 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinkai Xu
Cross-Modal Contextualized Diffusion Models for Text-Guided Visual Generation and Editing
Mar 04, 2024
Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
RealCompo: Dynamic Equilibrium between Realism and Compositionality Improves Text-to-Image Diffusion Models
Feb 20, 2024Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose a new training-free and transferred-friendly text-to-image generation framework, namely RealCompo, which aims to leverage the advantages of text-to-image and layout-to-image models to enhance both realism and compositionality of the generated images. An intuitive and novel balancer is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and layout-to-image models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Code is available at https://github.com/YangLing0818/RealCompo
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
Feb 06, 2024Diffusion models have exhibit exceptional performance in text-to-image generation and editing. However, existing methods often face challenges when handling complex text prompts that involve multiple objects with multiple attributes and relationships. In this paper, we propose a brand new training-free text-to-image generation/editing framework, namely Recaption, Plan and Generate (RPG), harnessing the powerful chain-of-thought reasoning ability of multimodal LLMs to enhance the compositionality of text-to-image diffusion models. Our approach employs the MLLM as a global planner to decompose the process of generating complex images into multiple simpler generation tasks within subregions. We propose complementary regional diffusion to enable region-wise compositional generation. Furthermore, we integrate text-guided image generation and editing within the proposed RPG in a closed-loop fashion, thereby enhancing generalization ability. Extensive experiments demonstrate our RPG outperforms state-of-the-art text-to-image diffusion models, including DALL-E 3 and SDXL, particularly in multi-category object composition and text-image semantic alignment. Notably, our RPG framework exhibits wide compatibility with various MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet). Our code is available at: https://github.com/YangLing0818/RPG-DiffusionMaster
Equivariant Graph Neural Operator for Modeling 3D Dynamics
Jan 19, 2024Modeling the complex three-dimensional (3D) dynamics of relational systems is an important problem in the natural sciences, with applications ranging from molecular simulations to particle mechanics. Machine learning methods have achieved good success by learning graph neural networks to model spatial interactions. However, these approaches do not faithfully capture temporal correlations since they only model next-step predictions. In this work, we propose Equivariant Graph Neural Operator (EGNO), a novel and principled method that directly models dynamics as trajectories instead of just next-step prediction. Different from existing methods, EGNO explicitly learns the temporal evolution of 3D dynamics where we formulate the dynamics as a function over time and learn neural operators to approximate it. To capture the temporal correlations while keeping the intrinsic SE(3)-equivariance, we develop equivariant temporal convolutions parameterized in the Fourier space and build EGNO by stacking the Fourier layers over equivariant networks. EGNO is the first operator learning framework that is capable of modeling solution dynamics functions over time while retaining 3D equivariance. Comprehensive experiments in multiple domains, including particle simulations, human motion capture, and molecular dynamics, demonstrate the significantly superior performance of EGNO against existing methods, thanks to the equivariant temporal modeling.
Equivariant Flow Matching with Hybrid Probability Transport
Dec 12, 2023The generation of 3D molecules requires simultaneously deciding the categorical features~(atom types) and continuous features~(atom coordinates). Deep generative models, especially Diffusion Models (DMs), have demonstrated effectiveness in generating feature-rich geometries. However, existing DMs typically suffer from unstable probability dynamics with inefficient sampling speed. In this paper, we introduce geometric flow matching, which enjoys the advantages of both equivariant modeling and stabilized probability dynamics. More specifically, we propose a hybrid probability path where the coordinates probability path is regularized by an equivariant optimal transport, and the information between different modalities is aligned. Experimentally, the proposed method could consistently achieve better performance on multiple molecule generation benchmarks with 4.75$\times$ speed up of sampling on average.
RetroDiff: Retrosynthesis as Multi-stage Distribution Interpolation
Nov 23, 2023Retrosynthesis poses a fundamental challenge in biopharmaceuticals, aiming to aid chemists in finding appropriate reactant molecules and synthetic pathways given determined product molecules. With the reactant and product represented as 2D graphs, retrosynthesis constitutes a conditional graph-to-graph generative task. Inspired by the recent advancements in discrete diffusion models for graph generation, we introduce Retrosynthesis Diffusion (RetroDiff), a novel diffusion-based method designed to address this problem. However, integrating a diffusion-based graph-to-graph framework while retaining essential chemical reaction template information presents a notable challenge. Our key innovation is to develop a multi-stage diffusion process. In this method, we decompose the retrosynthesis procedure to first sample external groups from the dummy distribution given products and then generate the external bonds to connect the products and generated groups. Interestingly, such a generation process is exactly the reverse of the widely adapted semi-template retrosynthesis procedure, i.e. from reaction center identification to synthon completion, which significantly reduces the error accumulation. Experimental results on the benchmark have demonstrated the superiority of our method over all other semi-template methods.
