 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQian Huang
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases
Apr 19, 2024
Answering real-world user queries, such as product search, often requires accurate retrieval of information from semi-structured knowledge bases or databases that involve blend of unstructured (e.g., textual descriptions of products) and structured (e.g., entity relations of products) information. However, previous works have mostly studied textual and relational retrieval tasks as separate topics. To address the gap, we develop STARK, a large-scale Semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. We design a novel pipeline to synthesize natural and realistic user queries that integrate diverse relational information and complex textual properties, as well as their ground-truth answers. Moreover, we rigorously conduct human evaluation to validate the quality of our benchmark, which covers a variety of practical applications, including product recommendations, academic paper searches, and precision medicine inquiries. Our benchmark serves as a comprehensive testbed for evaluating the performance of retrieval systems, with an emphasis on retrieval approaches driven by large language models (LLMs). Our experiments suggest that the STARK datasets present significant challenges to the current retrieval and LLM systems, indicating the demand for building more capable retrieval systems that can handle both textual and relational aspects.
An Improved Artificial Fish Swarm Algorithm for Solving the Problem of Investigation Path Planning
Oct 20, 2023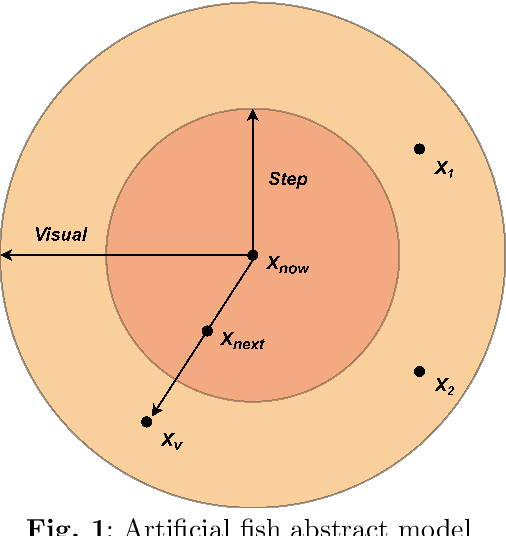

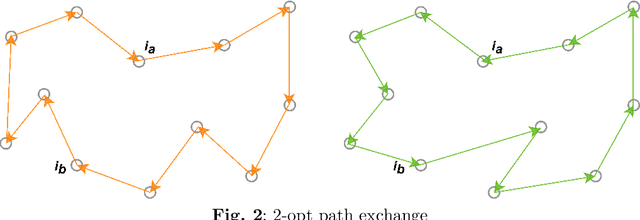

Informationization is a prevailing trend in today's world. The increasing demand for information in decision-making processes poses significant challenges for investigation activities, particularly in terms of effectively allocating limited resources to plan investigation programs. This paper addresses the investigation path planning problem by formulating it as a multi-traveling salesman problem (MTSP). Our objective is to minimize costs, and to achieve this, we propose a chaotic artificial fish swarm algorithm based on multiple population differential evolution (DE-CAFSA). To overcome the limitations of the artificial fish swarm algorithm, such as low optimization accuracy and the inability to consider global and local information, we incorporate adaptive field of view and step size adjustments, replace random behavior with the 2-opt operation, and introduce chaos theory and sub-optimal solutions to enhance optimization accuracy and search performance. Additionally, we integrate the differential evolution algorithm to create a hybrid algorithm that leverages the complementary advantages of both approaches. Experimental results demonstrate that DE-CAFSA outperforms other algorithms on various public datasets of different sizes, as well as showcasing excellent performance on the examples proposed in this study.
