 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei-Ying Ma
MolCRAFT: Structure-Based Drug Design in Continuous Parameter Space
Apr 18, 2024
Generative models for structure-based drug design (SBDD) have shown promising results in recent years. Existing works mainly focus on how to generate molecules with higher binding affinity, ignoring the feasibility prerequisites for generated 3D poses and resulting in false positives. We conduct thorough studies on key factors of ill-conformational problems when applying autoregressive methods and diffusion to SBDD, including mode collapse and hybrid continuous-discrete space. In this paper, we introduce \ours, the first SBDD model that operates in the continuous parameter space, together with a novel noise reduced sampling strategy. Empirical results show that our model consistently achieves superior performance in binding affinity with more stable 3D structure, demonstrating our ability to accurately model interatomic interactions. To our best knowledge, MolCRAFT is the first to achieve reference-level Vina Scores (-6.59 kcal/mol), outperforming other strong baselines by a wide margin (-0.84 kcal/mol). Code is available at https://github.com/AlgoMole/MolCRAFT.
Unified Generative Modeling of 3D Molecules via Bayesian Flow Networks
Mar 17, 2024Advanced generative model (e.g., diffusion model) derived from simplified continuity assumptions of data distribution, though showing promising progress, has been difficult to apply directly to geometry generation applications due to the multi-modality and noise-sensitive nature of molecule geometry. This work introduces Geometric Bayesian Flow Networks (GeoBFN), which naturally fits molecule geometry by modeling diverse modalities in the differentiable parameter space of distributions. GeoBFN maintains the SE-(3) invariant density modeling property by incorporating equivariant inter-dependency modeling on parameters of distributions and unifying the probabilistic modeling of different modalities. Through optimized training and sampling techniques, we demonstrate that GeoBFN achieves state-of-the-art performance on multiple 3D molecule generation benchmarks in terms of generation quality (90.87% molecule stability in QM9 and 85.6% atom stability in GEOM-DRUG. GeoBFN can also conduct sampling with any number of steps to reach an optimal trade-off between efficiency and quality (e.g., 20-times speedup without sacrificing performance).
Contextual Molecule Representation Learning from Chemical Reaction Knowledge
Feb 21, 2024In recent years, self-supervised learning has emerged as a powerful tool to harness abundant unlabelled data for representation learning and has been broadly adopted in diverse areas. However, when applied to molecular representation learning (MRL), prevailing techniques such as masked sub-unit reconstruction often fall short, due to the high degree of freedom in the possible combinations of atoms within molecules, which brings insurmountable complexity to the masking-reconstruction paradigm. To tackle this challenge, we introduce REMO, a self-supervised learning framework that takes advantage of well-defined atom-combination rules in common chemistry. Specifically, REMO pre-trains graph/Transformer encoders on 1.7 million known chemical reactions in the literature. We propose two pre-training objectives: Masked Reaction Centre Reconstruction (MRCR) and Reaction Centre Identification (RCI). REMO offers a novel solution to MRL by exploiting the underlying shared patterns in chemical reactions as \textit{context} for pre-training, which effectively infers meaningful representations of common chemistry knowledge. Such contextual representations can then be utilized to support diverse downstream molecular tasks with minimum finetuning, such as affinity prediction and drug-drug interaction prediction. Extensive experimental results on MoleculeACE, ACNet, drug-drug interaction (DDI), and reaction type classification show that across all tested downstream tasks, REMO outperforms the standard baseline of single-molecule masked modeling used in current MRL. Remarkably, REMO is the pioneering deep learning model surpassing fingerprint-based methods in activity cliff benchmarks.
Equivariant Flow Matching with Hybrid Probability Transport
Dec 12, 2023The generation of 3D molecules requires simultaneously deciding the categorical features~(atom types) and continuous features~(atom coordinates). Deep generative models, especially Diffusion Models (DMs), have demonstrated effectiveness in generating feature-rich geometries. However, existing DMs typically suffer from unstable probability dynamics with inefficient sampling speed. In this paper, we introduce geometric flow matching, which enjoys the advantages of both equivariant modeling and stabilized probability dynamics. More specifically, we propose a hybrid probability path where the coordinates probability path is regularized by an equivariant optimal transport, and the information between different modalities is aligned. Experimentally, the proposed method could consistently achieve better performance on multiple molecule generation benchmarks with 4.75$\times$ speed up of sampling on average.