Scaling Riemannian Diffusion Models
Oct 30, 2023



Riemannian diffusion models draw inspiration from standard Euclidean space diffusion models to learn distributions on general manifolds. Unfortunately, the additional geometric complexity renders the diffusion transition term inexpressible in closed form, so prior methods resort to imprecise approximations of the score matching training objective that degrade performance and preclude applications in high dimensions. In this work, we reexamine these approximations and propose several practical improvements. Our key observation is that most relevant manifolds are symmetric spaces, which are much more amenable to computation. By leveraging and combining various ans\"{a}tze, we can quickly compute relevant quantities to high precision. On low dimensional datasets, our correction produces a noticeable improvement, allowing diffusion to compete with other methods. Additionally, we show that our method enables us to scale to high dimensional tasks on nontrivial manifolds. In particular, we model QCD densities on $SU(n)$ lattices and contrastively learned embeddings on high dimensional hyperspheres.
VQGraph: Graph Vector-Quantization for Bridging GNNs and MLPs
Aug 04, 2023



Graph Neural Networks (GNNs) conduct message passing which aggregates local neighbors to update node representations. Such message passing leads to scalability issues in practical latency-constrained applications. To address this issue, recent methods adopt knowledge distillation (KD) to learn computationally-efficient multi-layer perceptron (MLP) by mimicking the output of GNN. However, the existing GNN representation space may not be expressive enough for representing diverse local structures of the underlying graph, which limits the knowledge transfer from GNN to MLP. Here we present a novel framework VQGraph to learn a powerful graph representation space for bridging GNNs and MLPs. We adopt the encoder of a variant of a vector-quantized variational autoencoder (VQ-VAE) as a structure-aware graph tokenizer, which explicitly represents the nodes of diverse local structures as numerous discrete tokens and constitutes a meaningful codebook. Equipped with the learned codebook, we propose a new token-based distillation objective based on soft token assignments to sufficiently transfer the structural knowledge from GNN to MLP. Extensive experiments and analyses demonstrate the strong performance of VQGraph, where we achieve new state-of-the-art performance on GNN-MLP distillation in both transductive and inductive settings across seven graph datasets. We show that VQGraph with better performance infers faster than GNNs by 828x, and also achieves accuracy improvement over GNNs and stand-alone MLPs by 3.90% and 28.05% on average, respectively. Code: https://github.com/YangLing0818/VQGraph.
Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems
Jul 17, 2023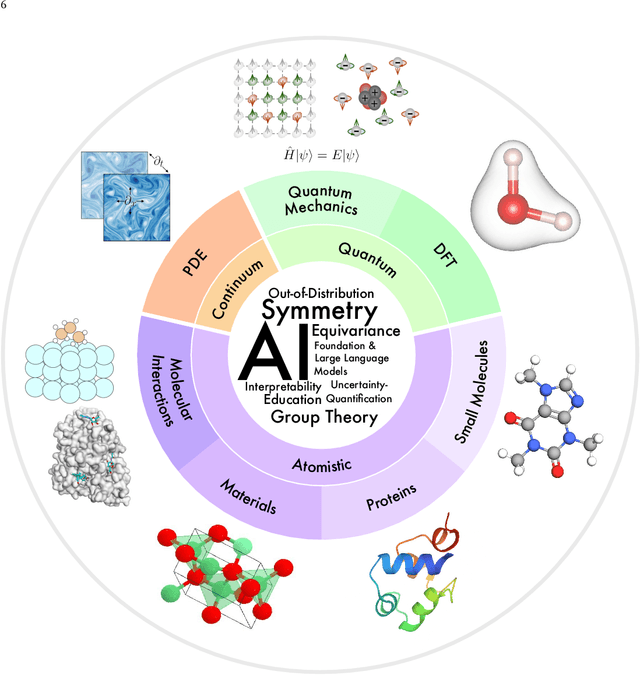

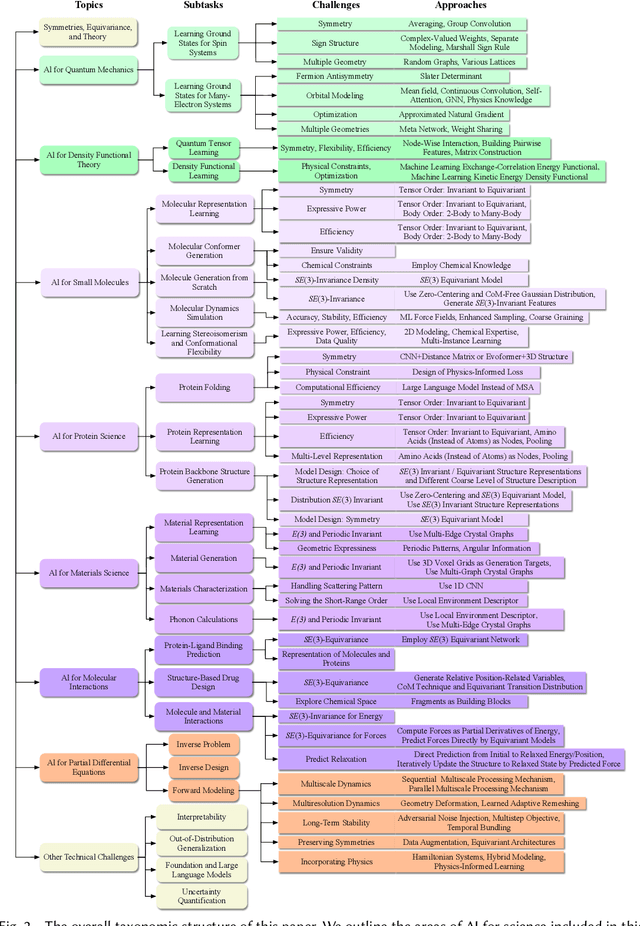
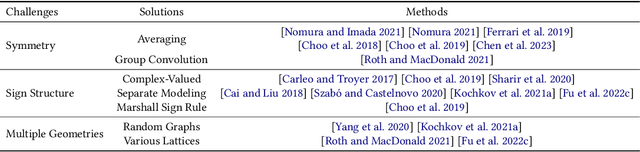