Multiscale Motion-Aware and Spatial-Temporal-Channel Contextual Coding Network for Learned Video Compression
Oct 19, 2023
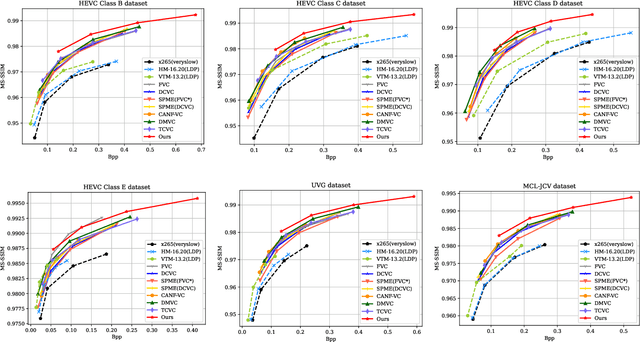


Recently, learned video compression has achieved exciting performance. Following the traditional hybrid prediction coding framework, most learned methods generally adopt the motion estimation motion compensation (MEMC) method to remove inter-frame redundancy. However, inaccurate motion vector (MV) usually lead to the distortion of reconstructed frame. In addition, most approaches ignore the spatial and channel redundancy. To solve above problems, we propose a motion-aware and spatial-temporal-channel contextual coding based video compression network (MASTC-VC), which learns the latent representation and uses variational autoencoders (VAEs) to capture the characteristics of intra-frame pixels and inter-frame motion. Specifically, we design a multiscale motion-aware module (MS-MAM) to estimate spatial-temporal-channel consistent motion vector by utilizing the multiscale motion prediction information in a coarse-to-fine way. On the top of it, we further propose a spatial-temporal-channel contextual module (STCCM), which explores the correlation of latent representation to reduce the bit consumption from spatial, temporal and channel aspects respectively. Comprehensive experiments show that our proposed MASTC-VC is surprior to previous state-of-the-art (SOTA) methods on three public benchmark datasets. More specifically, our method brings average 10.15\% BD-rate savings against H.265/HEVC (HM-16.20) in PSNR metric and average 23.93\% BD-rate savings against H.266/VVC (VTM-13.2) in MS-SSIM metric.
Benchmarking Large Language Models As AI Research Agents
Oct 05, 2023Scientific experimentation involves an iterative process of creating hypotheses, designing experiments, running experiments, and analyzing the results. Can we build AI research agents to perform these long-horizon tasks? To take a step towards building and evaluating research agents on such open-ended decision-making tasks, we focus on the problem of machine learning engineering: given a task description and a dataset, build a high-performing model. In this paper, we propose MLAgentBench, a suite of ML tasks for benchmarking AI research agents. Agents can perform actions like reading/writing files, executing code, and inspecting outputs. With these actions, agents could run experiments, analyze the results, and modify the code of entire machine learning pipelines, such as data processing, architecture, training processes, etc. The benchmark then automatically evaluates the agent's performance objectively over various metrics related to performance and efficiency. We also design an LLM-based research agent to automatically perform experimentation loops in such an environment. Empirically, we find that a GPT-4-based research agent can feasibly build compelling ML models over many tasks in MLAgentBench, displaying highly interpretable plans and actions. However, the success rates vary considerably; they span from almost 90\% on well-established older datasets to as low as 10\% on recent Kaggle Challenges -- unavailable during the LLM model's pretraining -- and even 0\% on newer research challenges like BabyLM. Finally, we identify several key challenges for LLM-based research agents such as long-term planning and hallucination. Our code is released at https://github.com/snap-stanford/MLAgentBench.