Sliced Denoising: A Physics-Informed Molecular Pre-Training Method
Nov 03, 2023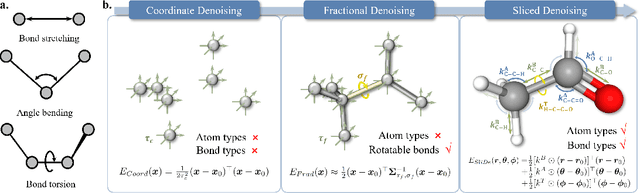

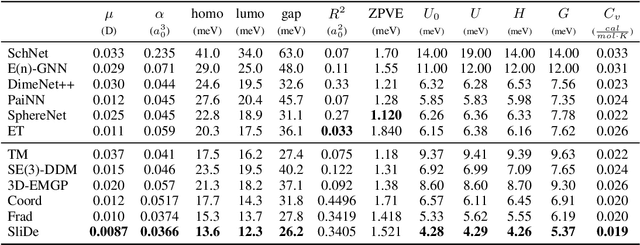
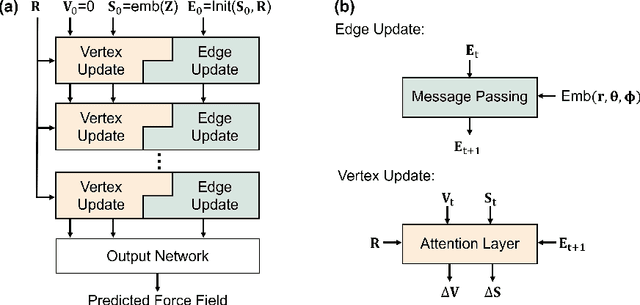
While molecular pre-training has shown great potential in enhancing drug discovery, the lack of a solid physical interpretation in current methods raises concerns about whether the learned representation truly captures the underlying explanatory factors in observed data, ultimately resulting in limited generalization and robustness. Although denoising methods offer a physical interpretation, their accuracy is often compromised by ad-hoc noise design, leading to inaccurate learned force fields. To address this limitation, this paper proposes a new method for molecular pre-training, called sliced denoising (SliDe), which is based on the classical mechanical intramolecular potential theory. SliDe utilizes a novel noise strategy that perturbs bond lengths, angles, and torsion angles to achieve better sampling over conformations. Additionally, it introduces a random slicing approach that circumvents the computationally expensive calculation of the Jacobian matrix, which is otherwise essential for estimating the force field. By aligning with physical principles, SliDe shows a 42\% improvement in the accuracy of estimated force fields compared to current state-of-the-art denoising methods, and thus outperforms traditional baselines on various molecular property prediction tasks.
Fractional Denoising for 3D Molecular Pre-training
Jul 20, 2023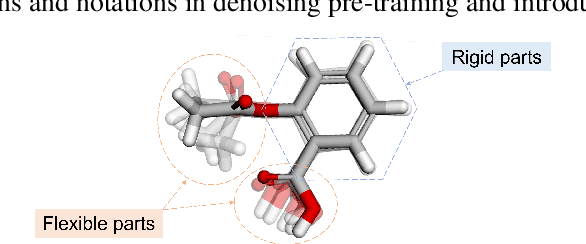

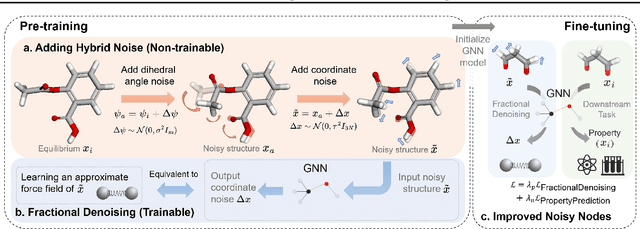
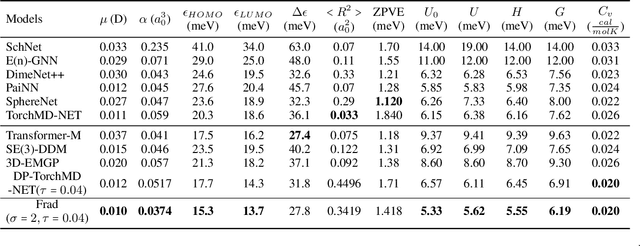
Coordinate denoising is a promising 3D molecular pre-training method, which has achieved remarkable performance in various downstream drug discovery tasks. Theoretically, the objective is equivalent to learning the force field, which is revealed helpful for downstream tasks. Nevertheless, there are two challenges for coordinate denoising to learn an effective force field, i.e. low coverage samples and isotropic force field. The underlying reason is that molecular distributions assumed by existing denoising methods fail to capture the anisotropic characteristic of molecules. To tackle these challenges, we propose a novel hybrid noise strategy, including noises on both dihedral angel and coordinate. However, denoising such hybrid noise in a traditional way is no more equivalent to learning the force field. Through theoretical deductions, we find that the problem is caused by the dependency of the input conformation for covariance. To this end, we propose to decouple the two types of noise and design a novel fractional denoising method (Frad), which only denoises the latter coordinate part. In this way, Frad enjoys both the merits of sampling more low-energy structures and the force field equivalence. Extensive experiments show the effectiveness of Frad in molecular representation, with a new state-of-the-art on 9 out of 12 tasks of QM9 and on 7 out of 8 targets of MD17.