Advances in artificial intelligence (AI) are fueling a new paradigm of discoveries in natural sciences. Today, AI has started to advance natural sciences by improving, accelerating, and enabling our understanding of natural phenomena at a wide range of spatial and temporal scales, giving rise to a new area of research known as AI for science (AI4Science). Being an emerging research paradigm, AI4Science is unique in that it is an enormous and highly interdisciplinary area. Thus, a unified and technical treatment of this field is needed yet challenging. This paper aims to provide a technically thorough account of a subarea of AI4Science; namely, AI for quantum, atomistic, and continuum systems. These areas aim at understanding the physical world from the subatomic (wavefunctions and electron density), atomic (molecules, proteins, materials, and interactions), to macro (fluids, climate, and subsurface) scales and form an important subarea of AI4Science. A unique advantage of focusing on these areas is that they largely share a common set of challenges, thereby allowing a unified and foundational treatment. A key common challenge is how to capture physics first principles, especially symmetries, in natural systems by deep learning methods. We provide an in-depth yet intuitive account of techniques to achieve equivariance to symmetry transformations. We also discuss other common technical challenges, including explainability, out-of-distribution generalization, knowledge transfer with foundation and large language models, and uncertainty quantification. To facilitate learning and education, we provide categorized lists of resources that we found to be useful. We strive to be thorough and unified and hope this initial effort may trigger more community interests and efforts to further advance AI4Science.
MADiff: Offline Multi-agent Learning with Diffusion Models
May 27, 2023
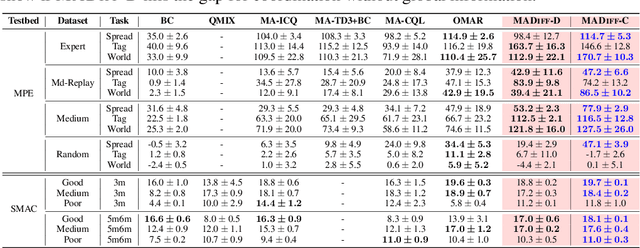
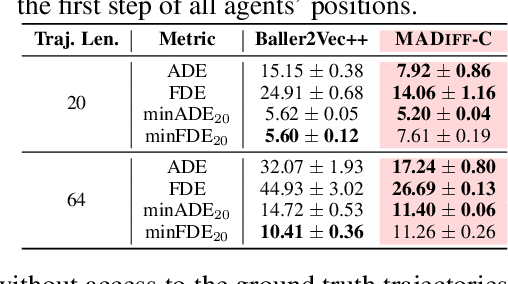
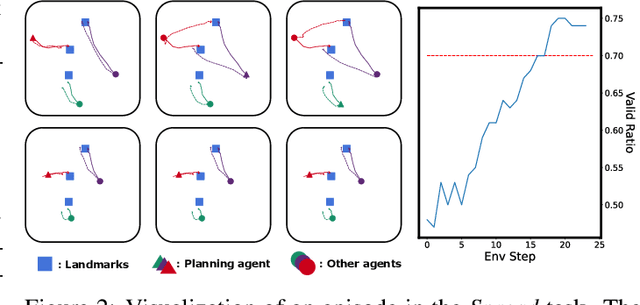
Diffusion model (DM), as a powerful generative model, recently achieved huge success in various scenarios including offline reinforcement learning, where the policy learns to conduct planning by generating trajectory in the online evaluation. However, despite the effectiveness shown for single-agent learning, it remains unclear how DMs can operate in multi-agent problems, where agents can hardly complete teamwork without good coordination by independently modeling each agent's trajectories. In this paper, we propose MADiff, a novel generative multi-agent learning framework to tackle this problem. MADiff is realized with an attention-based diffusion model to model the complex coordination among behaviors of multiple diffusion agents. To the best of our knowledge, MADiff is the first diffusion-based multi-agent offline RL framework, which behaves as both a decentralized policy and a centralized controller, which includes opponent modeling and can be used for multi-agent trajectory prediction. MADiff takes advantage of the powerful generative ability of diffusion while well-suited in modeling complex multi-agent interactions. Our experiments show the superior performance of MADiff compared to baseline algorithms in a range of multi-agent learning tasks.