DD-GCN: Directed Diffusion Graph Convolutional Network for Skeleton-based Human Action Recognition
Aug 24, 2023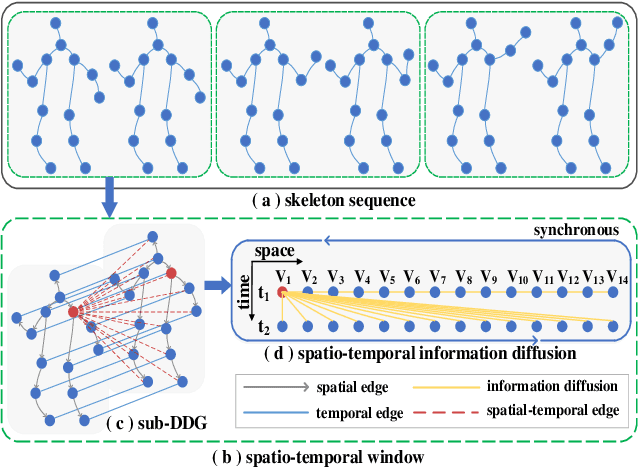
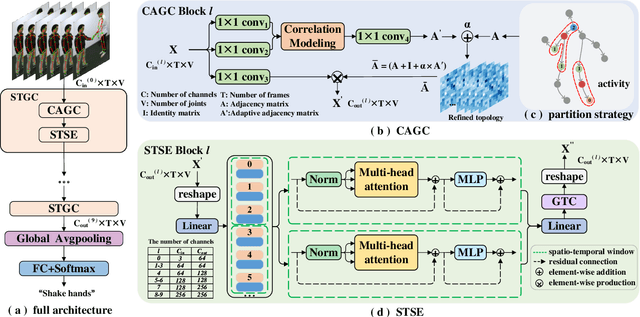

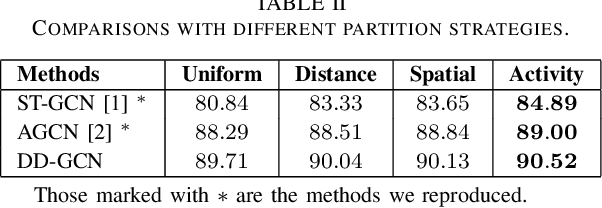
Graph Convolutional Networks (GCNs) have been widely used in skeleton-based human action recognition. In GCN-based methods, the spatio-temporal graph is fundamental for capturing motion patterns. However, existing approaches ignore the physical dependency and synchronized spatio-temporal correlations between joints, which limits the representation capability of GCNs. To solve these problems, we construct the directed diffusion graph for action modeling and introduce the activity partition strategy to optimize the weight sharing mechanism of graph convolution kernels. In addition, we present the spatio-temporal synchronization encoder to embed synchronized spatio-temporal semantics. Finally, we propose Directed Diffusion Graph Convolutional Network (DD-GCN) for action recognition, and the experiments on three public datasets: NTU-RGB+D, NTU-RGB+D 120, and NW-UCLA, demonstrate the state-of-the-art performance of our method.
Enhancing Nucleus Segmentation with HARU-Net: A Hybrid Attention Based Residual U-Blocks Network
Aug 10, 2023
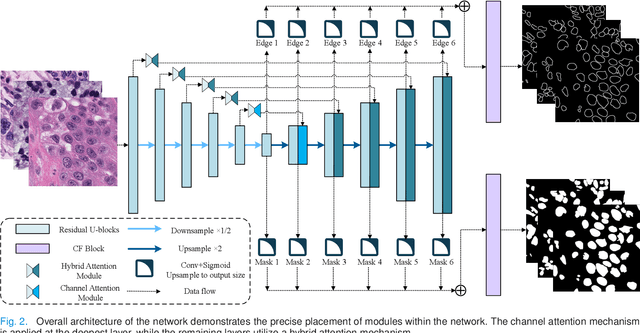

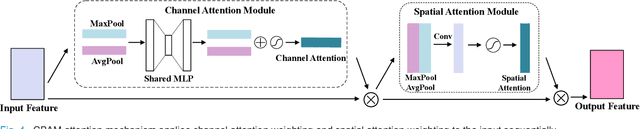
Nucleus image segmentation is a crucial step in the analysis, pathological diagnosis, and classification, which heavily relies on the quality of nucleus segmentation. However, the complexity of issues such as variations in nucleus size, blurred nucleus contours, uneven staining, cell clustering, and overlapping cells poses significant challenges. Current methods for nucleus segmentation primarily rely on nuclear morphology or contour-based approaches. Nuclear morphology-based methods exhibit limited generalization ability and struggle to effectively predict irregular-shaped nuclei, while contour-based extraction methods face challenges in accurately segmenting overlapping nuclei. To address the aforementioned issues, we propose a dual-branch network using hybrid attention based residual U-blocks for nucleus instance segmentation. The network simultaneously predicts target information and target contours. Additionally, we introduce a post-processing method that combines the target information and target contours to distinguish overlapping nuclei and generate an instance segmentation image. Within the network, we propose a context fusion block (CF-block) that effectively extracts and merges contextual information from the network. Extensive quantitative evaluations are conducted to assess the performance of our method. Experimental results demonstrate the superior performance of the proposed method compared to state-of-the-art approaches on the BNS, MoNuSeg, CoNSeg, and CPM-17 datasets.
