levels of semantic similarity. To address these two issues, this paper improves contrastive learning using two novel techniques. First, to exploit hard examples for robust discriminative power, we propose a novel Dual-Modal Attention-Enhanced Module (DMAE) to mine hard negative pairs from textual and visual clues. By further introducing a Negative-aware InfoNCE (NegNCE) loss, we are able to adaptively identify all these hard negatives and explicitly highlight their impacts in the training loss. Second, our work argues that triplet samples can better model fine-grained semantic similarity compared to pairwise samples. We thereby present a new Triplet Partial Margin Contrastive Learning (TPM-CL) module to construct partial order triplet samples by automatically generating fine-grained hard negatives for matched text-video pairs. The proposed TPM-CL designs an adaptive token masking strategy with cross-modal interaction to model subtle semantic differences. Extensive experiments demonstrate that the proposed approach outperforms existing methods on four widely-used text-video retrieval datasets, including MSR-VTT, MSVD, DiDeMo and ActivityNet.
An Unified Search and Recommendation Foundation Model for Cold-Start Scenario
Sep 16, 2023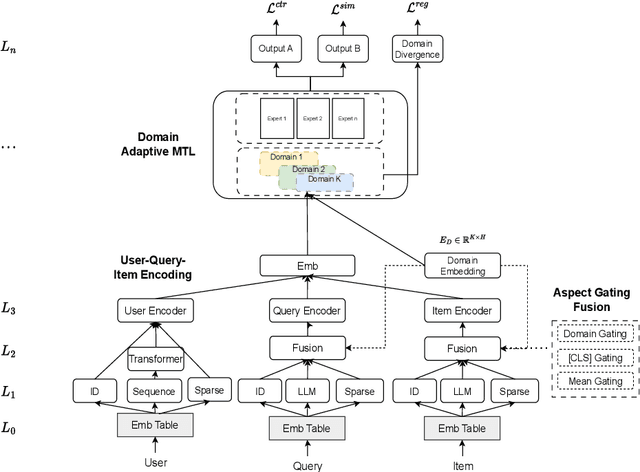
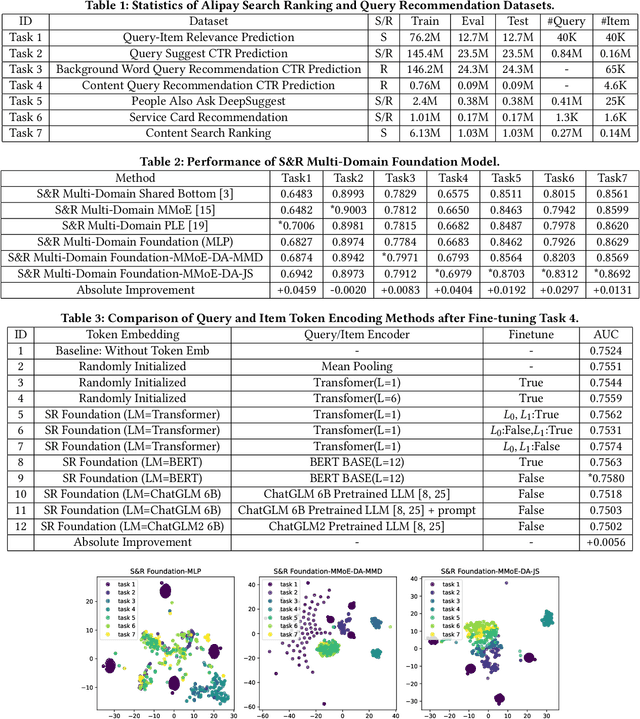
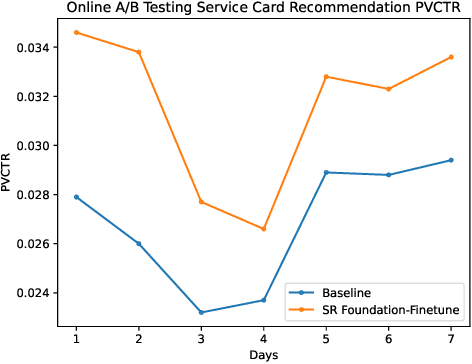
In modern commercial search engines and recommendation systems, data from multiple domains is available to jointly train the multi-domain model. Traditional methods train multi-domain models in the multi-task setting, with shared parameters to learn the similarity of multiple tasks, and task-specific parameters to learn the divergence of features, labels, and sample distributions of individual tasks. With the development of large language models, LLM can extract global domain-invariant text features that serve both search and recommendation tasks. We propose a novel framework called S\&R Multi-Domain Foundation, which uses LLM to extract domain invariant features, and Aspect Gating Fusion to merge the ID feature, domain invariant text features and task-specific heterogeneous sparse features to obtain the representations of query and item. Additionally, samples from multiple search and recommendation scenarios are trained jointly with Domain Adaptive Multi-Task module to obtain the multi-domain foundation model. We apply the S\&R Multi-Domain foundation model to cold start scenarios in the pretrain-finetune manner, which achieves better performance than other SOTA transfer learning methods. The S\&R Multi-Domain Foundation model has been successfully deployed in Alipay Mobile Application's online services, such as content query recommendation and service card recommendation, etc.