Controllable Person Image Synthesis with Attribute-Decomposed GAN
Apr 18, 2020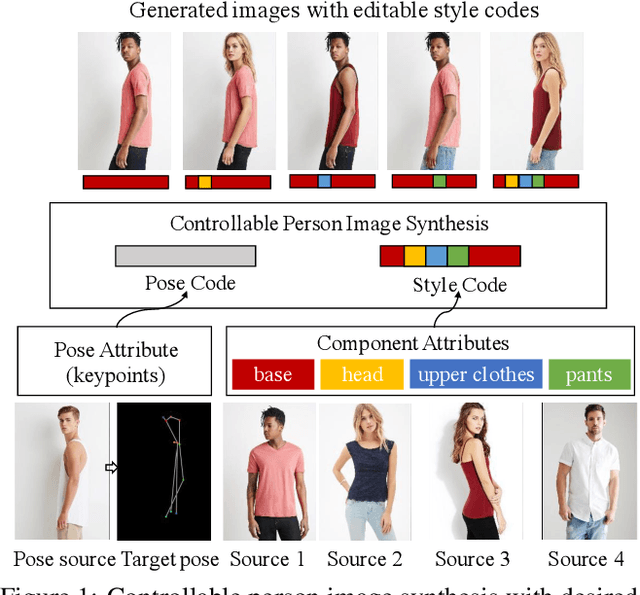
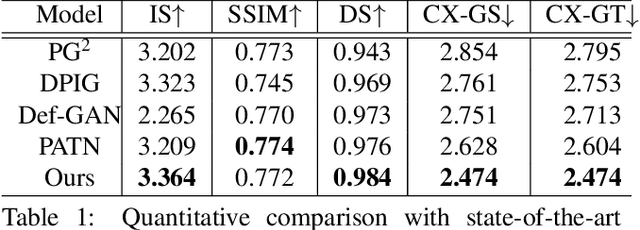
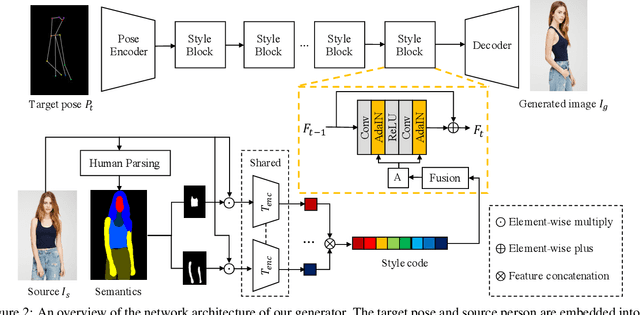
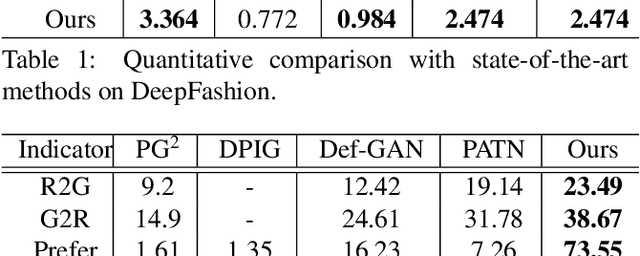
This paper introduces the Attribute-Decomposed GAN, a novel generative model for controllable person image synthesis, which can produce realistic person images with desired human attributes (e.g., pose, head, upper clothes and pants) provided in various source inputs. The core idea of the proposed model is to embed human attributes into the latent space as independent codes and thus achieve flexible and continuous control of attributes via mixing and interpolation operations in explicit style representations. Specifically, a new architecture consisting of two encoding pathways with style block connections is proposed to decompose the original hard mapping into multiple more accessible subtasks. In source pathway, we further extract component layouts with an off-the-shelf human parser and feed them into a shared global texture encoder for decomposed latent codes. This strategy allows for the synthesis of more realistic output images and automatic separation of un-annotated attributes. Experimental results demonstrate the proposed method's superiority over the state of the art in pose transfer and its effectiveness in the brand-new task of component attribute transfer.