A Voting-Stacking Ensemble of Inception Networks for Cervical Cytology Classification
Aug 08, 2023



Cervical cancer is one of the most severe diseases threatening women's health. Early detection and diagnosis can significantly reduce cancer risk, in which cervical cytology classification is indispensable. Researchers have recently designed many networks for automated cervical cancer diagnosis, but the limited accuracy and bulky size of these individual models cannot meet practical application needs. To address this issue, we propose a Voting-Stacking ensemble strategy, which employs three Inception networks as base learners and integrates their outputs through a voting ensemble. The samples misclassified by the ensemble model generate a new training set on which a linear classification model is trained as the meta-learner and performs the final predictions. In addition, a multi-level Stacking ensemble framework is designed to improve performance further. The method is evaluated on the SIPakMed, Herlev, and Mendeley datasets, achieving accuracies of 100%, 100%, and 100%, respectively. The experimental results outperform the current state-of-the-art (SOTA) methods, demonstrating its potential for reducing screening workload and helping pathologists detect cervical cancer.
Rethinking Collaborative Perception from the Spatial-Temporal Importance of Semantic Information
Jul 31, 2023Collaboration by the sharing of semantic information is crucial to enable the enhancement of perception capabilities. However, existing collaborative perception methods tend to focus solely on the spatial features of semantic information, while neglecting the importance of the temporal dimension in collaborator selection and semantic information fusion, which instigates performance degradation. In this article, we propose a novel collaborative perception framework, IoSI-CP, which takes into account the importance of semantic information (IoSI) from both temporal and spatial dimensions. Specifically, we develop an IoSI-based collaborator selection method that effectively identifies advantageous collaborators but excludes those that bring negative benefits. Moreover, we present a semantic information fusion algorithm called HPHA (historical prior hybrid attention), which integrates a multi-scale transformer module and a short-term attention module to capture IoSI from spatial and temporal dimensions, and assigns varying weights for efficient aggregation. Extensive experiments on two open datasets demonstrate that our proposed IoSI-CP significantly improves the perception performance compared to state-of-the-art approaches. The code associated with this research is publicly available at https://github.com/huangqzj/IoSI-CP/.