AntM$^{2}$C: A Large Scale Dataset For Multi-Scenario Multi-Modal CTR Prediction
Aug 31, 2023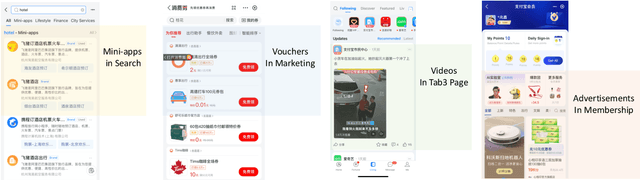
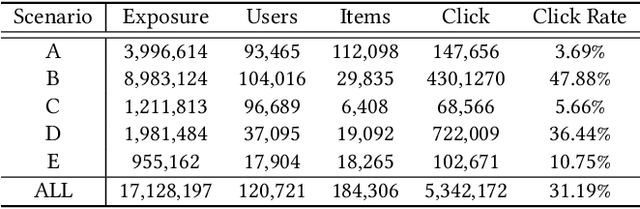
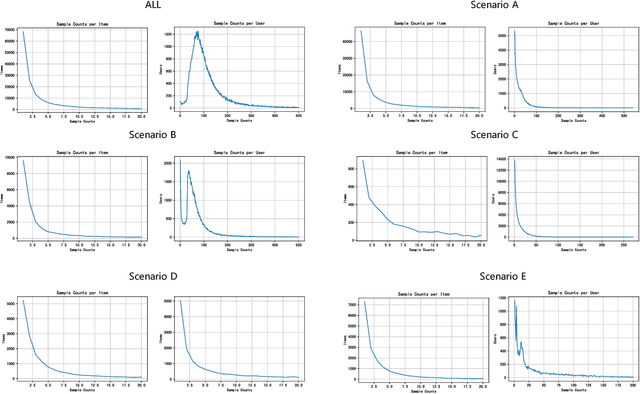
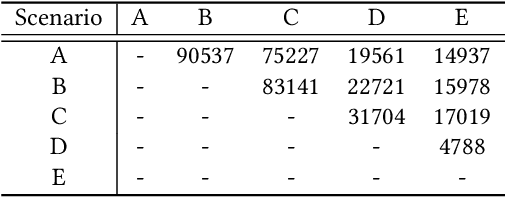
Click-through rate (CTR) prediction is a crucial issue in recommendation systems. There has been an emergence of various public CTR datasets. However, existing datasets primarily suffer from the following limitations. Firstly, users generally click different types of items from multiple scenarios, and modeling from multiple scenarios can provide a more comprehensive understanding of users. Existing datasets only include data for the same type of items from a single scenario. Secondly, multi-modal features are essential in multi-scenario prediction as they address the issue of inconsistent ID encoding between different scenarios. The existing datasets are based on ID features and lack multi-modal features. Third, a large-scale dataset can provide a more reliable evaluation of models, fully reflecting the performance differences between models. The scale of existing datasets is around 100 million, which is relatively small compared to the real-world CTR prediction. To address these limitations, we propose AntM$^{2}$C, a Multi-Scenario Multi-Modal CTR dataset based on industrial data from Alipay. Specifically, AntM$^{2}$C provides the following advantages: 1) It covers CTR data of 5 different types of items, providing insights into the preferences of users for different items, including advertisements, vouchers, mini-programs, contents, and videos. 2) Apart from ID-based features, AntM$^{2}$C also provides 2 multi-modal features, raw text and image features, which can effectively establish connections between items with different IDs. 3) AntM$^{2}$C provides 1 billion CTR data with 200 features, including 200 million users and 6 million items. It is currently the largest-scale CTR dataset available. Based on AntM$^{2}$C, we construct several typical CTR tasks and provide comparisons with baseline methods. The dataset homepage is available at https://www.atecup.cn/home.