Effective Domain Knowledge Transfer with Soft Fine-tuning
Sep 05, 2019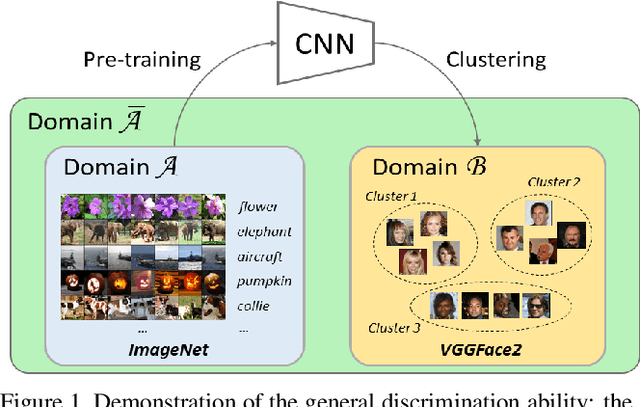

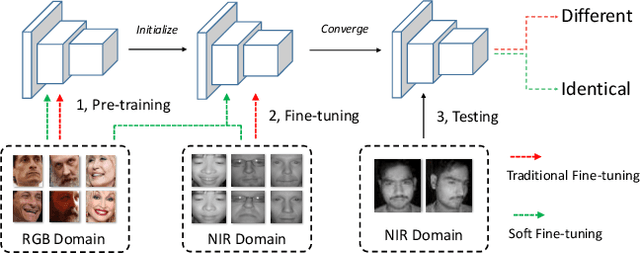

Convolutional neural networks require numerous data for training. Considering the difficulties in data collection and labeling in some specific tasks, existing approaches generally use models pre-trained on a large source domain (e.g. ImageNet), and then fine-tune them on these tasks. However, the datasets from source domain are simply discarded in the fine-tuning process. We argue that the source datasets could be better utilized and benefit fine-tuning. This paper firstly introduces the concept of general discrimination to describe ability of a network to distinguish untrained patterns, and then experimentally demonstrates that general discrimination could potentially enhance the total discrimination ability on target domain. Furthermore, we propose a novel and light-weighted method, namely soft fine-tuning. Unlike traditional fine-tuning which directly replaces optimization objective by a loss function on the target domain, soft fine-tuning effectively keeps general discrimination by holding the previous loss and removes it softly. By doing so, soft fine-tuning improves the robustness of the network to data bias, and meanwhile accelerates the convergence. We evaluate our approach on several visual recognition tasks. Extensive experimental results support that soft fine-tuning provides consistent improvement on all evaluated tasks, and outperforms the state-of-the-art significantly. Codes will be made available to the public.
UniVSE: Robust Visual Semantic Embeddings via Structured Semantic Representations
Apr 28, 2019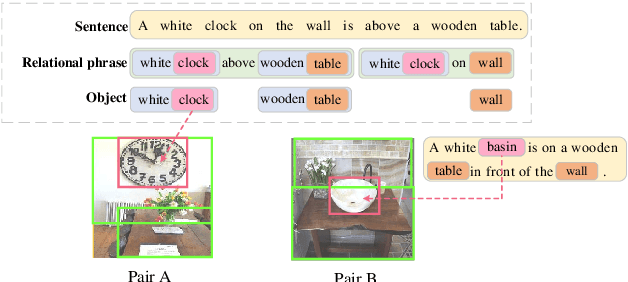

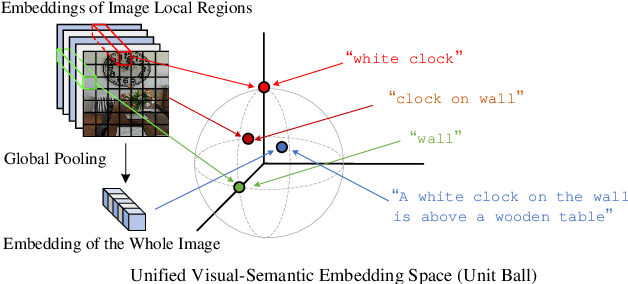
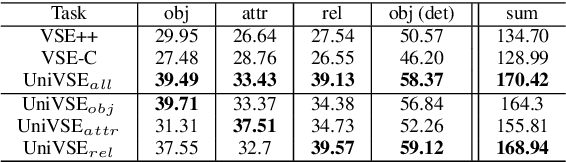
We propose Unified Visual-Semantic Embeddings (UniVSE) for learning a joint space of visual and textual concepts. The space unifies the concepts at different levels, including objects, attributes, relations, and full scenes. A contrastive learning approach is proposed for the fine-grained alignment from only image-caption pairs. Moreover, we present an effective approach for enforcing the coverage of semantic components that appear in the sentence. We demonstrate the robustness of Unified VSE in defending text-domain adversarial attacks on cross-modal retrieval tasks. Such robustness also empowers the use of visual cues to resolve word dependencies in novel sentences.