Med-Flamingo: a Multimodal Medical Few-shot Learner
Jul 27, 2023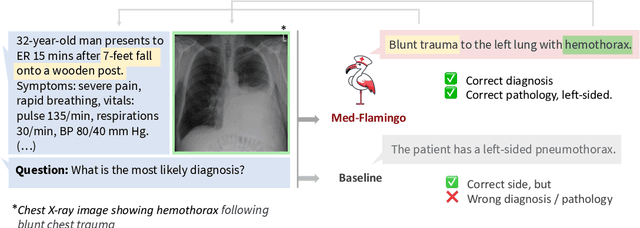

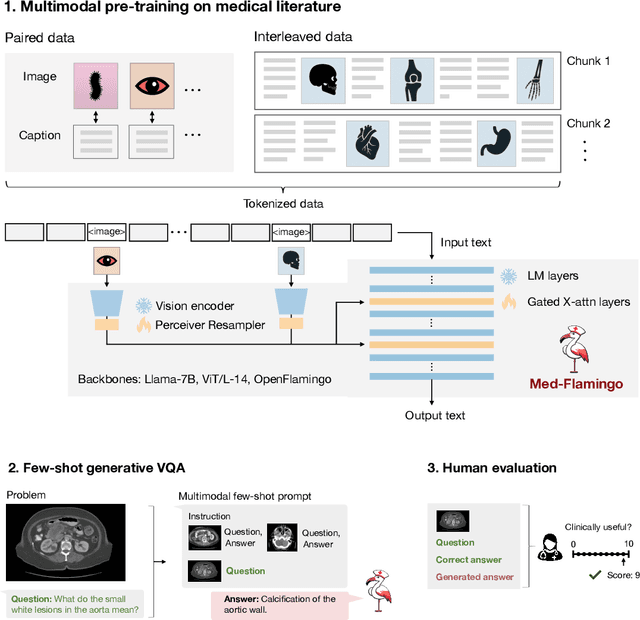
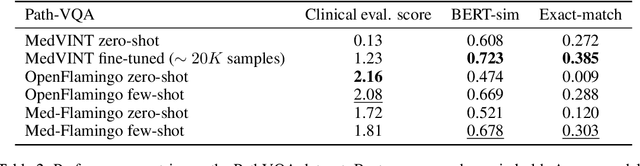
Medicine, by its nature, is a multifaceted domain that requires the synthesis of information across various modalities. Medical generative vision-language models (VLMs) make a first step in this direction and promise many exciting clinical applications. However, existing models typically have to be fine-tuned on sizeable down-stream datasets, which poses a significant limitation as in many medical applications data is scarce, necessitating models that are capable of learning from few examples in real-time. Here we propose Med-Flamingo, a multimodal few-shot learner adapted to the medical domain. Based on OpenFlamingo-9B, we continue pre-training on paired and interleaved medical image-text data from publications and textbooks. Med-Flamingo unlocks few-shot generative medical visual question answering (VQA) abilities, which we evaluate on several datasets including a novel challenging open-ended VQA dataset of visual USMLE-style problems. Furthermore, we conduct the first human evaluation for generative medical VQA where physicians review the problems and blinded generations in an interactive app. Med-Flamingo improves performance in generative medical VQA by up to 20\% in clinician's rating and firstly enables multimodal medical few-shot adaptations, such as rationale generation. We release our model, code, and evaluation app under https://github.com/snap-stanford/med-flamingo.
Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems
Jul 17, 2023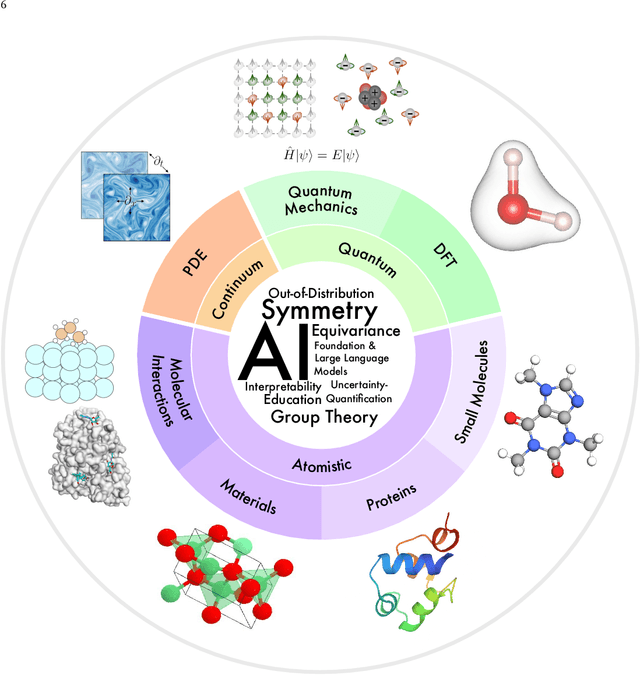

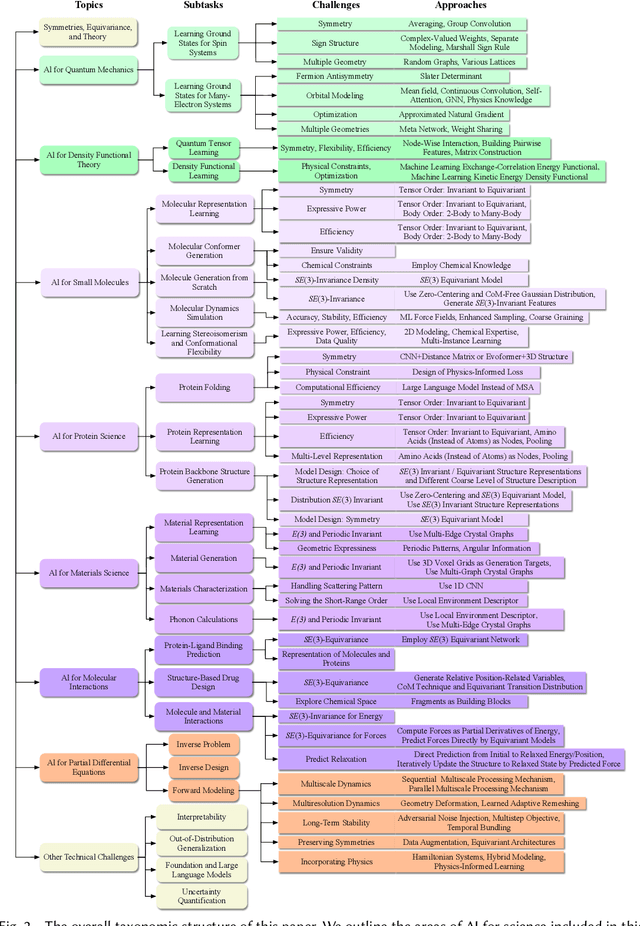
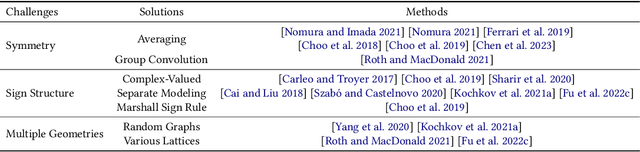