Harnessing the Power of David against Goliath: Exploring Instruction Data Generation without Using Closed-Source Models
Aug 24, 2023


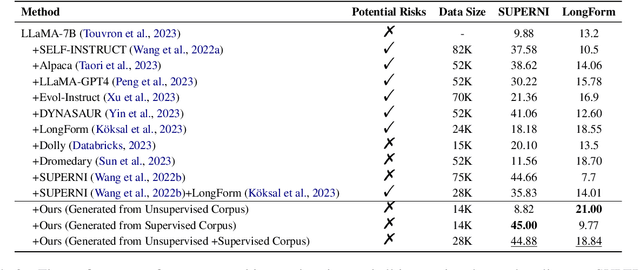
Instruction tuning is instrumental in enabling Large Language Models~(LLMs) to follow user instructions to complete various open-domain tasks. The success of instruction tuning depends on the availability of high-quality instruction data. Owing to the exorbitant cost and substandard quality of human annotation, recent works have been deeply engaged in the exploration of the utilization of powerful closed-source models to generate instruction data automatically. However, these methods carry potential risks arising from the usage requirements of powerful closed-source models, which strictly forbid the utilization of their outputs to develop machine learning models. To deal with this problem, in this work, we explore alternative approaches to generate high-quality instruction data that do not rely on closed-source models. Our exploration includes an investigation of various existing instruction generation methods, culminating in the integration of the most efficient variant with two novel strategies to enhance the quality further. Evaluation results from two benchmarks and the GPT-4 model demonstrate the effectiveness of our generated instruction data, which can outperform Alpaca, a method reliant on closed-source models. We hope that more progress can be achieved in generating high-quality instruction data without using closed-source models.
Pre-training with Aspect-Content Text Mutual Prediction for Multi-Aspect Dense Retrieval
Aug 22, 2023Grounded on pre-trained language models (PLMs), dense retrieval has been studied extensively on plain text. In contrast, there has been little research on retrieving data with multiple aspects using dense models. In the scenarios such as product search, the aspect information plays an essential role in relevance matching, e.g., category: Electronics, Computers, and Pet Supplies. A common way of leveraging aspect information for multi-aspect retrieval is to introduce an auxiliary classification objective, i.e., using item contents to predict the annotated value IDs of item aspects. However, by learning the value embeddings from scratch, this approach may not capture the various semantic similarities between the values sufficiently. To address this limitation, we leverage the aspect information as text strings rather than class IDs during pre-training so that their semantic similarities can be naturally captured in the PLMs. To facilitate effective retrieval with the aspect strings, we propose mutual prediction objectives between the text of the item aspect and content. In this way, our model makes more sufficient use of aspect information than conducting undifferentiated masked language modeling (MLM) on the concatenated text of aspects and content. Extensive experiments on two real-world datasets (product and mini-program search) show that our approach can outperform competitive baselines both treating aspect values as classes and conducting the same MLM for aspect and content strings. Code and related dataset will be available at the URL \footnote{https://github.com/sunxiaojie99/ATTEMPT}.
Beyond Semantics: Learning a Behavior Augmented Relevance Model with Self-supervised Learning
Aug 16, 2023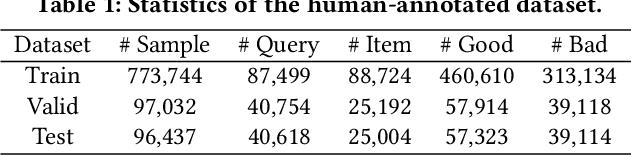
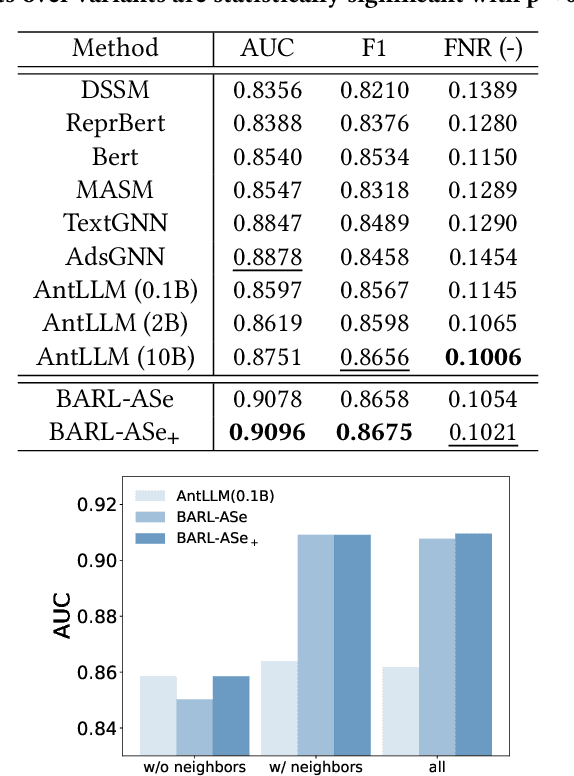
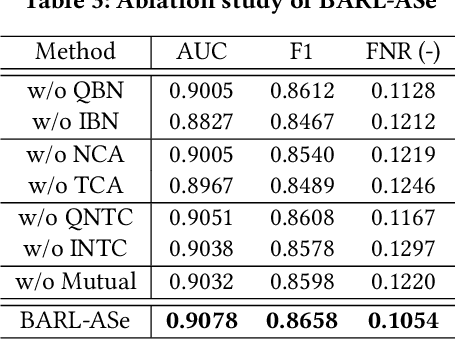
Relevance modeling aims to locate desirable items for corresponding queries, which is crucial for search engines to ensure user experience. Although most conventional approaches address this problem by assessing the semantic similarity between the query and item, pure semantic matching is not everything.
VQGraph: Graph Vector-Quantization for Bridging GNNs and MLPs
Aug 04, 2023



Graph Neural Networks (GNNs) conduct message passing which aggregates local neighbors to update node representations. Such message passing leads to scalability issues in practical latency-constrained applications. To address this issue, recent methods adopt knowledge distillation (KD) to learn computationally-efficient multi-layer perceptron (MLP) by mimicking the output of GNN. However, the existing GNN representation space may not be expressive enough for representing diverse local structures of the underlying graph, which limits the knowledge transfer from GNN to MLP. Here we present a novel framework VQGraph to learn a powerful graph representation space for bridging GNNs and MLPs. We adopt the encoder of a variant of a vector-quantized variational autoencoder (VQ-VAE) as a structure-aware graph tokenizer, which explicitly represents the nodes of diverse local structures as numerous discrete tokens and constitutes a meaningful codebook. Equipped with the learned codebook, we propose a new token-based distillation objective based on soft token assignments to sufficiently transfer the structural knowledge from GNN to MLP. Extensive experiments and analyses demonstrate the strong performance of VQGraph, where we achieve new state-of-the-art performance on GNN-MLP distillation in both transductive and inductive settings across seven graph datasets. We show that VQGraph with better performance infers faster than GNNs by 828x, and also achieves accuracy improvement over GNNs and stand-alone MLPs by 3.90% and 28.05% on average, respectively. Code: https://github.com/YangLing0818/VQGraph.
Individual and Structural Graph Information Bottlenecks for Out-of-Distribution Generalization
Jun 28, 2023



Out-of-distribution (OOD) graph generalization are critical for many real-world applications. Existing methods neglect to discard spurious or noisy features of inputs, which are irrelevant to the label. Besides, they mainly conduct instance-level class-invariant graph learning and fail to utilize the structural class relationships between graph instances. In this work, we endeavor to address these issues in a unified framework, dubbed Individual and Structural Graph Information Bottlenecks (IS-GIB). To remove class spurious feature caused by distribution shifts, we propose Individual Graph Information Bottleneck (I-GIB) which discards irrelevant information by minimizing the mutual information between the input graph and its embeddings. To leverage the structural intra- and inter-domain correlations, we propose Structural Graph Information Bottleneck (S-GIB). Specifically for a batch of graphs with multiple domains, S-GIB first computes the pair-wise input-input, embedding-embedding, and label-label correlations. Then it minimizes the mutual information between input graph and embedding pairs while maximizing the mutual information between embedding and label pairs. The critical insight of S-GIB is to simultaneously discard spurious features and learn invariant features from a high-order perspective by maintaining class relationships under multiple distributional shifts. Notably, we unify the proposed I-GIB and S-GIB to form our complementary framework IS-GIB. Extensive experiments conducted on both node- and graph-level tasks consistently demonstrate the superior generalization ability of IS-GIB. The code is available at https://github.com/YangLing0818/GraphOOD.