Advances in artificial intelligence (AI) are fueling a new paradigm of discoveries in natural sciences. Today, AI has started to advance natural sciences by improving, accelerating, and enabling our understanding of natural phenomena at a wide range of spatial and temporal scales, giving rise to a new area of research known as AI for science (AI4Science). Being an emerging research paradigm, AI4Science is unique in that it is an enormous and highly interdisciplinary area. Thus, a unified and technical treatment of this field is needed yet challenging. This paper aims to provide a technically thorough account of a subarea of AI4Science; namely, AI for quantum, atomistic, and continuum systems. These areas aim at understanding the physical world from the subatomic (wavefunctions and electron density), atomic (molecules, proteins, materials, and interactions), to macro (fluids, climate, and subsurface) scales and form an important subarea of AI4Science. A unique advantage of focusing on these areas is that they largely share a common set of challenges, thereby allowing a unified and foundational treatment. A key common challenge is how to capture physics first principles, especially symmetries, in natural systems by deep learning methods. We provide an in-depth yet intuitive account of techniques to achieve equivariance to symmetry transformations. We also discuss other common technical challenges, including explainability, out-of-distribution generalization, knowledge transfer with foundation and large language models, and uncertainty quantification. To facilitate learning and education, we provide categorized lists of resources that we found to be useful. We strive to be thorough and unified and hope this initial effort may trigger more community interests and efforts to further advance AI4Science.